
7:00 – 4:30 ASRC GEOS
- Read and commented on Shimei’s proposal. It’s interesting to see how she’s weaving all these smaller threads together into one larger narrative. I find that my natural approach is to start with an encompassing vision and figure out how to break it down into its component parts. Which sure seems like stylistic vs. primordial. Interestingly, this implies that stylistic is more integrative? Transdisciplinary, primordial work, because it has no natural home, is more disruptive. It makes me think of this episode of Shock of the New about Paul Cezanne.
- Working on getting BP&S into one file for ArXiv, then back to the dissertation.
- Flailed around with some package mismatches, and had a upper/lowercase (.PNG vs. .png) problem. Submitted!
- Need to ping Antonio about BP&S potential venues
- The Redirect Method uses Adwords targeting tools and curated YouTube videos uploaded by people all around the world to confront online radicalization. It focuses on the slice of ISIS’ audience that is most susceptible to its messaging, and redirects them towards curated YouTube videos debunking ISIS recruiting themes. This open methodology was developed from interviews with ISIS defectors, respects users’ privacy and can be deployed to tackle other types of violent recruiting discourses online.
- I Used Google Ads for Social Engineering. It Worked. (NYTimes)
- Scholar search
- Counter-messages as Prevention or Promotion of Extremism?! The Potential Role of YouTube: Recommendation Algorithms
- In order to serve as an antidote to extremist messages, counter-messages (CM) are placed in the same online environment as extremist content. Often, they are even tagged with similar keywords. Given that automated algorithms may define putative relationships between videos based on mutual topics, CM can appear directly linked to extremist content. This poses severe challenges for prevention programs using CM. This study investigates the extent to which algorithms influence the interrelatedness of counter- and extremist messages. By means of two exemplary information network analyses based on YouTube videos of two CM campaigns, we demonstrate that CM are closely—or even directly—connected to extremist content. The results hint at the problematic role of algorithms for prevention campaigns.
- Maybe the Journal of Communication, Human Communications Research, or the Journal of Computer-Mediated Communication would be good targets for BP&S?
- Counter-messages as Prevention or Promotion of Extremism?! The Potential Role of YouTube: Recommendation Algorithms
- Pushed TimeSeriesML to the git repo, so we’re redundently backed up. Did not send data yet
- Starting on the PyBullet tutorial
- Trying to install pybullet.
- Got this error: error: command ‘C:\\Program Files (x86)\\Microsoft Visual Studio 14.0\\VC\\BIN\\x86_amd64\\link.exe’ failed with exit status 1158
- Updating my Visual Studio (suggested here), in the hope that it fixes that. Soooooo Slooooow
- Link needs rc.exe/rc.dll
- Copied the most recent rc.exe and rcdll.dll (from into C:\\Program Files (x86)\\Microsoft Visual Studio 14.0\\VC\\BIN\\x86_amd64\
- Giving up
- Trying to install pybullet.
- Trying Panda3d
- Downloaded and ran the installer. It couldn’t tell that I had Python 3.7.x, but otherwise was fine. Maybe that’s because my Python is on my D: drive?
- Ran:
pip install panda3d==1.10.3
Which worked just fine
- Had to add the D:\Panda3D-1.10.3-x64\bin and D:\Panda3D-1.10.3-x64\panda3d to the path to get all the imports to work right. This could be because I’m using a global, separately installed Python 3.7.x
- Hmmm. Getting ModuleNotFoundError: No module named ‘panda3d.core.Point3’; ‘panda3d.core’ is not a package. The IDE can find it though….
- In a very odd sequence of events, I tried using
- from pandac.PandaModules import Point3, which worked, but gave me a deprecated warning.
- Then, while fooling around, I tried the preferred
- from panda3d.core import Point3, which now works. No idea what fixed it. Here’s the config that I’m using to run:
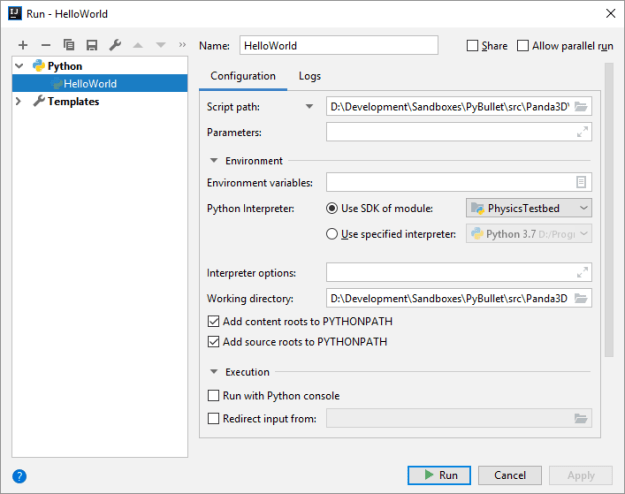
- from panda3d.core import Point3, which now works. No idea what fixed it. Here’s the config that I’m using to run:
- Nice performance, too:

-
- And it has bullet in it, so maybe it will work here?
- Starting on the manual








You must be logged in to post a comment.