Monday task!!!
Call OPM at 1-888-767-6738 after scrum
And this looks pretty interesting: https://github.com/unitedstates. Found it looking for bill full text to feed into the LMN system. Here’s an example of tagged xml
<?xml version="1.0"?>
<bill bill-stage="Introduced-in-House" dms-id="H7B2411C180AA4EF7AE87C3F9B3844016" public-private="public" bill-type="olc">
<metadata xmlns:dc="http://purl.org/dc/elements/1.1/">
<dublinCore>
<dc:title>113 HR 1237 IH: To authorize and request the President to award the Medal of Honor posthumously to Major Dominic S. Gentile of the United States Army Air Forces for acts of valor during World War II.</dc:title>
<dc:publisher>U.S. House of Representatives</dc:publisher>
<dc:date>2013-03-18</dc:date>
<dc:format>text/xml</dc:format>
<dc:language>EN</dc:language>
<dc:rights>Pursuant to Title 17 Section 105 of the United States Code, this file is not subject to copyright protection and is in the public domain.</dc:rights>
</dublinCore>
</metadata>
<form>
<distribution-code display="yes">I</distribution-code>
<congress>113th CONGRESS</congress>
<session>1st Session</session>
<legis-num>H. R. 1237</legis-num>
<current-chamber>IN THE HOUSE OF REPRESENTATIVES</current-chamber>
<action>
<action-date date="20130318">March 18, 2013</action-date>
<action-desc><sponsor name-id="B001281">Mrs. Beatty</sponsor> introduced the following bill; which was referred to the <committee-name committee-id="HAS00">Committee on Armed Services</committee-name></action-desc>
</action>
<legis-type>A BILL</legis-type>
<official-title>To authorize and request the President to award the Medal of Honor posthumously to Major Dominic S. Gentile of the United States Army Air Forces for acts of valor during World War II.</official-title>
</form>
<legis-body id="HC4FC3A2EC9CD480F8E7100E4CF3C2F3C" style="OLC">
<section id="HED5DF0B8F90849ECB7D6A49028BC38E1" section-type="section-one"><enum>1.</enum><header>Authorization and request for award of Medal of Honor to Dominic S. Gentile for acts of valor during World War II</header>
<subsection id="H21C369FA21D644EB9F38767C54E49A0B"><enum>(a)</enum><header>Findings</header><text display-inline="yes-display-inline">Congress makes the following findings:</text>
<paragraph id="H6A5FBF181F68426CB457AB237F565723"><enum>(1)</enum><text display-inline="yes-display-inline">Major Dominic S. Gentile of the United States Army Air Forces destroyed at least 30 enemy aircraft during World War II, making him one of the highest scoring fighter pilots in American history and earning him the title of <quote>Ace of Aces</quote>.</text></paragraph>
<paragraph id="HF3355B912FA6432295B768BE5B58842A"><enum>(2)</enum><text>Major Gentile was the first American fighter pilot to surpass Captain Eddie Rickenbacker’s WWI record of 26 enemy aircraft destroyed.</text></paragraph>
<paragraph id="H18EE27FA1F7A48CB8AE62301BF0B31ED"><enum>(3)</enum><text>Major Gentile was awarded several medals in recognition of his acts of valor during World War II, including two Distinguished Service Crosses, seven Distinguished Flying Crosses, the Silver Star, the Air Medal, and received similar honors from Great Britain, Italy, Belgium, and Canada.</text></paragraph>
<paragraph id="H2F7E271C44E84E5DBC95C9F58127B93E"><enum>(4)</enum><text display-inline="yes-display-inline">Major Gentile was born in Piqua, Ohio, and died January 23, 1951, after which he was posthumously appointed to the rank of major.</text></paragraph>
<paragraph id="HA6F4601200454270939A016AC9B9F96D"><enum>(5)</enum><text>Major Gentile is buried in Columbus, Ohio. Gentile Air Force Station in Kettering, Ohio, is named in his honor and he was inducted into the National Aviation Hall of Fame in 1995.</text></paragraph></subsection>
<subsection display-inline="no-display-inline" id="H5B70830D32B64B4B858A89AAC16A8A4D"><enum>(b)</enum><header>Authorization</header><text display-inline="yes-display-inline">Notwithstanding the time limitations specified in <external-xref legal-doc="usc" parsable-cite="usc/10/3744">section 3744</external-xref> of title 10, United States Code, or any other time limitation with respect to the awarding of certain medals to persons who served in the Armed Forces, the President is authorized and requested to award the Medal of Honor posthumously under section 3741 of such title to former Major Dominic S. Gentile of the United States Army Air Forces for the acts of valor during World War II described in subsection (c).</text></subsection>
<subsection commented="no" display-inline="no-display-inline" id="H0003A92F45354335B4497C04FE62D068"><enum>(c)</enum><header>Acts of valor described</header><text display-inline="yes-display-inline">The acts of valor referred to in subsection (b) are the actions of then Major Dominic S. Gentile who, as a pilot of a P–51 Mustang in the Army’s 336th Fighter Squadron, Fourth Fighter Group, of the Eighth Air Force in Europe during World War II, distinguished himself conspicuously by gallantry and intrepidity at the risk of his life above and beyond the call of duty by destroying at least 30 enemy aircraft during his service in the United State Army Air Forces.</text></subsection></section>
</legis-body>
</bill>


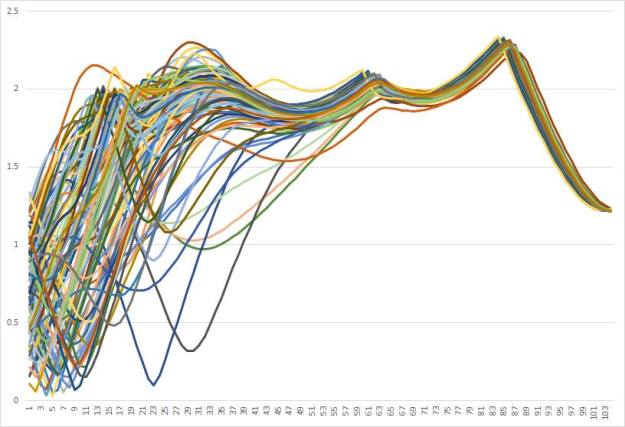 There is are a couple of issues that aren’t treated though – spontaneity and lifespan. In my simulations, spontaneity is approximated by the initial placement and orientation of the explorers. At the very least, I should see how the change to a random walk would affect supergroup formation. The second issue of lifespan is also important:
There is are a couple of issues that aren’t treated though – spontaneity and lifespan. In my simulations, spontaneity is approximated by the initial placement and orientation of the explorers. At the very least, I should see how the change to a random walk would affect supergroup formation. The second issue of lifespan is also important:
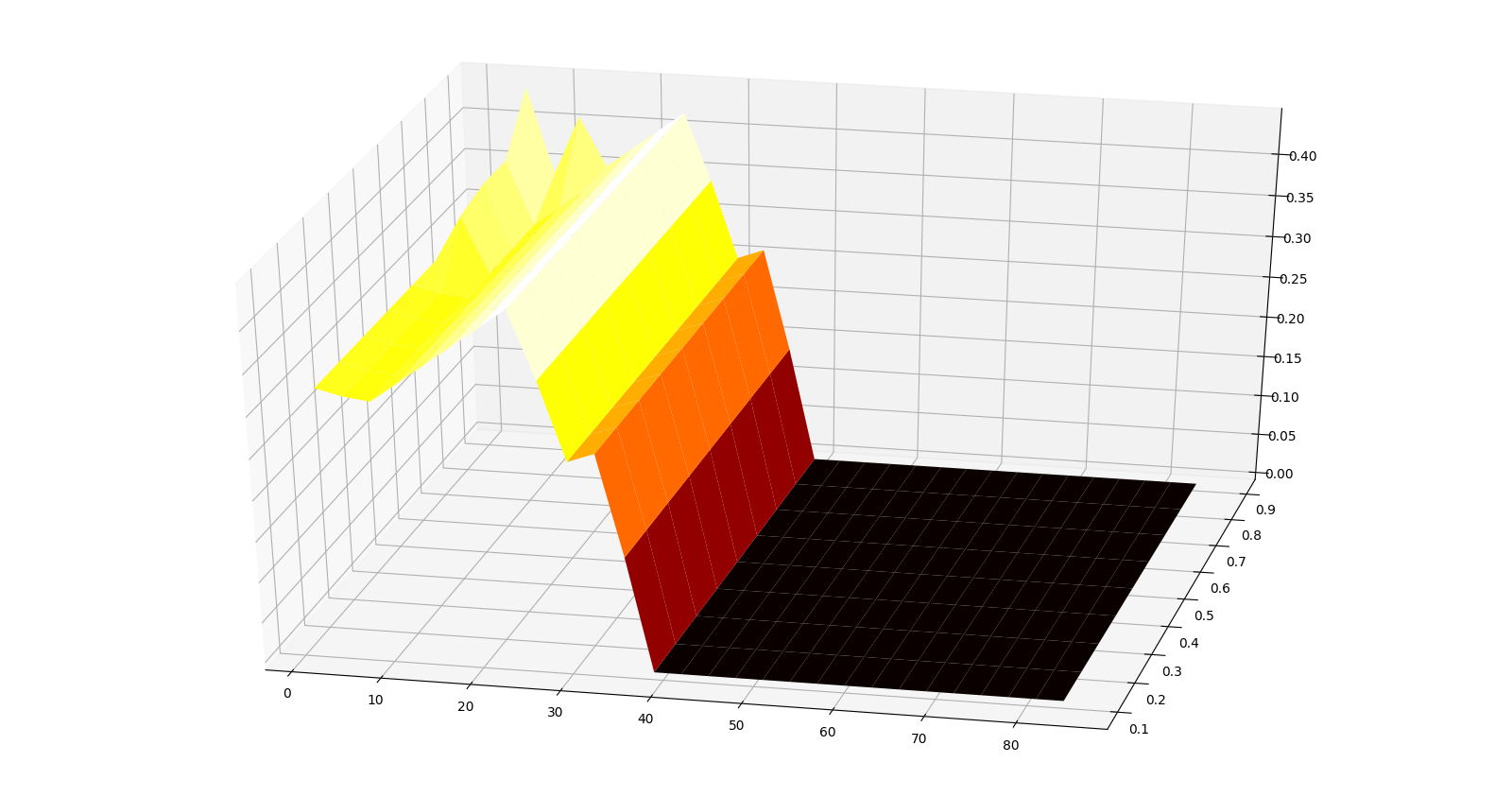


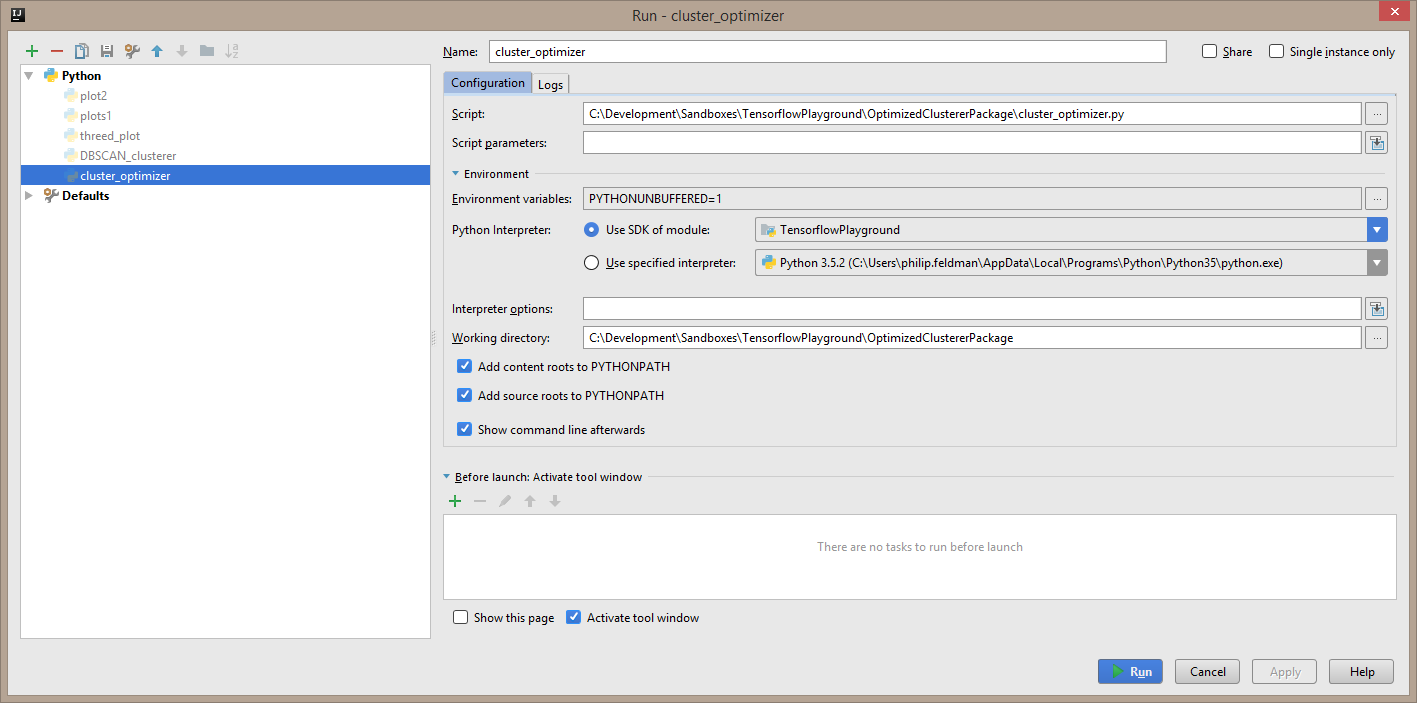
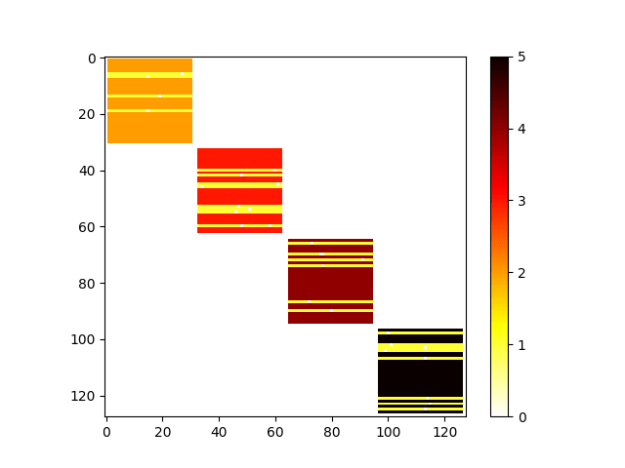
 note that there are at least three pdfs, though the overall best overall value doesn’t change
note that there are at least three pdfs, though the overall best overall value doesn’t change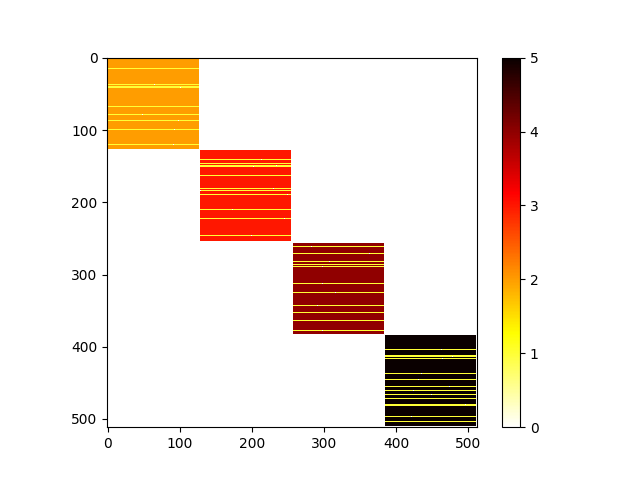

You must be logged in to post a comment.