
7:00 – ASRC GOES
- Well, I’m pretty sure I missed the filing deadline for a defense in February. Looks like April 20 now?
- Dissertation – More simulation. Nope, worked on making sure that I actually have all the paperwork done that will let me defend in February.
- Evolver? Test? Done! It seems to be working. Here’s what I’ve got
- Ground Truth: Because the MLP is trained on a set of mathematical functions, I have a definitive ground truth that I can extend infinitely. It’s simple a set of ten sin(x) waves of varying frequency:
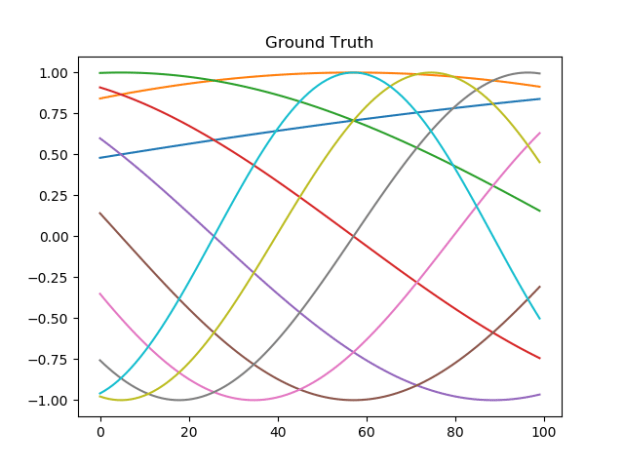
- All Predictions: If you read back through my posts, I’ve discovered how variable a neural network can be when it has the same architecture and training parameters. This variation is based solely on the different random initialization of the weights between layers.
- I’ve put together a genetic-algorithm-based evolver to determine the best hyperparameters, but because of the variation due to initialization, I have to train an ensemble of models and do a statistical analysis just to see if one set of hyperparameters is truly better than another. The reason is easy to see in the following image. What you are looking at is the input vector being run through ten models that are used to calculate the statistical values of the ensemble. You can see that most values are pretty good, some are a bit off, and some are pretty bonkers.
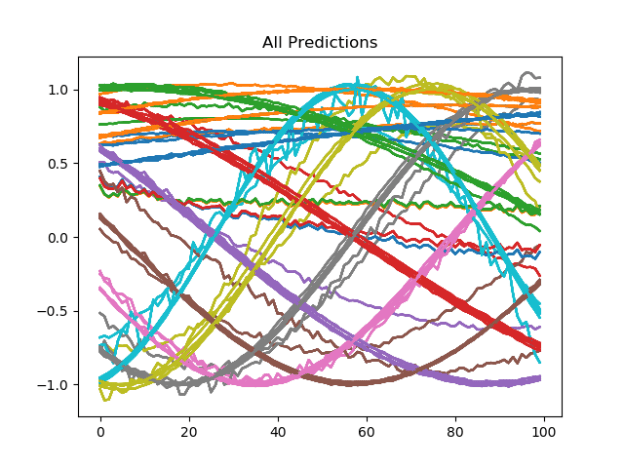
- Ensemble Average: On the whole though, if you take the average of all the ensemble, you get a pretty nice result. And, unlike the single-shot method of training, the likelihood that another ensemble produced with the same architecture will be the same is much higher.

- This is not to say that the model is perfect. The orange curve at the top of the last chart is too low. This model had a mean accuracy of 67%. I’ve just kicked off a much longer run to see if I can find a better architecture using the evolver over 50 generations rather than just 2.
- Ok, it’s now tomorrow, and I have the full run of 50 generation. Things did get better. We end with a higher mean, but we also have a higher variance. This means that it’s possible that the architecture around generation 23 might actually be better:
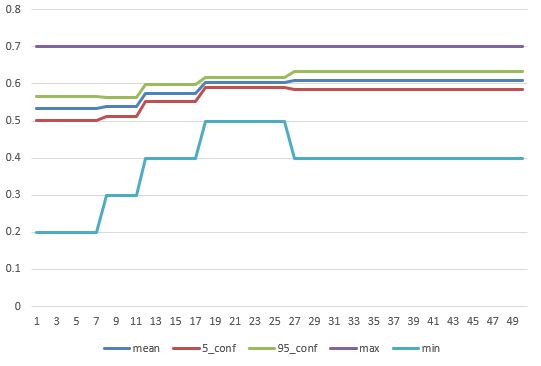
- Because all the values are saved in the spreadsheet, I can try that scenario, but let’s see what the best mean looks like as an ensemble when compared to the early run:

- Wow, that is a lot better. All the models are much closer to each other, and appear to be clustered around the right places. I am genuinely surprised how tidy the clustering is, based on the previous “All Predictions” plot towards the top of this post. On to the ensemble average:

- That is extremely close to the “Ground Truth” chart. The orange line is in the right place, for example. The only error that I can see with a cursory visual inspection is that the height of the olive line is a little lower than it should be.
- Now, I am concerned that there may be two peaks in this fitness landscape that we’re trying to climb. The one that we are looking for is a generalized model that can fit approximate curves. The other case is that the network has simply memorized the curves and will blow up when it sees something different. Let’s test that.
- First, let’s revisit the training set. This model was trained with extremely clean data. The input is a sin function with varying frequencies, and the evaluation data is the same sin function, picking up where we cut off the training data. Here’s an example of the clean data that was used to train the model:

- Now let’s try noising that up, so that the model has to figure out what to do based on data that model has never seen before:

- Let’s see what happened! First, let’s look at all the predictions from the ensemble:

- The first thing that I notice is that it didn’t blow up. Although the paths from each model are somewhat different, each one got all the paths approximately right, and there is no wild deviation. The worst behavior (as usual?) is the orange band, and possibly the green band. But this looks like it should average well. Let’s take a look:
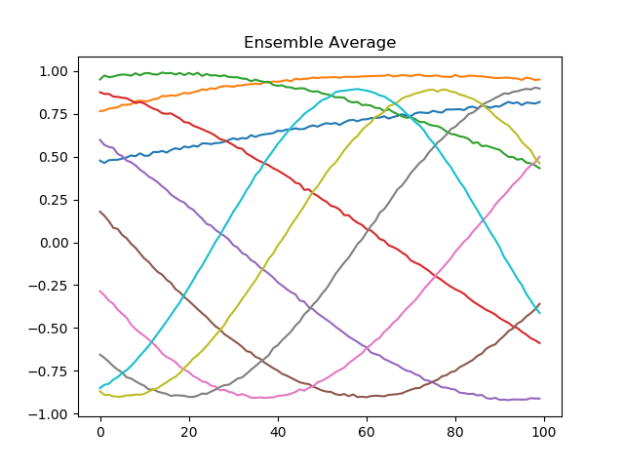
- That seems pretty good. And the orange / green lines are in the right place. It’s the blue, olive, and grey lines that are a little low. Still, pretty happy with this.
- So, ensembles seem to work very well, and make for resilient, predictable behavior in NN architectures. The cost is that there is much more time required to run many, many models through the system.
- Work on AI paper
- Good chat with Aaron – the span of approaches to the “model brittleness problem” can be described using three scenarios:
- Military: Models used in training and at the start of a conflict may not be worth much during hostilities
- Waste, Fraud, and Abuse. Clever criminals can figure out how not to get caught. If they know the models being used, they may be able to thwart them better
- Facial recognition and protest. Currently, protesters in cultures that support large-scale ML-based surveillance try to disguise their identity to the facial recognizers. Developing patterns that are likely to cause errors in recognizers and classifiers may support civil disobedience.
- Good chat with Aaron – the span of approaches to the “model brittleness problem” can be described using three scenarios:
- Solving Rubik’s Cube with a Robot Hand (openAI)
- To overcome this, we developed a new method called Automatic Domain Randomization (ADR), which endlessly generates progressively more difficult environments in simulation. This frees us from having an accurate model of the real world, and enables the transfer of neural networks learned in simulation to be applied to the real world.
