
7:00 – 4:30 ASRC MKT
- Editing videos
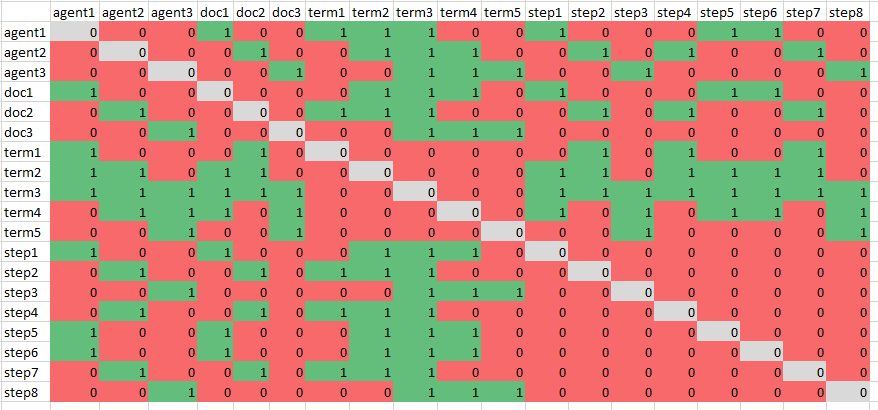
- Need to think about short CHI paper about designing for culture/robot interactions. The trolly problem at scale? How would the sim be set up? The amount of randomness at the initial condition? Stiffness vs. connectivity? Beleif space is still important and is actually used as a concept in path planning
- Visual Exploration and Comparison of Word Embeddings
- Word embeddings are distributed representations for natural language words, and have been wildly used in many natural language processing tasks. The word embedding space contains local clusters with semantically similar words and meaningful directions, such as the analogy. However, there are different training algorithms and text corpora, which both have a different impact on the generated word embeddings. In this paper, we propose a visual analytics system to visually explore and compare word embeddings trained by different algorithms and corpora. The word embedding spaces are compared from three aspects, i.e., local clusters, semantic directions and diachronic changes, to understand the similarity and differences between word embeddings.
- Much work on slides
- Can’t get Google to recognise my account?
curl.exe -H "Content-Type: application/json" -H "Authorization: Bearer "$(gcloud auth application-default print-access-token) https://speech.google apis.com/v1/speech:recognize -d @sync-request.json curl: (6) Could not resolve host: ya29.c.EloHBu32-0nBAqimi1Zumlot6rjGtGpUk27qTTESRLW4vtd1LY4ihxBIesU3ga-kmwCaM7YZS-JRo_KNjaC_bj13dWazBcKr4YtAEQYFzSpSBx3DwdS46DTt0bg { "error": { "code": 403, "message": "The request is missing a valid API key.", "status": "PERMISSION_DENIED" } }No idea what host: ya29.c.EloHBu32-0nBAqimi1Zumlot6rjGtGpUk27qTTESRLW4vtd1LY4ihxBIesU3ga-kmwCaM7YZS-JRo_KNjaC_bj13dWazBcKr4YtAEQYFzSpSBx3DwdS46DTt0bg is
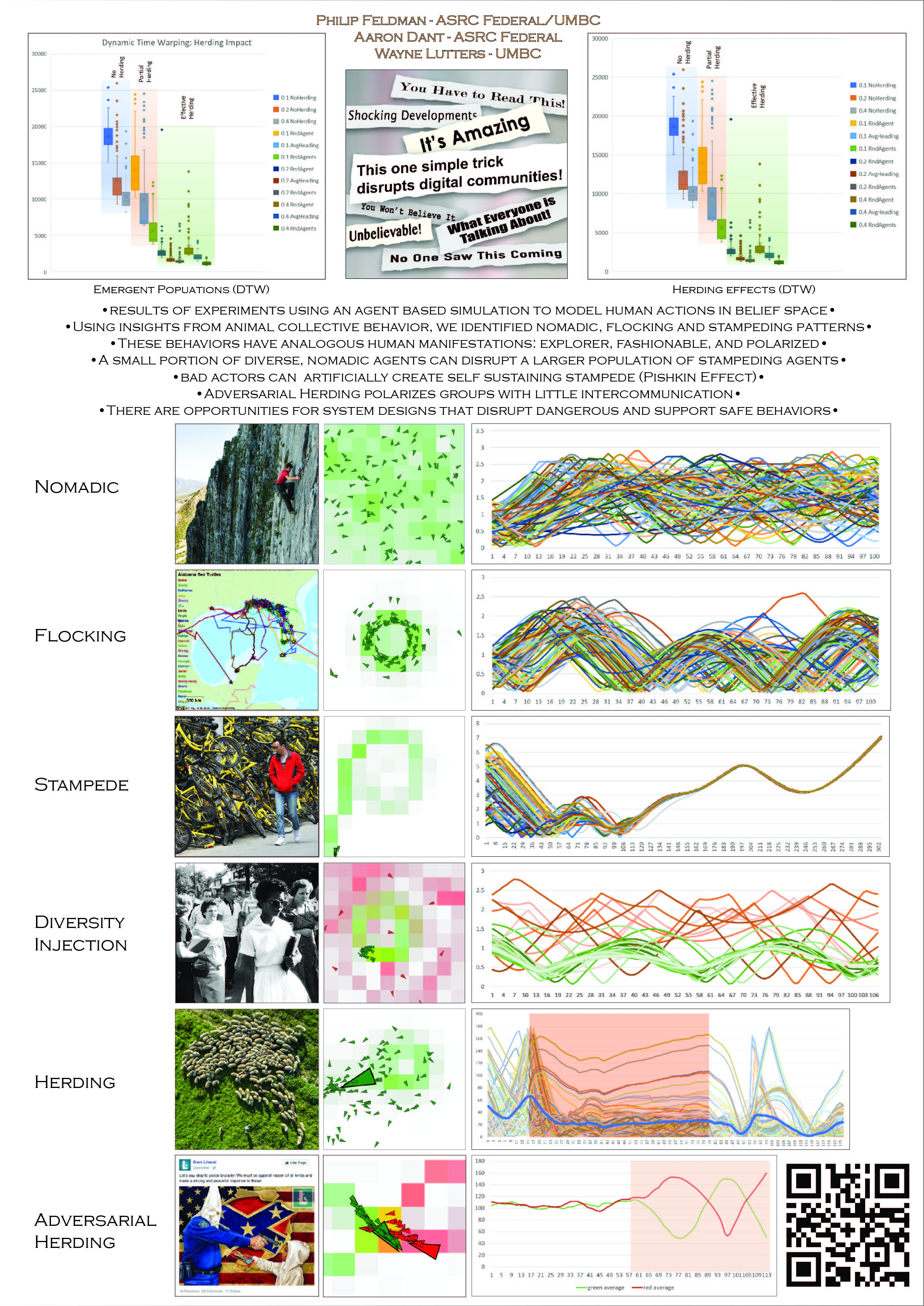
- Found a problem with the poster. There are two herding DTW charts. Must be reprinted










You must be logged in to post a comment.