Vadim is on vacation, so I’m going to focus on my paper. When I get back to the angle interpolation, I need to make sure that I can rotate a point in and plane using the cross product vector + angle technique. I’m pretty sure that having the start vec X stop vec gives me a right hand vector which should have the direction I want to rotate built in. Anyway, that’s your job to figure out, future self!
Talking to Stacy about podcasts,and listened to her suggestion of Unladylike, For some reason, that made me think of the accessibility of the arguments and suggestions for how to make feminism work. There is this paper, Past, Present and Future of User Interface Software Tools, that talks about this idea of threshold (the amount of work to achieve basic competency) and ceiling (the maximum capability of the system). Political systems are a population-scale interface, and these concepts should apply?
GPT-2 Agents
- Add something to graph creation that talks about how the network has a roughly topological relationship to the chessboard. The orientation can be rotated or flipped,and it resembles a rubber sheet, but adjacent parts are generally adjacent.
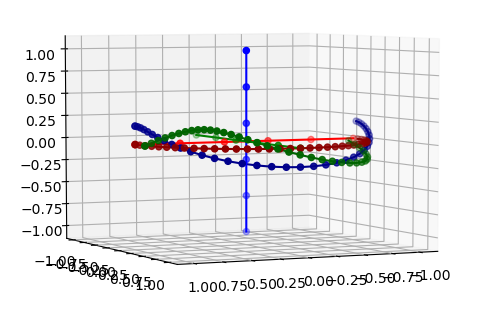
- Write up navigation results section. Introduce what it means to navigate, then the algorithms, then the plot on the chessboard of the two legal routes. Note that the two moves are linear diagonals in the actual and reconstructed chessboard
- In the discussion, emphasize how the chess language model is an embodiment of human bias that is encoded in the trajectories that are chosen, like the two-square first (rook) move
- Learning how to do pseudocode in LaTeX. Trying out algorithm2e. I think it actually looks pretty good.
- Mostly finished the results section. Need to do Discussion, Future Work, and Conclusions tomorrow
ML Seminar
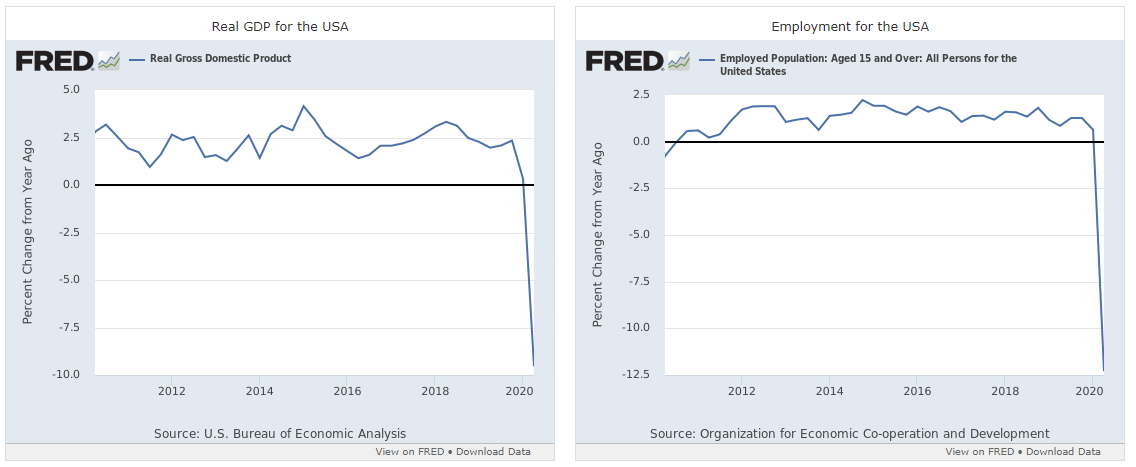
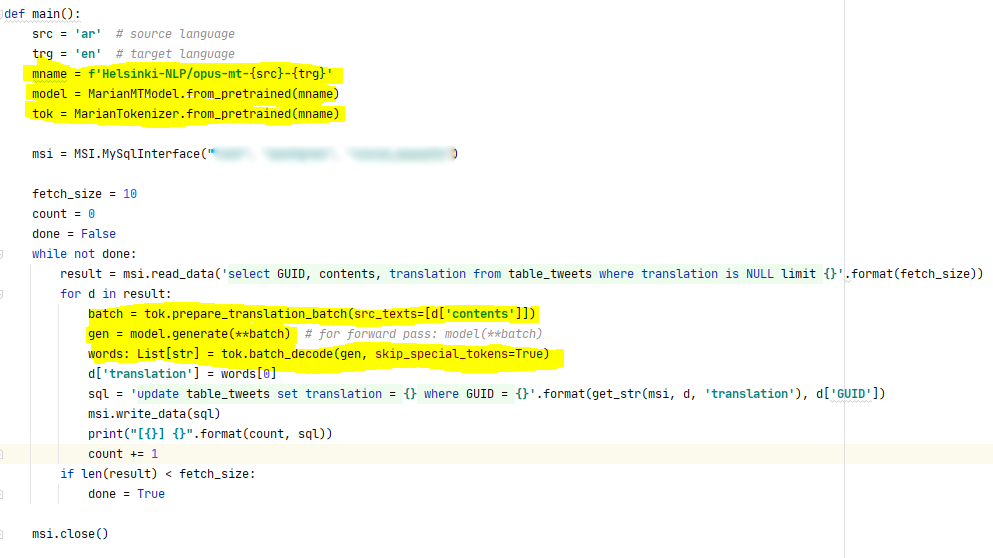
- Good meeting. I might have access to Twitter COVID data!
- I also realized that it is August and not September. Which means that instead of a week until submission, I have a MONTH and a week until submission
Write review for paper #4 – done! Two to go








You must be logged in to post a comment.