
7:00 – ASRC MKT
- Via BBC Business Daily, found this interesting post on diversity injection through lunch table size:
- ‘People Analytics’ Through SuperCharged ID Badges (MIT Sloan)
- Humanyze helps companies make surprising connections about what makes employees effective.
- Data from the lunchroom could inform the boardroom
- Does lunch table size impact workplace productivity? By using analytics and mapping interactions, we found that increasing lunch table size boosted performance by 10%. And the approach has implications reaching far beyond the cafeteria.
- ‘People Analytics’ Through SuperCharged ID Badges (MIT Sloan)
- KQED is playing America Abroad – today on russian disinfo ops:
- Sowing Chaos: Russia’s Disinformation Wars
- Revelations of Russian meddling in the 2016 US presidential election were a shock to Americans. But it wasn’t quite as surprising to people in former Soviet states and the EU. For years they’ve been exposed to Russian disinformation and slanted state media; before that Soviet propaganda filtered into the mainstream. We don’t know how effective Russian information warfare was in swaying the US election. But we do know these tactics have roots going back decades and will most likely be used for years to come. This hour, we’ll hear stories of Russian disinformation and attempts to sow chaos in Europe and the United States. We’ll learn how Russia uses its state-run media to give a platform to conspiracy theorists and how it invites viewers to doubt the accuracy of other news outlets. And we’ll look at the evolution of internet trolling from individuals to large troll farms. And — finally — what can be done to counter all this?
- Sowing Chaos: Russia’s Disinformation Wars
- Some interesting papers on the “Naming Game“, a form of coordination where individuals have to agree on a name for something. This means that there is some kind of dimension reduction involved from all the naming possibilities to the agreed-on name.
- The Grounded Colour Naming Game
- Colour naming games are idealised communicative interactions within a population of artificial agents in which a speaker uses a single colour term to draw the attention of a hearer to a particular object in a shared context. Through a series of such games, a colour lexicon can be developed that is sufficiently shared to allow for successful communication, even when the agents start out without any predefined categories. In previous models of colour naming games, the shared context was typically artificially generated from a set of colour stimuli and both agents in the interaction perceive this environment in an identical way. In this paper, we investigate the dynamics of the colour naming game in a robotic setup in which humanoid robots perceive a set of colourful objects from their own perspective. We compare the resulting colour ontologies to those found in human languages and show how these ontologies reflect the environment in which they were developed.
- Group-size Regulation in Self-Organised Aggregation through the Naming Game
- In this paper, we study the interaction effect between the naming game and one of the simplest, yet most important collective behaviour studied in swarm robotics: self-organised aggregation. This collective behaviour can be seen as the building blocks for many others, as it is required in order to gather robots, unable to sense their global position, at a single location. Achieving this collective behaviour is particularly challenging, especially in environments without landmarks. Here, we augment a classical aggregation algorithm with a naming game model. Experiments reveal that this combination extends the capabilities of the naming game as well as of aggregation: It allows the emergence of more than one word, and allows aggregation to form a controllable number of groups. These results are very promising in the context of collective exploration, as it allows robots to divide the environment in different portions and at the same time give a name to each portion, which can be used for more advanced subsequent collective behaviours.
- The Grounded Colour Naming Game
- More Bit by Bit. Could use some worked examples. Also a login so I’m not nagged to buy a book I own.
- Descriptive and injunctive norms – The transsituational influence of social norms.
- Three studies examined the behavioral implications of a conceptual distinction between 2 types of social norms: descriptive norms, which specify what is typically done in a given setting, and injunctive norms, which specify what is typically approved in society. Using the social norm against littering, injunctive norm salience procedures were more robust in their behavioral impact across situations than were descriptive norm salience procedures. Focusing Ss on the injunctive norm suppressed littering regardless of whether the environment was clean or littered (Study 1) and regardless of whether the environment in which Ss could litter was the same as or different from that in which the norm was evoked (Studies 2 and 3). The impact of focusing Ss on the descriptive norm was much less general. Conceptual implications for a focus theory of normative conduct are discussed along with practical implications for increasing socially desirable behavior.
- Construct validity centers around the match between the data and the theoretical constructs. As discussed in chapter 2, constructs are abstract concepts that social scientists reason about. Unfortunately, these abstract concepts don’t always have clear definitions and measurements.
- Simulation is a way of implementing theoretical constructs that are measurable and testable.
- Descriptive and injunctive norms – The transsituational influence of social norms.
- Hyperparameter Optimization with Keras
- Recognizing images from parts Kaggle winner
- White paper
- Storyboard meeting
- The advanced analytics division(?) needs a modeling and simulation department that builds models that feed ML systems.
- Meeting with Steve Specht – adding geospatial to white paper



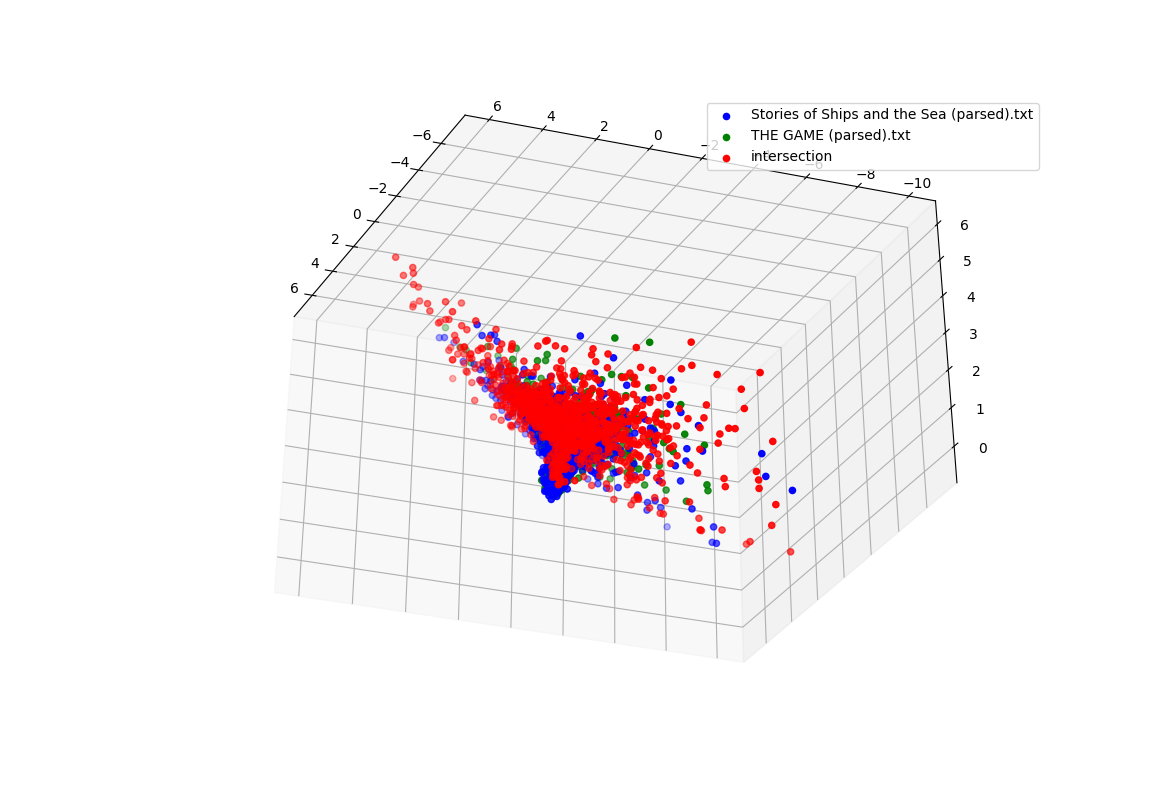
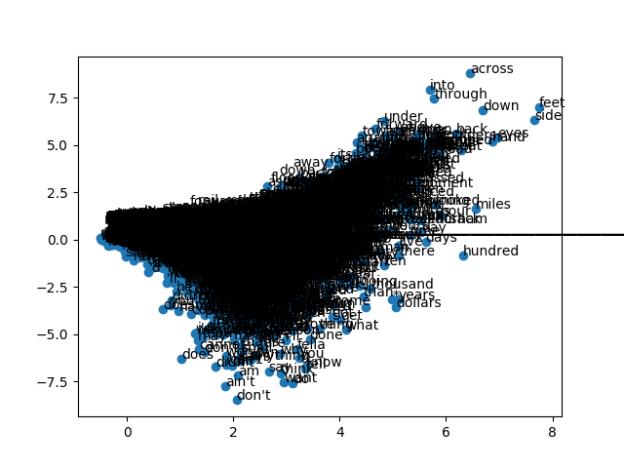 I’ll start working on refining the display, dimensions, and all the other attributes tomorrow.
I’ll start working on refining the display, dimensions, and all the other attributes tomorrow.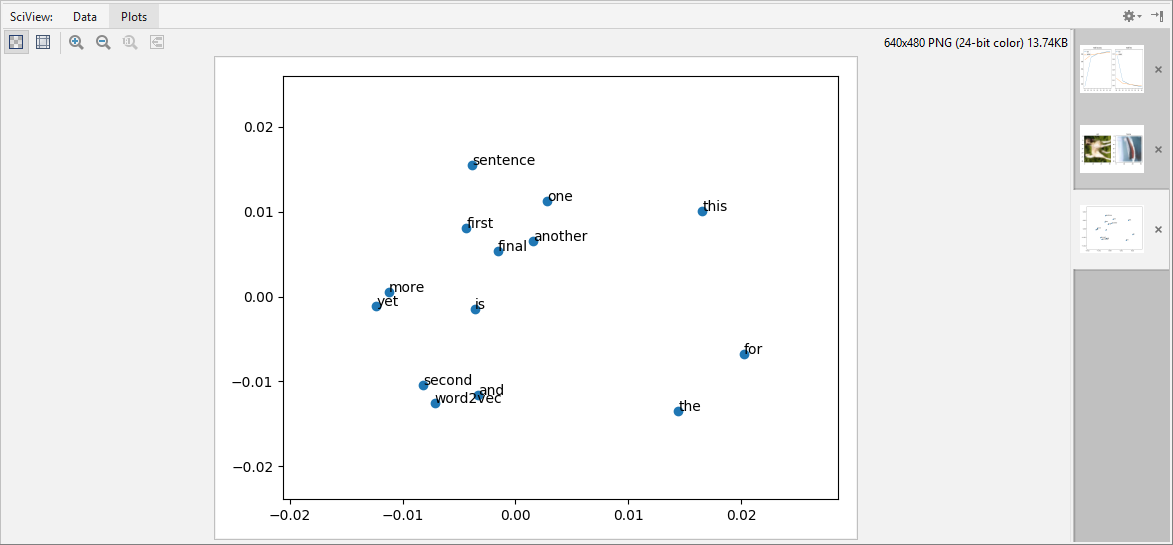

You must be logged in to post a comment.