
Scott Klemmer Keynote 2
- What are interesting things that we can do with computers and teaching – 2011
- Objective truth <-> Contextual truth
- Design is in the middle, between objective and subjective truth
- The act of assessing work is a good way to improve understanding
- Problem finding as opposed to problem solving
- “A negotiation around the valuation criteria” Jeff Nicholson
- Negotiations also happen between the creators and the users, particularly in software design. The initial design is the starting point of that journey
- What counts as preferred shifts over time
- Talkabout – The subway model. Pick a time that you’re going to show up, and we’ll put you in a group. Small groups discuss topics.
- Assigning to globally diverse discussion groups increase grades by greater amounts than more local, less diverse groups. Open-ended questions










Participated in the panel on innovation in crowds (invited). There is a video, so I can figure out who to add:
- Christopher Tucci,
- Gianluigi Viscusi (GG)
- Rosy Mondardini
- Thomas Malone
- Joel Chan
- Philip Feldman
Eszter Hargitti – U of Zurich
- Awareness of what is possible
- The ability to create and share content
- Wikigroan?






When Ties Bind And When Ties Divide: The Effects Of Communication Networks On Group Processes And Performance 

- Network structural variance
Enhancing Collective Intelligence of Human-Machine Teams 

- Cognitive and ethnic diversity predict collective intelligence
- Group structure, high level communication and equality of communication
- It’s the quality of the individuals and the quality of the connections
- Coordination technologies – connect humans
Implicit Coordination in Peer Production Networks 


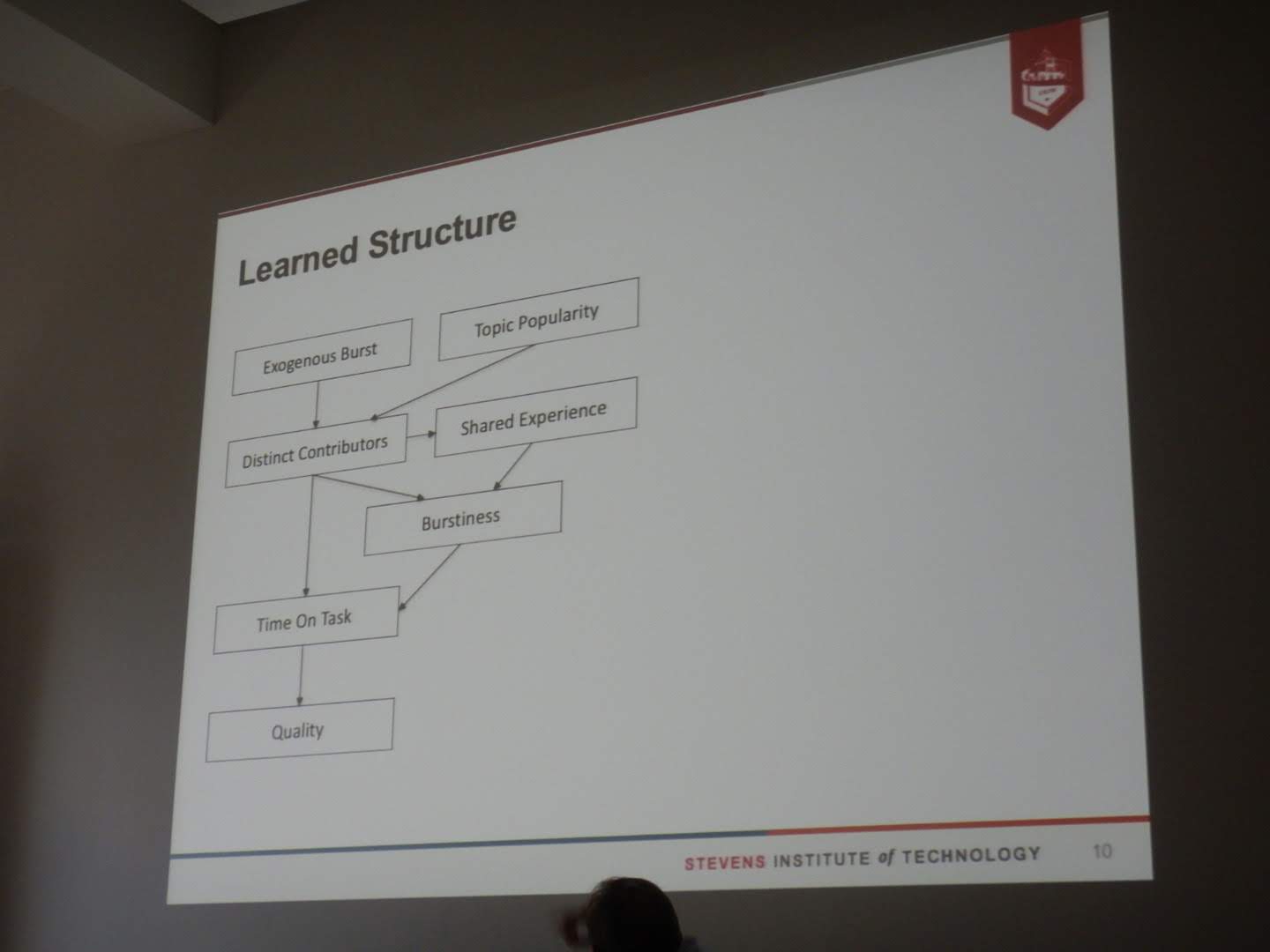
Collective Intelligence Systems for Analogical Search (must read! Joel Chan is at UMD)
- Really interesting, worth reading. Purpose and mechanism may be related to belief spaces. Definitely trainable using NN to find purpose mechanism
Rational Collective Learning in the Laboratory
- Groupthink. as a failure of design
- Randomy constructed groups can make good design choices given failing parts with a history.











You must be logged in to post a comment.