
A brief history of high-speed trading (via the Museum of American Finance)
- In the late 1830s, Philadelphia broker William C. Bridges operated a private signal station between New York and Philadelphia which disseminated stock market news to him and his backers (and to no one else). The signals were transmitted through an “optical telegraph,” which consisted of a series of boards on a pole, mounted on hills that could be seen by a telescope.
DtZ
- The IHME site has improved to the point that we should pull down our site
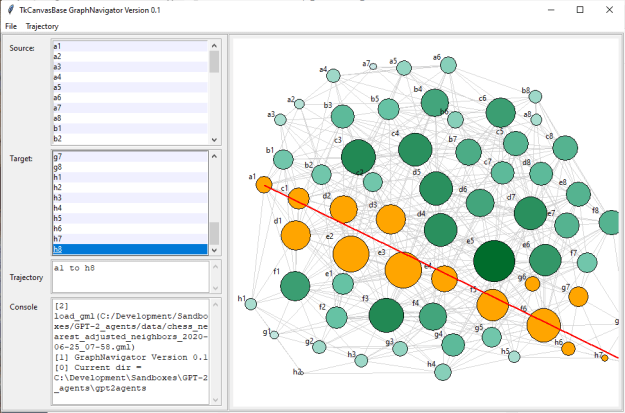
GPT-2 Agents
- Need to think about how to show that interrogating a language model is sufficiently similar to interrogating actual data.
- At this point, I know that the language model comes up with legal moves
- I need to compare the statistics of actual moves to synthetic moves to see if the populations are sufficiently similar. This means that I need to get the training and evaluation data into the database. Once that’s done, I can compare the frequency of move types (e.g. “At move 10, White moves pawn from a2 to a4”), and the moves from a particular location (e.g. “e2” can have moves to “e3” and “e4” with the pawn, or diagonals with the “f1” bishop or the white queen).
- The level of similarity should indicate if the biases of the players are represented in the language model.
- There should be a way of determining a lower bound of data?
- Once this is shown, then the idea of generalizing to other human interactions can be justified.
- Started PGNtoDB, which will populate table_actual
- Ignoring castling for now
- Chunking into the database! And by chunking, I refer to the sound of the drive 🙂
- And now I have a catalog of 188,324 human chess moves

GOES
- 10:00 Meeting with Vadim
- 2:00 Status
- Last training for a while!







You must be logged in to post a comment.