
7:00 – 6:00 ASRC MKT
- Starting Bit by Bit
- I realized the hook for the white paper is the military importance of maps. I found A Revolution in Military Cartography?: Europe 1650-1815
- Military cartography is studied in order to approach the role of information in war. This serves as an opportunity to reconsider the Military Revolution and in particular changes in the eighteenth century. Mapping is approached not only in tactical, operational and strategic terms, but also with reference to the mapping of war for public interest. Shifts in the latter reflect changes in the geography of European conflict.
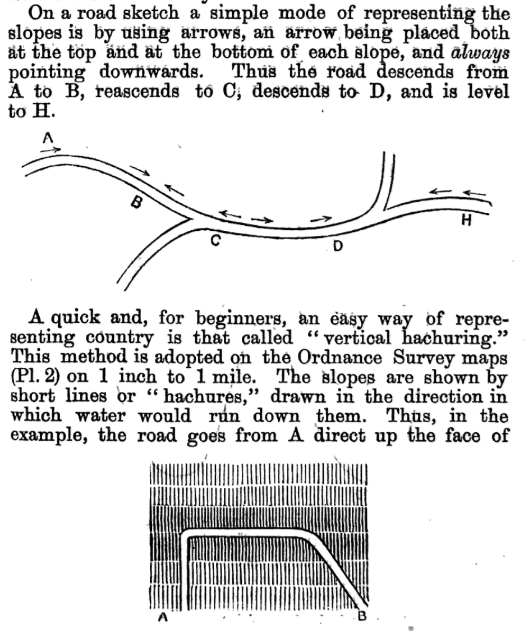
- Reconnoitering sketch from Instructions in the duties of cavalry reconnoitring an enemy; marches; outposts; and reconnaissance of a country; for the use of military cavalry. 1876 (pg 83)
- A rutter is a mariner’s handbook of written sailing directions. Before the advent of nautical charts, rutters were the primary store of geographic information for maritime navigation.
- It was known as a periplus (“sailing-around” book) in classical antiquity and a portolano (“port book”) to medieval Italian sailors in the Mediterranean Sea. Portuguese navigators of the 16th century called it a roteiro, the French a routier, from which the English word “rutter” is derived. In Dutch, it was called a leeskarte (“reading chart”), in German a Seebuch (“sea book”), and in Spanish a derroterro
- Example from ancient Greece:
- From the mouth of the Ister called Psilon to the second mouth is sixty stadia.
- Thence to the mouth called Calon forty stadia.
- From Calon to Naracum, which last is the name of the fourth mouth of the Ister, sixty stadia.
- Hence to the fifth mouth a hundred and twenty stadia.
- Hence to the city of Istria five hundred stadia.
- From Istria to the city of Tomea three hundred stadia.
- From Tomea to the city of Callantra, where there is a port, three hundred stadia
- Battlespace
- A term used to signify a unified military strategy to integrate and combine armed forces for the military theatre of operations, including air, information, land, sea, cyber and space to achieve military goals. It includes the environment, factors, and conditions that must be understood to successfully apply combat power, protect the force, or complete the mission. This includes enemy and friendly armed forces, infrastructure, weather, terrain, and the electromagnetic spectrum within the operational areas and areas of interest
- Cyber-Human Systems (CHS)
- In a world in which computers and networks are increasingly ubiquitous, computing, information, and computation play a central role in how humans work, learn, live, discover, and communicate. Technology is increasingly embedded throughout society, and is becoming commonplace in almost everything we do. The boundaries between humans and technology are shrinking to the point where socio-technical systems are becoming natural extensions to our human experience – second nature, helping us, caring for us, and enhancing us. As a result, computing technologies and human lives, organizations, and societies are co-evolving, transforming each other in the process. Cyber-Human Systems (CHS) research explores potentially transformative and disruptive ideas, novel theories, and technological innovations in computer and information science that accelerate both the creation and understanding of the complex and increasingly coupled relationships between humans and technology with the broad goal of advancing human capabilities: perceptual and cognitive, physical and virtual, social and societal.
- Reworked Section 1 to incorporate all this in a single paragraph
- Long discussion about all of the above with Aaron
- Worked on getting the CoE together by CoB
- Do Diffusion Protocols Govern Cascade Growth?
- Large cascades can develop in online social networks as people share information with one another. Though simple reshare cascades have been studied extensively, the full range of cascading behaviors on social media is much more diverse. Here we study how diffusion protocols, or the social exchanges that enable information transmission, affect cascade growth, analogous to the way communication protocols define how information is transmitted from one point to another. Studying 98 of the largest information cascades on Facebook, we find a wide range of diffusion protocols – from cascading reshares of images, which use a simple protocol of tapping a single button for propagation, to the ALS Ice Bucket Challenge, whose diffusion protocol involved individuals creating and posting a video, and then nominating specific others to do the same. We find recurring classes of diffusion protocols, and identify two key counterbalancing factors in the construction of these protocols, with implications for a cascade’s growth: the effort required to participate in the cascade, and the social cost of staying on the sidelines. Protocols requiring greater individual effort slow down a cascade’s propagation, while those imposing a greater social cost of not participating increase the cascade’s adoption likelihood. The predictability of transmission also varies with protocol. But regardless of mechanism, the cascades in our analysis all have a similar reproduction number (≈ 1.8), meaning that lower rates of exposure can be offset with higher per-exposure rates of adoption. Last, we show how a cascade’s structure can not only differentiate these protocols, but also be modeled through branching processes. Together, these findings provide a framework for understanding how a wide variety of information cascades can achieve substantial adoption across a network.
- Continuing with creating the Simplest LSTM ever
- All work and no play makes jack a dull boy indexes alphabetically as :
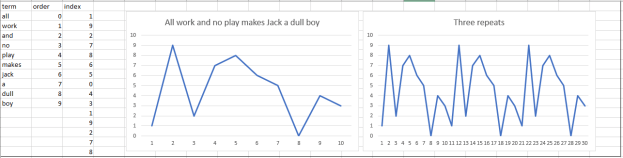
- All work and no play makes jack a dull boy indexes alphabetically as :






You must be logged in to post a comment.