But Qwen 3.5, Google’s Gemma 4, and Microsoft’s MAI speech and image models are a bit different. These models feel less like proofs of concept and more like enterprise products.
“We’ve moved from interesting to now serious enterprise platforms,” Andrew Buss, senior research director at IDC, told El Reg.
The models underscore a stark reality: the gulf between enterprise and frontier AI has grown considerably over the past few years, and the mower powerful models are beyond the means of many enterprises.
“I think we are seeing a split,” Buss said. “We’re getting these larger, holistic models that are almost trying to be everything to everyone. But then we’re also seeing the rise of smaller, more specialized models that are tailored and geared to around more specific outcomes or query types.”
The legal profession has a long tradition of making junior employees work very hard with limited resources or support from seniors. In at least one case, the underling was told to use AI to generate a brief but was not given access to the legal database they needed to check cases. Saves money, right? That the legal profession can be as exploitative as any is no surprise. That it cannot help itself but get a taste for AI that overwhelms its judgment as surely as a nose full of cocaine is seemingly indicative of how dangerous AI can be. That the problem is getting worse is also a good indication that whatever the new models do better, hallucinations ain’t going away.
Tasks
BS paperwork – started
BS taxes! Started
Do a first pass on the pancake printer post and tie it back to agentic systems and “brickable” homes – started
Had an interesting chat with Gemini about my current research based on what I’ve been writing about in this blog over the last ten years. Some good content on looking at metaphorical reasoning as an engine of LLM output.
Tasks:
Bills – done
Chores – done
Laundry – done
Dishes – done
Hang pix – done!
BS paperwork – not done
Do a first pass on the pancake printer post and tie it back to agentic systems and “brickable” homes – not done
The ubiquity and ease of use of large language models makes it easy to overlook the interactional and interpretive processes at play. To understand the attraction of this technology we need to trace its sociotechnical roots. From divination and horoscopes and from ELIZA to present-day large language models, I document how people have been thinking with things, outsourcing judgement, and making sense of interactively presented non-sense. Following the lead of Lucy Suchman to “slow down discourses of the ‘smart’ machines”, I consider the interactional foundations of our engagement with technologies of language. I make the case that the fluid output, fine-tuned overconfidence, and interactive design of these computational artefacts conspire to exploit our interpretive processes and interactional infrastructure, rendering them irresistible to lay people and researchers alike. This means that a deep understanding of processes of human interaction and sense-making will be a foundational resource for the growing arsenal of methods in critical AI literacy.
Development in Artificial Intelligence (AI) has accelerated scientific discovery. Alongside recent AI-oriented Nobel prizes, these trends establish the role of AI tools in science. This advancement raises questions about the potential influences of AI tools on scientists and science as a whole, and highlights a potential conflict between individual and collective benefits. To evaluate, we used a pretrained language model to identify AI-augmented research, with an F1-score of 0.875 in validation against expert-labeled data. Using a dataset of 41.3 million research papers across natural science and covering distinct eras of AI, here we show an accelerated adoption of AI tools among scientists and consistent professional advantages associated with AI usage, but a collective narrowing of scientific focus. Scientists who engage in AI-augmented research publish 3.02 times more papers, receive 4.84 times more citations, and become research project leaders 1.37 years earlier than those who do not. By contrast, AI adoption shrinks the collective volume of scientific topics studied by 4.63% and decreases scientist’s engagement with one another by 22.00%. Thereby, AI adoption in science presents a seeming paradox — an expansion of individual scientists’ impact but a contraction in collective science’s reach — as AI-augmented work moves collectively toward areas richest in data. With reduced follow-on engagement, AI tools appear to automate established fields rather than explore new ones, highlighting a tension between personal advancement and collective scientific progress.
The format of the fake-disease experiment — and the way the results pretended to be from an official source, namely an academic paper, might have been a key factor in its success. In a separate study of 20 LLMs, Omar found that LLMs are more prone to hallucinate and elaborate on misinformation when the text they’re processing looks professionally medical — formatted like a hospital discharge note or clinical paper — than when it comes from social-media posts (M. Omar et al. Lancet Digit. Health 8, 100949; 2026). “When the text looks professional and written as a doctor writes, there’s an increase in the hallucination rates,” says Omar.
The experiment’s reach has now spread into the published medical literature. The bixonimania research has been cited by a handful of researchers, including a study that appeared in Cureus, a journal published by Springer Nature, the publisher of Nature, by researchers at the Maharishi Markandeshwar Institute of Medical Sciences and Research in Mullana, India (S. Banchhor et al. Cureus 16, e74625 (2024); retraction 18, r223 (2026)). (Nature’s news team is editorially independent of its publisher.) That study cites one of the fake preprints and says: “Bixonimania is an emerging form of POM [periorbital melanosis] linked to blue light exposure; further research on the mechanism is underway.”
We report on an astonishing ability of large language models (LLMs) to make sense of “Jabberwocky” language in which most or all content words have been randomly replaced by nonsense strings, e.g., translating “He dwushed a ghanc zawk” to “He dragged a spare chair”. This result addresses ongoing controversies regarding how to best think of what LLMs are doing: are they a language mimic, a database, a blurry version of the Web? The ability of LLMs to recover meaning from structural patterns speaks to the unreasonable effectiveness of pattern-matching. Pattern-matching is not an alternative to “real” intelligence, but rather a key ingredient.
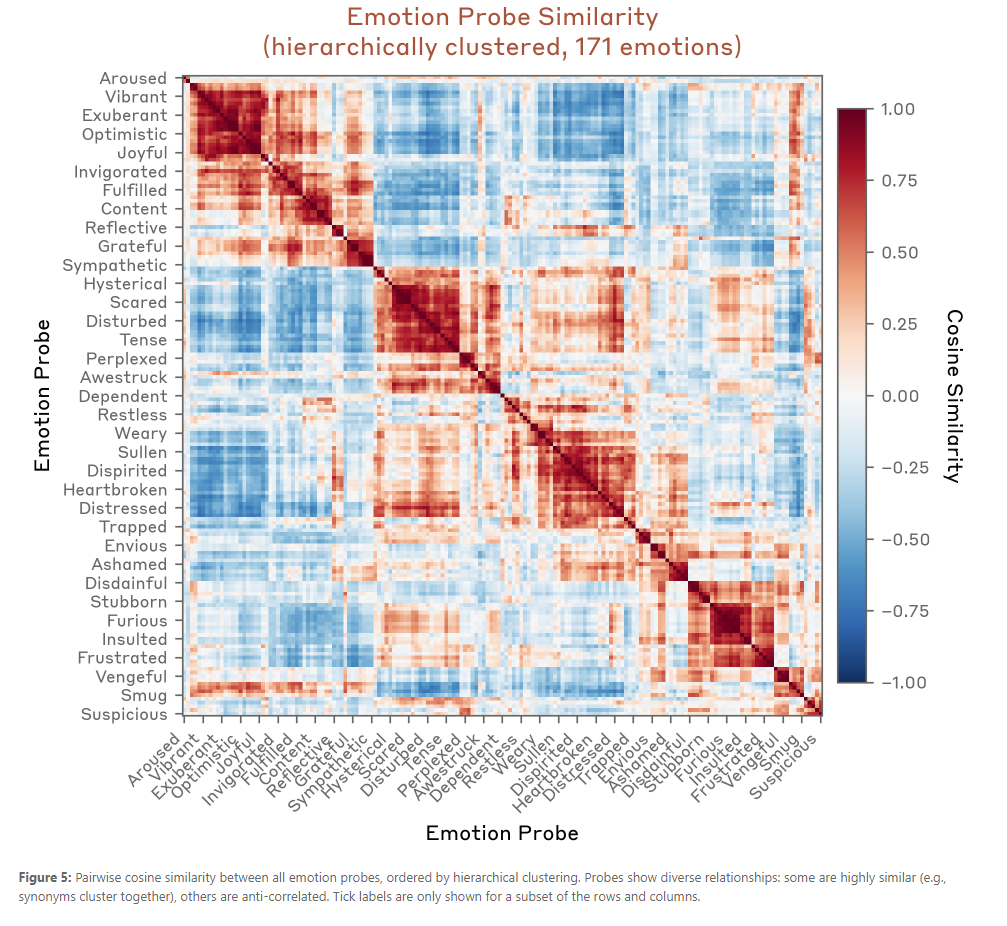
Large language models (LLMs) sometimes appear to exhibit emotional reactions. We investigate why this is the case in Claude Sonnet 4.5 and explore implications for alignment-relevant behavior. We find internal representations of emotion concepts, which encode the broad concept of a particular emotion and generalize across contexts and behaviors it might be linked to. These representations track the operative emotion concept at a given token position in a conversation, activating in accordance with that emotion’s relevance to processing the present context and predicting upcoming text. Our key finding is that these representations causally influence the LLM’s outputs, including Claude’s preferences and its rate of exhibiting misaligned behaviors such as reward hacking, blackmail, and sycophancy. We refer to this phenomenon as the LLM exhibiting functional emotions: patterns of expression and behavior modeled after humans under the influence of an emotion, which are mediated by underlying abstract representations of emotion concepts. Functional emotions may work quite differently from human emotions, and do not imply that LLMs have any subjective experience of emotions, but appear to be important for understanding the model’s behavior.
Tasks
10:20 dentist
Lunch? Bank?
More unpacking. Do I want to add another pegboard?
If you got a knock on your door from someone inviting you to Brussels to hash out some EU policies…you’d think it was a scam, right? Us, too. At least, that was the case until last week, when our producer Wojciech went to report on a European Citizens’ Panel, an event designed to allow 150 randomly selected Europeans to weigh in on some of the EU’s thorniest problems. This week we’re taking a deep dive into the ins and outs of what seems like the nerdiest game show ever. How do these panels work? What do they actually achieve? And crucially, are they worth the cost?
Tasks
Tires! Is this a theme for the week?
More shop unpacking – hung pix! Set up cleaners! Used them on a FILTHY chain and cogset! Managed to change a tubless tire with only a slight amount of mess. I did use the kitchen sink a bit.
Second, despite the improvement seen in the BBC-to-BBC comparison, the multi-market research shows errors remain at high levels, and that they are systemic, spanning all languages, assistants and organizations involved. Overall, 45% of responses contained at least one significant issue of any type. Sourcing is the single biggest cause of significant issues (31%). Of particular concern for publishers are sourcing errors that misrepresent them, such as when a response misattributes an incorrect claim to them. Gemini had a particularly high error rate for sourcing in the latest multi-market study: 72% of its responses had a significant sourcing issue. All other assistants were below 25%.
And yet, many people do trust AI assistants to be accurate. separate BBC research published at the same time as this report shows that just over a third of UK adults say they completely trust AI to produce accurate summaries of information. This rises to almost half of under 35s. That misplaced confidence raises the stakes when assistants are getting the basics wrong. These shortcomings also carry broader consequences: 42% of adults say they would trust an original news source less if an AI news summary contained errors, and audiences hold both AI providers and news brands responsible when they encounter errors. The reputational risk for media companies is great, even when the AI assistant alone is to blame for the error.
If AI assistants are not yet a reliable way to access the news, but many consumers trust them to be accurate, we have a problem. This is exacerbated by AI assistants and answer-first experiences reducing traffic to trusted publishers.
Exposure to misinformation poses significant challenges to democratic processes and public health, particularly during critical events like elections. This study adopts a user-centric approach to analyze the linguistic features of misinformation actually consumed by individuals during web browsing. Using data from a nationally representative panel of 1,240 American adults and their web-browsing data (21M URL visits) during the 2020 U.S. Presidential Election, we examine linguistic and topical differences in the content of 91K unique misinformation and hard news webpages by utilizing natural language processing techniques and Large Language Models. We find that misinformation consumed by users is generally easier to read, exhibits higher negative sentiment, and employs more moral language than hard news. We also find significant linguistic variations across topics–misinformation can be diverse and vary in linguistic features depending on the subject matter. We also identify heterogeneity across key user characteristics: older adults consume more misinformation about COVID-19 and health, with content showing more negative sentiment and fewer moral terms than expected. Republicans engage with misinformation characterized by more negative sentiment and higher moral language, focusing less on health topics and more on social and political issues. These results highlight the importance of a user-centric approach and suggest that interventions to combat misinformation should be tailored to specific topics and user characteristics for greater effectiveness.
What precipitates the collapse of seemingly durable social orders like Jim Crow? During the 1920s, approximately 5,000 “Rosenwald Schools” were built across the rural South through a partnership between philanthropist Julius Rosenwald and Black communities who raised matching funds, donated land, and petitioned local governments. Local elites saw vocational training that would preserve the racial order. We argue Black educators used this accommodationist cover to build veiled capacity: organizational infrastructure for collective action behind a veil of compliance. Counties with more Rosenwald Schools show greater civil rights protest in the 1960s. Mediation analysis reveals that pre-existing social capital predicted protest through Rosenwald teacher placements, not overall Black enrollment. Instrumental variable models suggest the effect is not driven by community selection. Moving from no Rosenwald teachers to the 75th percentile predicts 45% more protest. The political effects of education may depend less on what elites intend than on what educators build where elites cannot see.
Can a large language model (LLM) improve at code generation using only its own raw outputs, without a verifier, a teacher model, or reinforcement learning? We answer in the affirmative with simple self-distillation (SSD): sample solutions from the model with certain temperature and truncation configurations, then fine-tune on those samples with standard supervised fine-tuning. SSD improves Qwen3-30B-Instruct from 42.4% to 55.3% pass@1 on LiveCodeBench v6, with gains concentrating on harder problems, and it generalizes across Qwen and Llama models at 4B, 8B, and 30B scale, including both instruct and thinking variants. To understand why such a simple method can work, we trace these gains to a precision-exploration conflict in LLM decoding and show that SSD reshapes token distributions in a context-dependent way, suppressing distractor tails where precision matters while preserving useful diversity where exploration matters. Taken together, SSD offers a complementary post-training direction for improving LLM code generation.
Despite the rapid adoption of LLM chatbots, little is known about how they are used. We document the growth of ChatGPT’s consumer product from its launch in November 2022 through July 2025, when it had been adopted by around 10% of the world’s adult population. Early adopters were disproportionately male but the gender gap has narrowed dramatically, and we find higher growth rates in lower-income countries. Using a privacy-preserving automated pipeline, we classify usage patterns within a representative sample of ChatGPT conversations. We find steady growth in work-related messages but even faster growth in non-work-related messages, which have grown from 53% to more than 70% of all usage. Work usage is more common for educated users in highly-paid professional occupations. We classify messages by conversation topic and find that “Practical Guidance,” “Seeking Information,” and “Writing” are the three most common topics and collectively account for nearly 80% of all conversations. Writing dominates work-related tasks, highlighting chatbots’ unique ability to generate digital outputs compared to traditional search engines. Computer programming and self-expression both represent relatively small shares of use. Overall, we find that ChatGPT provides economic value through decision support, which is especially important in knowledge-intensive jobs.
Tasks
Croatia Spreadsheet – started
Chores
Dishes – done
Bookshelf. Discovered I only had half of it and had to take a trip to College Park for part two.
Multimodal AI systems have achieved remarkable performance across a broad range of real-world tasks, yet the mechanisms underlying visual-language reasoning remain surprisingly poorly understood. We report three findings that challenge prevailing assumptions about how these systems process and integrate visual information. First, Frontier models readily generate detailed image descriptions and elaborate reasoning traces, including pathology-biased clinical findings, for images never provided; we term this phenomenon mirage reasoning. Second, without any image input, models also attain strikingly high scores across general and medical multimodal benchmarks, bringing into question their utility and design. In the most extreme case, our model achieved the top rank on a standard chest X-ray question-answering benchmark without access to any images. Third, when models were explicitly instructed to guess answers without image access, rather than being implicitly prompted to assume images were present, performance declined markedly. Explicit guessing appears to engage a more conservative response regime, in contrast to the mirage regime in which models behave as though images have been provided. These findings expose fundamental vulnerabilities in how visual-language models reason and are evaluated, pointing to an urgent need for private benchmarks that eliminate textual cues enabling non-visual inference, particularly in medical contexts where miscalibrated AI carries the greatest consequence. We introduce B-Clean as a principled solution for fair, vision-grounded evaluation of multimodal AI systems.
In line with the Earth AI vision, we recently introduced S2Vec, a self-supervised framework designed to learn general-purpose embeddings (i.e., compact, numerical summaries) of the built environment. S2Vec allows AI to understand the character of a neighborhood much like a human does, recognizing patterns in how gas stations, parks, and housing are distributed, and using that knowledge to predict metrics that matter, from population density to environmental impact. In our evaluations, S2Vec demonstrated competitive performance against image-based baselines in socioeconomic prediction tasks, particularly in geographic adaptation (extrapolation), while showing a clear need for improvement in environmental tasks, like tree cover and elevation.
Scalable general-purpose representations of the built environment are crucial for geospatial artificial intelligence applications. This paper introduces S2Vec, a novel self-supervised framework for learning such geospatial embeddings. S2Vec uses the S2 Geometry library to partition large areas into discrete S2 cells, rasterizes built environment feature vectors within cells as images, and applies masked autoencoding on these rasterized images to encode the feature vectors. This approach yields task-agnostic embeddings that capture local feature characteristics and broader spatial relationships. We evaluate S2Vec on several large-scale geospatial prediction tasks, both random train/test splits (interpolation) and zero-shot geographic adaptation (extrapolation). Our experiments show S2Vec’s competitive performance against several baselines on socioeconomic tasks, especially the geographic adaptation variant, with room for improvement on environmental tasks. We also explore combining S2Vec embeddings with image-based embeddings downstream, showing that such multimodal fusion can often improve performance. Our findings highlight how S2Vec can learn effective general-purpose geospatial representations of the built environment features it is provided, and how it can complement other data modalities in geospatial artificial intelligence.
Clustering is chunking along. It will take about 40 days. It may make more sense to simply try to place all the coordinates in a list and calculate all 22M embeddings at once if that can fit. It seemed faster, and we can keep the clusterer






You must be logged in to post a comment.