Tasks
- Check in and boarding pass
- Dispute Dulles greenway charge – done
- Update EZ pass address – done
- Pay Dulles – done
- Chores
- Laundry
- Dishes
- Trash
SBIRs
- Timesheet – done
- Check through quarterly report

Tasks
SBIRs

Example of Organizational Lobotomy
Tasks
SBIRs
BuzzFeed Nearing Bankruptcy After Disastrous Turn Toward AI
Tasks
SBIRs
Our Heroes, Your Villains: How Americans Polarize Around Historical Figures
Task
SBIRS
How to Talk to Someone Experiencing ‘AI Psychosis’
Narrative Integrity Risk: The Next Frontier in Financial Stability | Lawfare
Tasks
SBIRs
AI agents now help attackers, including North Korea, manage their drudge work
Tasks
SBIRs
I think there is a hidden lesson in the Epstein files about the mechanisms that keep billionaires in check. May have to write up something about that.
Father sues Google, claiming Gemini chatbot drove son into fatal delusion.
Tasks
SBIRs
Don’t Worry About the Vase has many words addressing many things.
Primarily it is now a blog about AI.
Tasks
SBIRs
I have re-emerged after the move. Computers are up and chunking away on embeddings
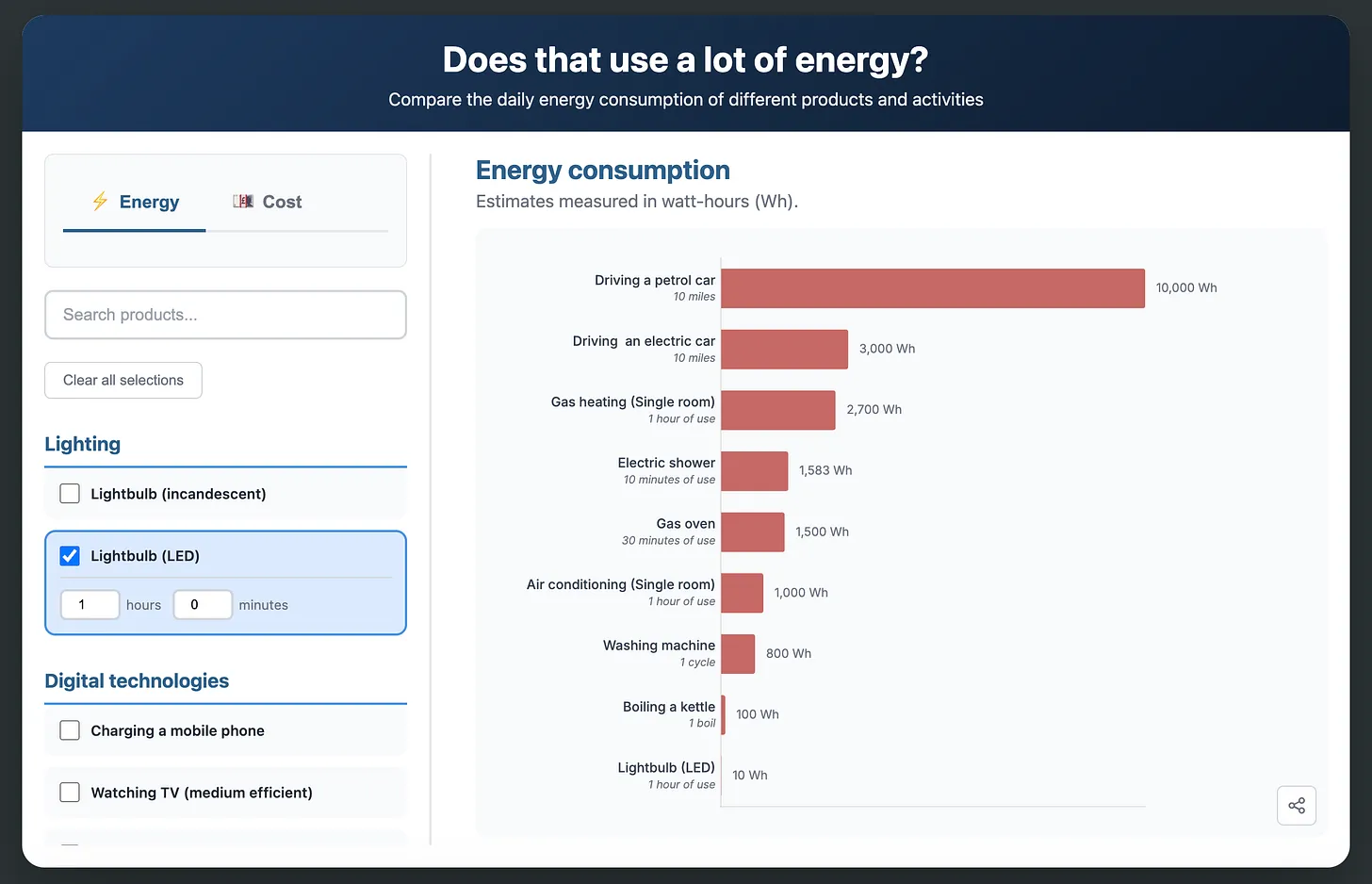
This is a very nice tool for comparing the various energy use of things: https://hannahritchie.github.io/energy-use-comparisons/
Tasks
SBIRs

I write an entire book on this, and they do it in a comic panel. Tip of the hat.
Tasks

Tasks
SBIRS

Back from cycling in Mallorca – that was a lot of fun
Tasks
SBIRs
Another trip around the sun!
Having fun riding around in Mallorca, not seeing snow
Worked on the adjustments to the proposal to the KA book , which I guess I should now be referring to the WGAI book. Need to send a note to Aaron – done

You must be logged in to post a comment.