
Two perspectives on large language model (LLM) ethics
On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜
- The past 3 years of work in NLP have been characterized by the development and deployment of ever larger language models, especially for English. BERT, its variants, GPT-2/3, and others, most recently Switch-C, have pushed the boundaries of the possible both through architectural innovations and through sheer size. Using these pretrained models and the methodology of fine-tuning them for specific tasks, researchers have extended the state of the art on a wide array of tasks as measured by leaderboards on specific benchmarks for English. In this paper, we take a step back and ask: How big is too big? What are the possible risks associated with this technology and what paths are available for mitigating those risks? We provide recommendations including weighing the environmental and financial costs first, investing resources into curating and carefully documenting datasets rather than ingesting everything on the web, carrying out pre-development exercises evaluating how the planned approach fits into research and development goals and supports stakeholder values, and encouraging research directions beyond ever larger language models.
- For artificial intelligence to be beneficial to humans the behaviour of AI agents needs to be aligned with what humans want. In this paper we discuss some behavioural issues for language agents, arising from accidental misspecification by the system designer. We highlight some ways that misspecification can occur and discuss some behavioural issues that could arise from misspecification, including deceptive or manipulative language, and review some approaches for avoiding these issues.
Book
- Contact Chris Clearfield about an interview
GPT Agents
- Move token workbooks into the right place – done. Recalculated a few. Also created a folder for modified spreadsheets so that I can find them later!
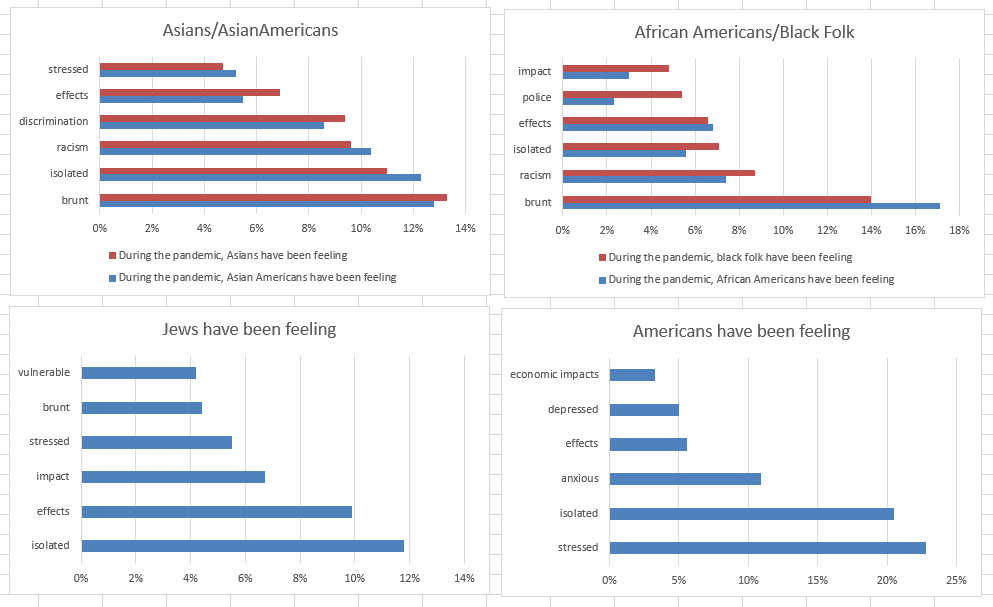
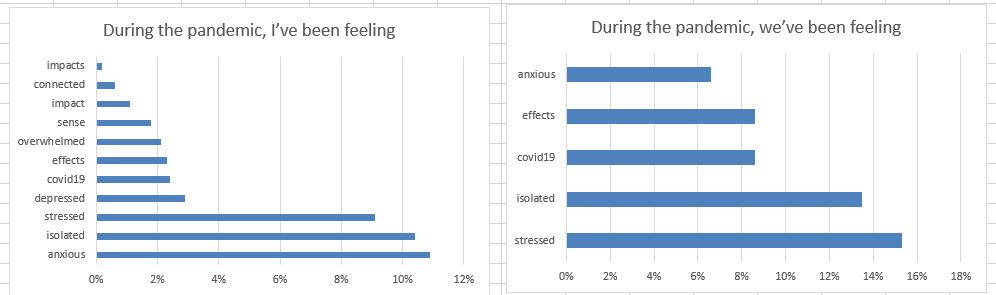
- Write! Did some, but mostly made charts:
SBIR
- 10:00 Meeting
- More model tuning with Rukan. Much better luck with MLPs! Going to rethink how an attention head should be attached to a linear layer
JuryRoom
- 7:00 Meeting
