Semantic Exploration from Language Abstractions and Pretrained Representations
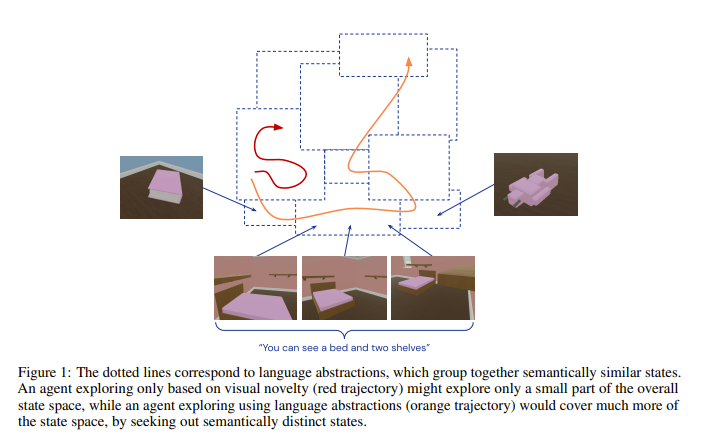
- Continuous first-person 3D environments pose unique exploration challenges to reinforcement learning (RL) agents because of their high-dimensional state and action spaces. These challenges can be ameliorated by using semantically meaningful state abstractions to define novelty for exploration. We propose that learned representations shaped by natural language provide exactly this form of abstraction. In particular, we show that vision-language representations, when pretrained on image captioning datasets sampled from the internet, can drive meaningful, task-relevant exploration and improve performance on 3D simulated environments. We also characterize why and how language provides useful abstractions for exploration by comparing the impacts of using representations from a pretrained model, a language oracle, and several ablations. We demonstrate the benefits of our approach in two very different task domains — one that stresses the identification and manipulation of everyday objects, and one that requires navigational exploration in an expansive world — as well as two popular deep RL algorithms: Impala and R2D2. Our results suggest that using language-shaped representations could improve exploration for various algorithms and agents in challenging environments.
Tasks
- Mulch and edging
- Fortunately, taxes are already done!
- Maybe get started on chores
SBIRs
- Send text to JHU – done! But they aren’t going for it
- Code generation
- Made some buttons that trigger non-functional callbacks
- Got the immutable-ish child classes working
GPT Agents
- Upload Yelp paper to ArXiv – done!
Book
- Start finishing deep bias – done?
- Definitions
Ending the week with this: