Alien Dreams: An Emerging Art Scene
- Ever since OpenAI released the weights and code for their CLIP model, various hackers, artists, researchers, and deep learning enthusiasts have figured out how to utilize CLIP as a an effective “natural language steering wheel” for various generative models, allowing artists to create all sorts of interesting visual art merely by inputting some text – a caption, a poem, a lyric, a word – to one of these models.
Prompting: Better Ways of Using Language Models for NLP Tasks
- So what is a prompt? A prompt is a piece of text inserted in the input examples, so that the original task can be formulated as a (masked) language modeling problem. For example, say we want to classify the sentiment of the movie review “No reason to watch”, we can append a prompt “It was” to the sentence, getting No reason to watch. It was ____”. It is natural to expect a higher probability from the language model to generate “terrible” than “great”. This piece reviews of recent advances in prompts in large language models.
Towards Hate Speech Detection at Large via Deep Generative Modeling (also https://arxiv.org/abs/2005.06370)
- Hate speech detection is a critical problem in social media, being often accused for enabling the spread of hatred and igniting violence. Hate speech detection requires overwhelming computing resources for online monitoring as well as thousands of human experts for daily screening of suspected posts or tweets. Recently, deep learning (DL)-based solutions have been proposed for hate speech detection, using modest-sized datasets of few thousands of sequences. While these methods perform well on the specific datasets, their ability to generalize to new hate speech sequences is limited. Being a data-driven approach, it is known that DL surpasses other methods whenever scale-up in trainset size and diversity is achieved. Therefore, we first present a dataset of 1 million hate and nonhate sequences, produced by a deep generative model. We further utilize the generated data to train a well-studied DL detector, demonstrating significant performance improvements across five hate speech datasets.
The Zipp warranty worked! Dinged rim replaced for free!
SBIR(s)
- Start adding initial text
- 10:00 Tagup?
- 4:00 Tagup
Book
- 4:00 Meeting with Michelle
GPT-Agents
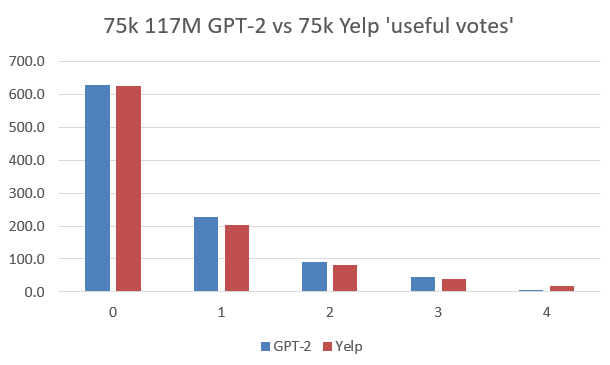
- Write code to do the database pulls to count stars and votes
- Important to avoid NaNs in the dataframe which xlsxwriter can’t handle:
for t in tag_list:
ws = worksheet_dict[t]
l = combined_dict[t]
df = pd.DataFrame(l)
df = df.fillna(0) <------ THIS
stx.write_dataframe(ws, df, row=1, avg=True)
- This looks promising!