
Really good weekend. I feel almost recharged to this time last week 🙂
Language Models as Knowledge Bases (Via Shimei)
- Recent progress in pretraining language models on large textual corpora led to a surge of improvements for downstream NLP tasks. Whilst learning linguistic knowledge, these models may also be storing relational knowledge present in the training data, and may be able to answer queries structured as “fill-in-the-blank” cloze statements. Language models have many advantages over structured knowledge bases: they require no schema engineering, allow practitioners to query about an open class of relations, are easy to extend to more data, and require no human supervision to train. We present an in-depth analysis of the relational knowledge already present (without fine-tuning) in a wide range of state-of-the-art pretrained language models. We find that (i) without fine-tuning, BERT contains relational knowledge competitive with traditional NLP methods that have some access to oracle knowledge, (ii) BERT also does remarkably well on open-domain question answering against a supervised baseline, and (iii) certain types of factual knowledge are learned much more readily than others by standard language model pretraining approaches. The surprisingly strong ability of these models to recall factual knowledge without any fine-tuning demonstrates their potential as unsupervised open-domain QA systems. The code to reproduce our analysis is available at this https URL.
#COVID
- Currently at 103, 951 tweets translated
JuryRoom
- Write reference section – done
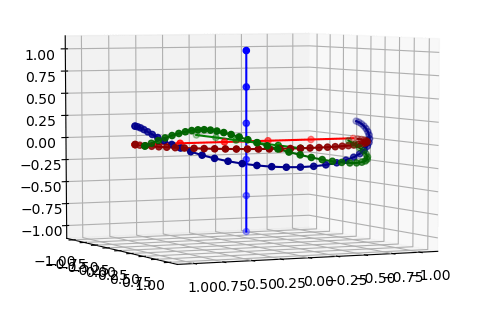
GOES
- I need to do an incremental rotation to track the reference points from last week
- Still having problems with the secondary rotation. I’m clearly doing something basic wrong
- Meeting with Vadim
GPT-2 Agents
- Create a word cloud for multiple passes of “She came into the room”
- Add something about the place for qualitative research in a Language model sociology. Outliers are the places that the models learn to ignore. So traditional research will be the way that these marginalized populations are not forgotten.
- Screwed up the ArXiv bibliography submission. Fixed
ICTAI
- Started reading the last paper, which is on <shudder> ontologies









You must be logged in to post a comment.