
I tuned in to the Jan 6 committee hearing thinking I’d have it on in the background, but it was riveting. I wound up watching the whole thing
The Internet Needs You-Are-Here Maps
- Nabeel Gillani is a Postdoctoral Associate at the MIT Center for Constructive Communication, and will lead the Plural Connections Group as an Assistant Professor of Design and Data at Northeastern University starting Fall 2022.
- Deb Roy is a professor and director at the MIT Center for Constructive Communication; he is the co-founder, CEO, and chair of Cortico.
Trump Fan Confesses To FBI That He Electroshocked D.C. Cop During Capitol Attack
- The video of the FBI’s March 31 interview of Rodriguez, released to members of the media by federal prosecutors this week after an order from U.S. District Judge Amy Berman Jackson, is a remarkable look at how a radical Trump supporter came to engage in an act of domestic terrorism in hopes of keeping the former president in office for a second term. An emotional Rodriguez explains how he actually believed Trump’s dangerous lies about the 2020 election, referring to himself as “fucking piece of shit,” “so stupid,” “an asshole,” and “not smart” as he confesses his crimes.
- Really good example of stampede behavior
Book
- Reworking the proposal
SBIRs
- Fix broken things? Not sure what will be needed today
GPT Agents
- Continue on tweet app as per here
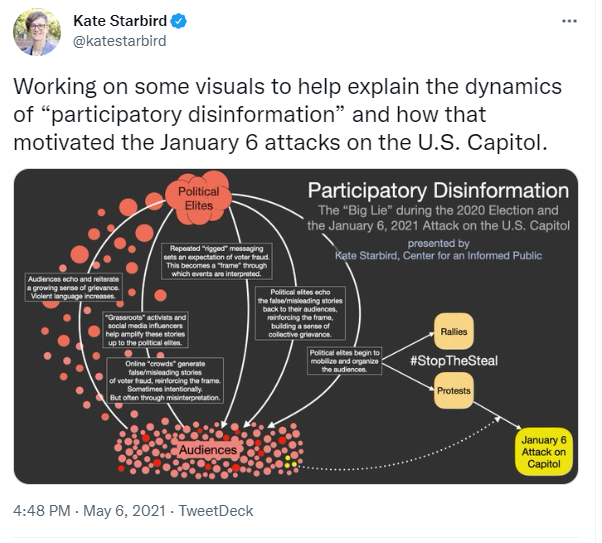




You must be logged in to post a comment.