And that seems to straight up work (assuming that multiple GPUs can be called. Here’s an example of training:
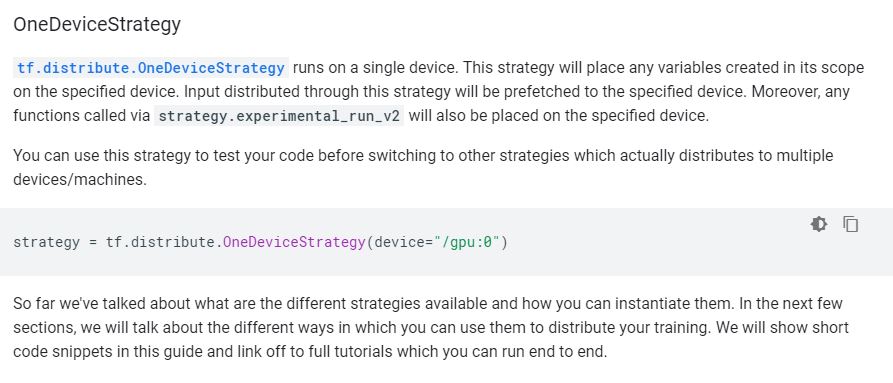
strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0")
with strategy.scope():
model = tf.keras.Sequential()
# Adds a densely-connected layer with 64 units to the model:
model.add(layers.Dense(sequence_length, activation='relu', input_shape=(sequence_length,)))
# Add another:
model.add(layers.Dense(200, activation='relu'))
model.add(layers.Dense(200, activation='relu'))
# Add a layer with 10 output units:
model.add(layers.Dense(sequence_length))
loss_func = tf.keras.losses.MeanSquaredError()
opt_func = tf.keras.optimizers.Adam(0.01)
model.compile(optimizer= opt_func,
loss=loss_func,
metrics=['accuracy'])
noise = 0.0
full_mat, train_mat, test_mat = generate_train_test(num_funcs, rows_per_func, noise)
model.fit(train_mat, test_mat, epochs=70, batch_size=13)
model.evaluate(train_mat, test_mat)
model.save(model_name)
And here’s an example of predicting
strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0")
with strategy.scope():
model = tf.keras.models.load_model(model_name)
full_mat, train_mat, test_mat = generate_train_test(num_funcs, rows_per_func, noise)
predict_mat = model.predict(train_mat)
# Let's try some immediate inference
for i in range(10):
pitch = random.random()/2.0 + 0.5
roll = random.random()/2.0 + 0.5
yaw = random.random()/2.0 + 0.5
inp_vec = np.array([[pitch, roll, yaw]])
eff_mat = model.predict(inp_vec)
print("input: pitch={:.2f}, roll={:.2f}, yaw={:.2f} efficiencies: pitch={:.2f}%, roll={:.2f}%, yaw={:.2f}%".
format(inp_vec[0][0], inp_vec[0][1], inp_vec[0][2], eff_mat[0][0]*100, eff_mat[0][1]*100, eff_mat[0][2]*100))










You must be logged in to post a comment.