
ASRC GOES 7:00 – 5:00
- Dissertation. Working on the differences between designed and evolved systems
- Status report
- Add statistical tests to the evolver.
- based on this post, starting with the scikit-learn resample(). Here are the important bits:
def calc_fitness_stats(self, resample_size:int = 100): boot = resample(self.population, replace=True, n_samples=resample_size, random_state=1) s = pd.Series(boot) conf = st.t.interval(0.95, len(boot)-1, loc=s.mean(), scale= st.sem(boot)) self.meta_info = {'mean':s.mean(), '5_conf':conf[0], '95_conf':conf[1], 'max':s.max(), 'min':s.min()} self.fitness = s.mean() - And the convergence on the test landscape looks good:
- based on this post, starting with the scikit-learn resample(). Here are the important bits:
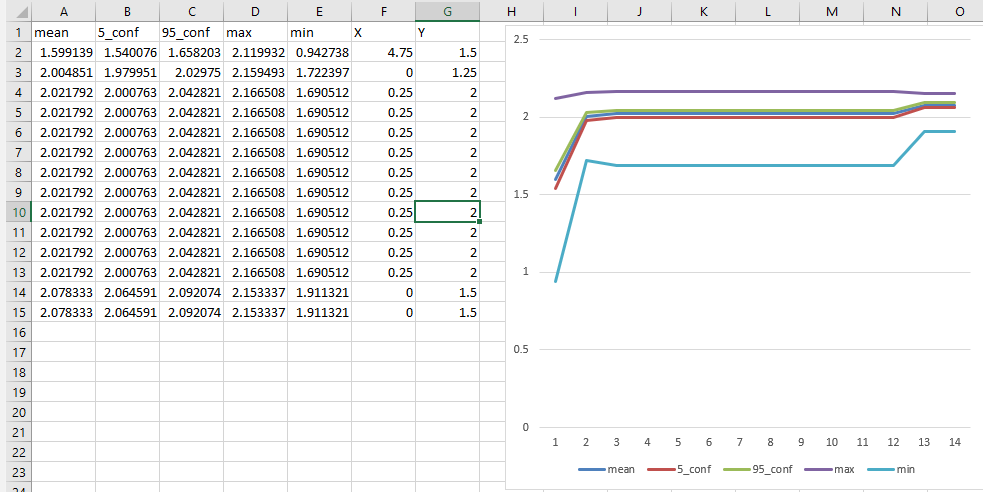
- Added check that the same genome doesn’t get re-run, since it will be run for n times to produce a distribution:
# randomly breed new genomes with a chance of mutation while len(self.current_genome_list) < self.num_genomes: g1i = random.randrange(len(self.best_genome_list)) g2i = random.randrange(len(self.best_genome_list)) g1 = self.best_genome_list[g1i] g2 = self.best_genome_list[g2i] g = self.breed_genomes(g1, g2, crossover_rate, mutation_rate) match = False for gtest in self.all_genomes_list: if g.chromosome_dict == gtest.chromosome_dict: match = True break if not match: self.current_genome_list.append(g) self.all_genomes_list.append(g)
