
7:00 – 4:00 ASRC PhD/NASA
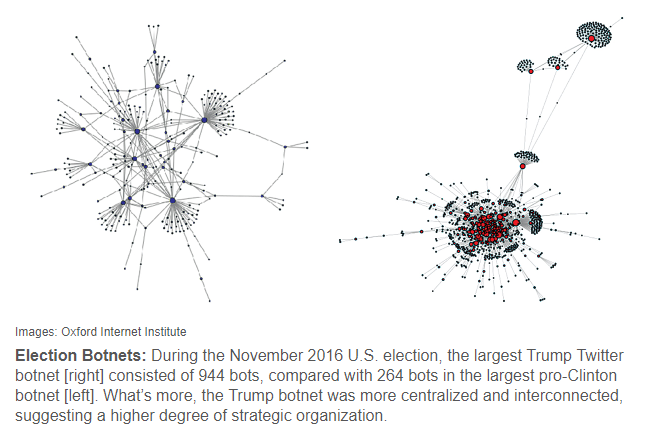
- More adversarial herding: Bots increase exposure to negative and inflammatory content in online social systems
- Social media can deeply influence reality perception, affecting millions of people’s voting behavior. Hence, maneuvering opinion dynamics by disseminating forged content over online ecosystems is an effective pathway for social hacking. We propose a framework for discovering such a potentially dangerous behavior promoted by automatic users, also called “bots,” in online social networks. We provide evidence that social bots target mainly human influencers but generate semantic content depending on the polarized stance of their targets. During the 2017 Catalan referendum, used as a case study, social bots generated and promoted violent content aimed at Independentists, ultimately exacerbating social conflict online. Our results open challenges for detecting and controlling the influence of such content on society.
- Bot detection appendix
- It occurs to me that if bots can be detected, then they can be mapped in aggregate on the belief map. This could show what types of beliefs are being artificially enhanced or otherwise influenced
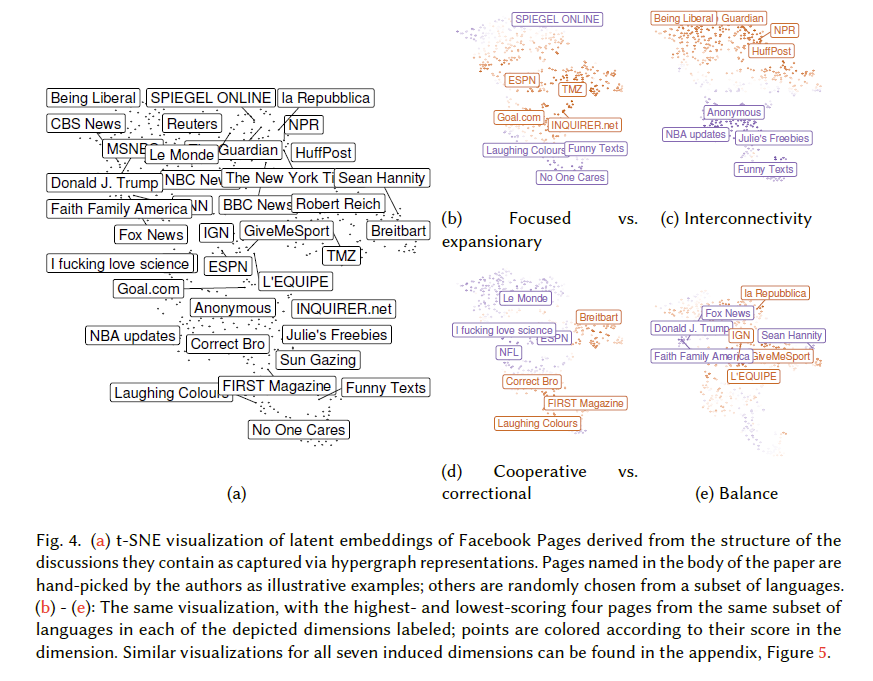
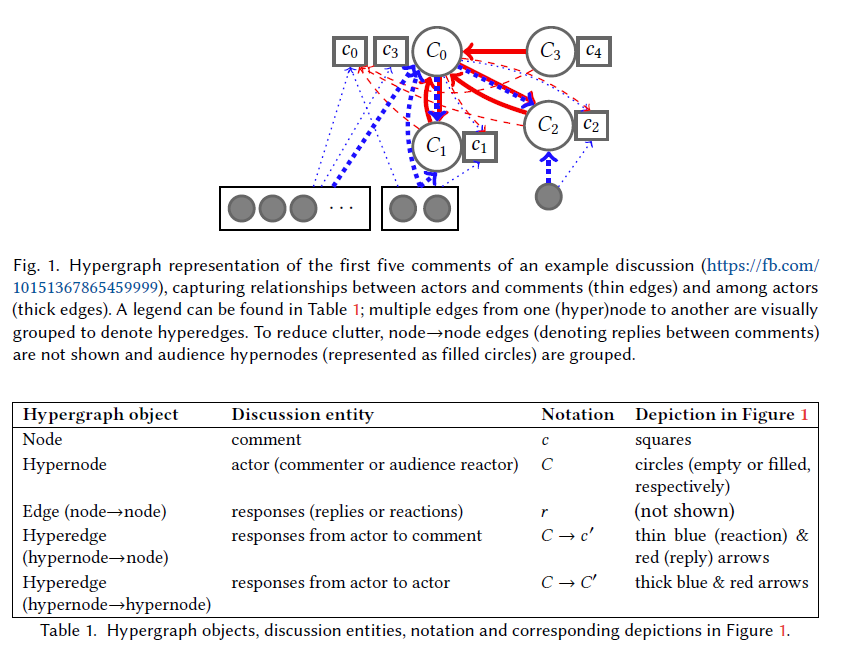
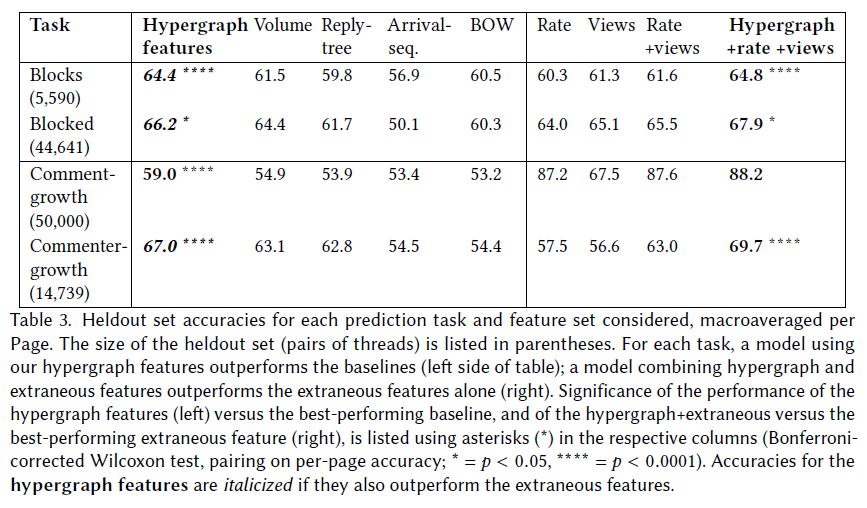
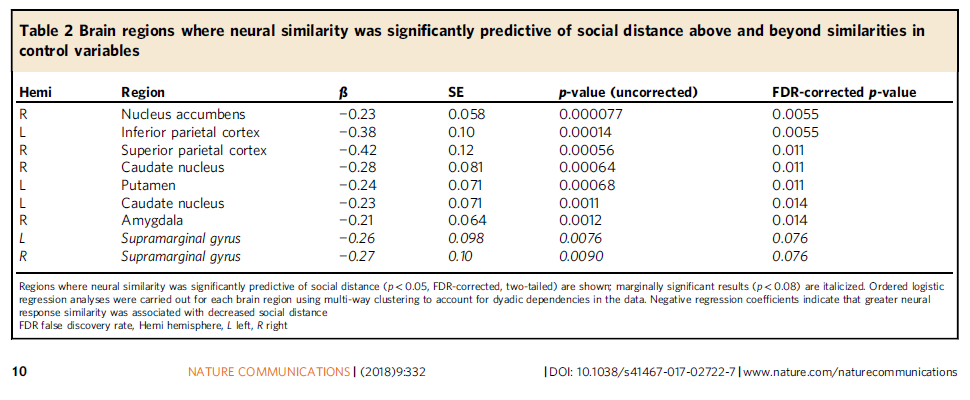
- Migrating Characterizing Online Public Discussions through Patterns of Participant Interactions to Phlog. Done!
- Working my way through Grokking. Today’s progress:
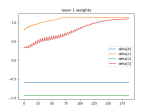
# based on https://github.com/iamtrask/Grokking-Deep-Learning/blob/master/Chapter6%20-%20Intro%20to%20Backpropagation%20-%20Building%20Your%20First%20DEEP%20Neural%20Network.ipynb import numpy as np import matplotlib.pyplot as plt import typing # methods -------------------------------------------- # sets all negative numbers to zero def relu(x: np.array) -> np.array : return (x > 0) * x def relu2deriv(output: float) -> float: return output > 0 # returns 1 for input > 0 # return 0 otherwise def nparray_to_list(vals: np.array) -> typing.List[float]: data = [] for x in np.nditer(vals): data.append(float(x)) return data def plot_mat(title: str, var_name: str, fig_num: int, mat: typing.List[float], transpose: bool = False): f = plt.figure(fig_num) np_mat = np.array(mat) if transpose: np_mat = np_mat.T plt.plot(np_mat) names = [] for i in range(len(np_mat)): names.append("{}[{}]".format(var_name, i)) plt.legend(names) plt.title(title) # variables ------------------------------------------ np.random.seed(1) hidden_size= 4 alpha = 0.2 weights_input_to_1_array = 2 * np.random.random((3, hidden_size)) - 1 weights_1_to_output_array = 2 * np.random.random((hidden_size, 1)) - 1 # the samples. Columns are the things we're sampling streetlights_array = np.array( [[ 1, 0, 1 ], [ 0, 1, 1 ], [ 0, 0, 1 ], [ 1, 1, 1 ] ] ) # The data set we want to map to. Each entry in the array matches the corresponding streetlights_array roe walk_vs_stop_array = np.array([1, 1, 0, 0]).T # and why are we using the transpose here? error_plot_mat = [] # for drawing plots weights_l1_to_output_plot_mat = [] # for drawing plots weights_input_to_l1_plot_mat = [] # for drawing plots iter = 0 max_iter = 1000 epsilon = 0.001 layer_2_error = 2 * epsilon while layer_2_error > epsilon: layer_2_error = 0 for row_index in range(len(streetlights_array)): # input holds one instance of the data set at a time input_layer_array = streetlights_array[row_index:row_index + 1] # layer one holds the results of the NONLINEAR transformation of the input layer's values (multiply by weights and relu) layer_1_array = relu(np.dot(input_layer_array, weights_input_to_1_array)) # output layer takes the LINEAR transformation of the values in layer one and sums them (mult) output_layer = np.dot(layer_1_array, weights_1_to_output_array) # the error is the difference of the output layer and the goal squared goal = walk_vs_stop_array[row_index:row_index + 1] layer_2_error += np.sum((output_layer - goal) ** 2) # compute the amount to adjust the transformation weights for layer one to output layer_1_to_output_delta = (goal - output_layer) # compute the amount to adjust the transformation weights for input to layer one input_to_layer_1_delta= layer_1_to_output_delta.dot(weights_1_to_output_array.T) * relu2deriv(layer_1_array) #Still need to figure out why the transpose, but this is where we incrementally adjust the weights l1t_array = layer_1_array.T ilt_array = input_layer_array.T weights_1_to_output_array += alpha * l1t_array.dot(layer_1_to_output_delta) weights_input_to_1_array += alpha * ilt_array.dot(input_to_layer_1_delta) print("[{}] Error: {:.3f}, L0: {}, L1: {}, L2: {}".format(iter, layer_2_error, input_layer_array, layer_1_array, output_layer)) #print("[{}] Error: {}, Weights: {}".format(iter, total_error, weight_array)) error_plot_mat.append([layer_2_error]) weights_input_to_l1_plot_mat.append(nparray_to_list(weights_input_to_1_array)) weights_l1_to_output_plot_mat.append(nparray_to_list(weights_1_to_output_array)) iter += 1 # stop even if we don't converge if iter > max_iter: break print("\n--------------evaluation") for row_index in range(len(streetlights_array)): input_layer_array = streetlights_array[row_index:row_index + 1] layer_1_array = relu(np.dot(input_layer_array, weights_input_to_1_array)) output_layer = np.dot(layer_1_array, weights_1_to_output_array) print("{} = {:.3f} vs. {}".format(input_layer_array, float(output_layer), walk_vs_stop_array[row_index])) # plots ---------------------------------------------- f1 = plt.figure(1) plt.plot(error_plot_mat) plt.title("error") plt.legend(["layer_2_error"]) plot_mat("input to layer 1 weights", "weight", 2, weights_input_to_l1_plot_mat) plot_mat("layer 1 to output weights", "weight", 3, weights_l1_to_output_plot_mat) plt.show() -












You must be logged in to post a comment.