Text Embedding Models Contain Bias. Here’s Why That Matters.
- It occurs to me that bias may be a way of measuring societal dimension reduction. Need to read this carefully.
- Neural network models can be quite powerful, effectively helping to identify patterns and uncover structure in a variety of different tasks, from language translation to pathology to playing games. At the same time, neural models (as well as other kinds of machine learning models) can contain problematic biases in many forms. For example, classifiers trained to detect rude, disrespectful, or unreasonable comments may be more likely to flag the sentence “I am gay” than “I am straight” [1]; face classification models may not perform as well for women of color [2]; speech transcription may have higher error rates for African Americans than White Americans [3].
Visual Analytics for Explainable Deep Learning
- Recently, deep learning has been advancing the state of the art in artificial intelligence to a new level, and humans rely on artificial intelligence techniques more than ever. However, even with such unprecedented advancements, the lack of explanation regarding the decisions made by deep learning models and absence of control over their internal processes act as major drawbacks in critical decision-making processes, such as precision medicine and law enforcement. In response, efforts are being made to make deep learning interpretable and controllable by humans. In this paper, we review visual analytics, information visualization, and machine learning perspectives relevant to this aim, and discuss potential challenges and future research directions.
Submitted final version of the CI 2018 paper and also put a copy up on ArXive. Turns out that you can bundle everything into a tar file and upload once.



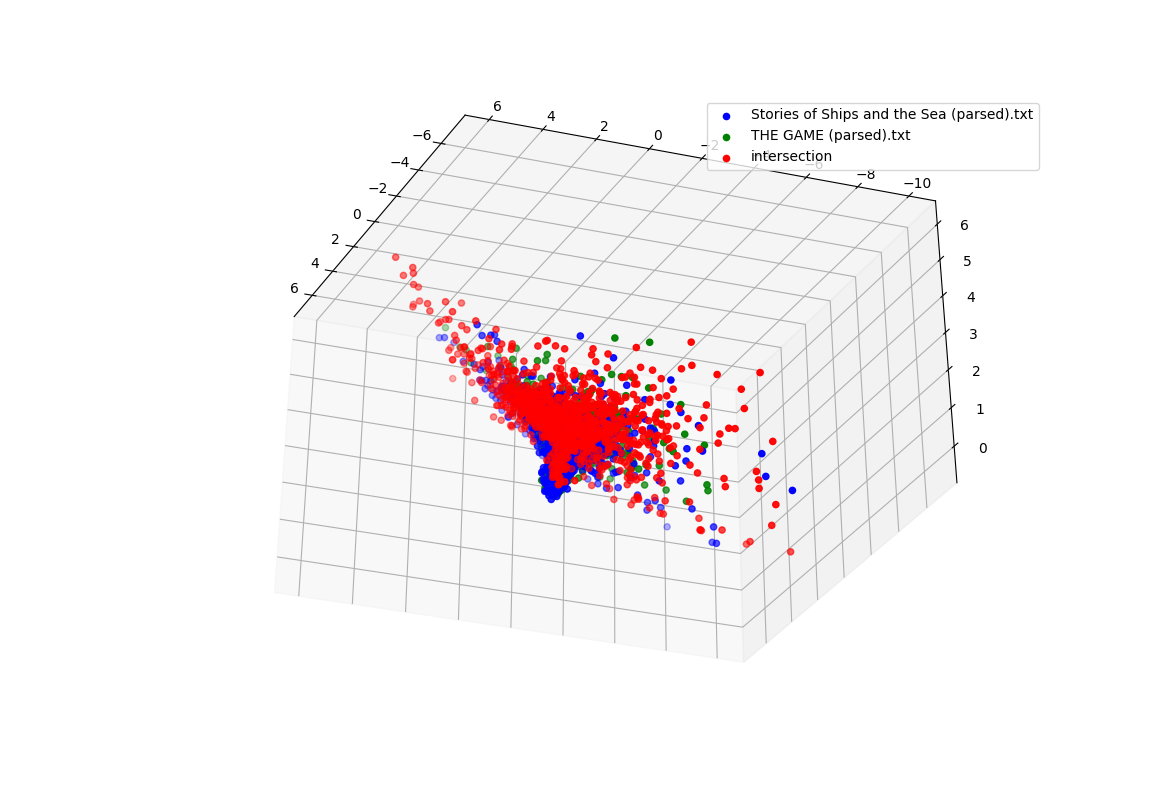
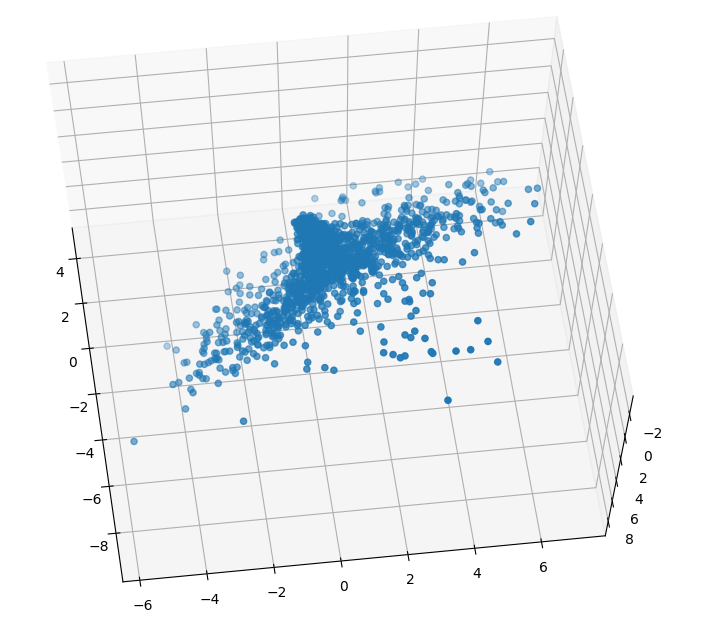
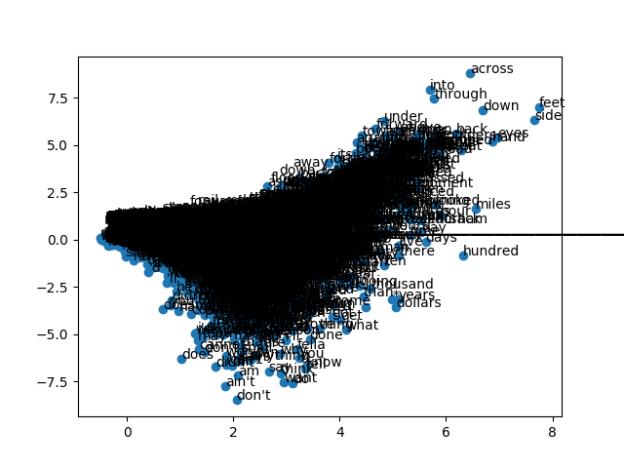 I’ll start working on refining the display, dimensions, and all the other attributes tomorrow.
I’ll start working on refining the display, dimensions, and all the other attributes tomorrow.
 I think it is reasonable to consider this a measure of alignment
I think it is reasonable to consider this a measure of alignment


You must be logged in to post a comment.