SBIRs
- Continuing with Transformers book
- Quick meeting with Aaron and Rukan to deal with his training problems
- Grabbed some papers for Steve
Book
- Fixing more chapters that I didn’t realize still sounded like a dissertation

SBIRs
Book
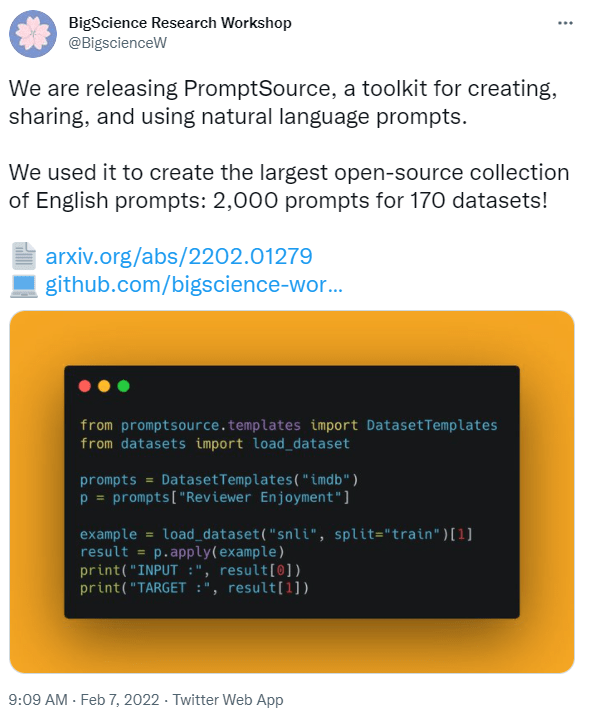
This looks really nice:

Downloading the svn backup – Done!. Going to try to install following these directions: www.if-not-true-then-false.com/2012/svn-subversion-backup-and-restore
SBIRs
GPT Agents
Data Stuff – It’s stuff I made with data! (@erindataviz)
Tasks
SBIRs
GPT Agents

Need to work on the queries a bit to get phrases. Actually not hard, you just have to use escaped quotes ‘\”happy new year\”‘:
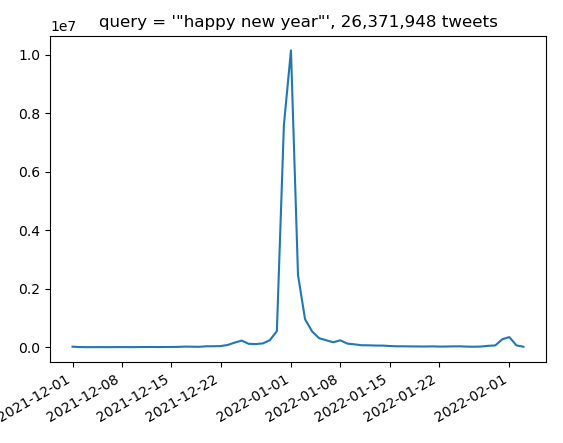
Looking forward to 2.22.22. Almost as exciting as 11.11.11
This IS VERY COOL!! It’s an entire book written using Jupyter Notebooks that you can read on github: GitHub – fastai/fastbook: The fastai book, published as Jupyter Notebooks
GPT Agents.
query = "from:twitterdev"
start_time = "2021-05-01T00:00:00Z"
end_time = "2021-06-01T00:00:00Z"
url = create_counts_url(query, start_time, end_time)
json_response = connect_to_endpoint(url)
print_response("Get counts", json_response)
response:
{
"data": [
{
"end": "2021-05-02T00:00:00.000Z",
"start": "2021-05-01T00:00:00.000Z",
"tweet_count": 0
},
{
"end": "2021-05-13T00:00:00.000Z",
"start": "2021-05-12T00:00:00.000Z",
"tweet_count": 6
},
{
"end": "2021-05-14T00:00:00.000Z",
"start": "2021-05-13T00:00:00.000Z",
"tweet_count": 1
},
{
"end": "2021-05-15T00:00:00.000Z",
"start": "2021-05-14T00:00:00.000Z",
{
"end": "2021-05-21T00:00:00.000Z",
"start": "2021-05-20T00:00:00.000Z",
"tweet_count": 8
},
{
"end": "2021-05-29T00:00:00.000Z",
"start": "2021-05-28T00:00:00.000Z",
"tweet_count": 2
},
{
"end": "2021-06-01T00:00:00.000Z",
"start": "2021-05-31T00:00:00.000Z",
"tweet_count": 0
}
],
"meta": {
"total_tweet_count": 22
}
}
SBIRs

Ack! Dreamhost has deleted my SVN repo. Very bad. Working on getting it back. Other options include RiouxSVN, but it may be moribund. Assembla hosts for $19/month with 500 GB, which is good because I store models. Alternatively, make a svn server, fix the IP address, and have it on Google Drive, OneDrive, or DropBox.
SBIRs
GPT Agents

You must be logged in to post a comment.