Made some progress on P33. Need to reach out to Manlio De Domenico on that? Also Markus Schneider for the Trustworthy Information proposal
So here’s an interesting thing. There is a considerable discourse about how AI is wrecking the environment. It is absolutely true that there are more datacenters getting made and they – on average – use a lot of water and a good deal of energy.
But there are a lot of worse offenders. Data centers consume about 4.5% of electricity in the US. That’s for everything. AI, the WordPress instance that you are reading now, Netflix streaming gigabytes of data per second – everything.
But there are much bigger energy users. To generate enough tokens for the entire Lord of the Rings trilogy, a LLama3 model probably uses about 5 watt/hours. Transportation – a much larger energy consumer shows how small this is. A Tesla Model 3 could manage to go about 25 feet, or a bit under 10 meters. Transportation, manufacturing, and energy production use a lot more energy:
Source: Wikipedia
If you want to make some changes in energy consumption. Go after small improvements in the big consumers. Reduce energy consumption in say, electricity production (37%) by doubling solar, and that’s the equivalent of cutting the power use of AI by 50%.
In addition to energy consumption, data centers require cooling. And they use a lot, though that is steadily being optimized down. On average a data center uses about 32 million gallons of water for cooling.
Sounds like a lot, right?
Let’s look at the oil and gas industry. The process of fracking, where water is injected at high pressure into oil and gas containing rock from about 2,500 wells uses about 11 million gallons to produce crude oil. So data centers are worse that fracking!
But hold on. You still have to process that oil. And it turns out that for every barrel of oil refined in the US, about 1.5 barrels of water are used. The USA refines about 5.5 billion barrels of oil per year. Combine that with the fracking numbers and the oil and gas industry uses about 500 billion gallons of water per year, or 5 times the amount of data centers doing all the things data centers do, including AI.
To keep this short, we are not going to even talk about the water use of agriculture here.
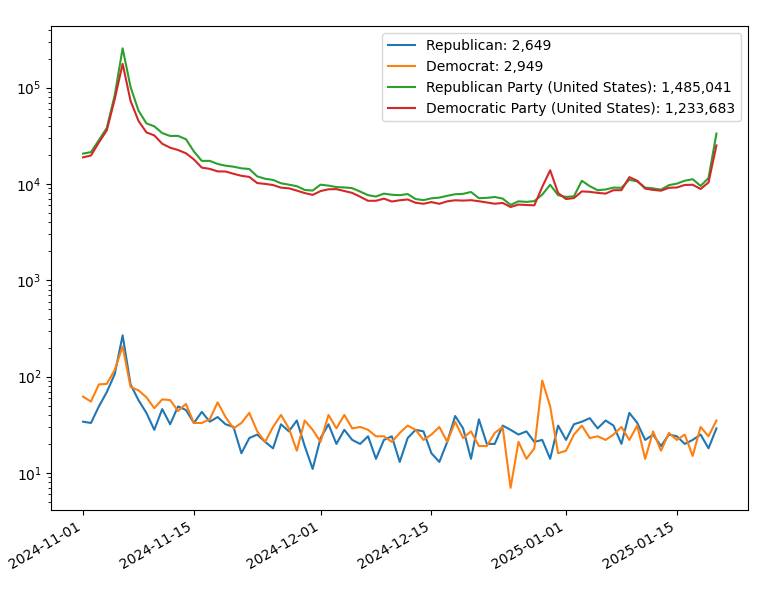
So why all the ink spilled to talk about this. Well, AI is new and it gets clicks, but I went to look at google trends to see how the discussion of water use for AI and Fracking, and I got an interesting relationship:
The amount of discussion about Fracking in this case has leveled off as the discussion of AI has taken off. And given the history that the oil industry has in generating FUD (fear, uncertainty and doubt), I would not be in the least surprised if it turns out that the oil industry is fueling the moral panic about AI to distract us from the real dangers and to keep those businesses profitable.
Killer Apps
SBIRs
- 9:00 sprint demos
- 3:00 sprint planning
- Training data file size sensitivity tests
- Editor tool support for designing threats/assets
- Transforming x to x’y’ (rotate and translate)
- Optimize data creation
- Single, randomized, trajectory calculation and intercept attempt for “real-time” demo
- Multiple threat (raid) support
- USNA support















You must be logged in to post a comment.