
7:00 – 4:30 ASRC BD
- Starting to add content to the proposal. Going to put together a section on game theory that ties together Beyond Individual Choice, The Evolution of Cooperation, and Consensus and Cooperation in Networked Multi-Agent Systems
- Got some good writing done, but didn’t upload!
- And also, voter influencing from this post
- And I just saw this! Structure of Decision: The Cognitive Maps of Political Elites. It’s another book by Robert Axelrod. Ordered.
- Putting together my notes on the Evolution of Cooperation. Can’t believe I haven’t done that yet
- Got a good response from Antonio. Need to respond
- Found some good stuff on market-oriented programming for Antonio’s workshop. The person who seems to really own this space is Michael Wellman (Scholar). Downloaded several of his papers.
- Michael P. Wellman is Professor of Computer Science & Engineering at the University of Michigan. He received a PhD from the Massachusetts Institute of Technology in 1988 for his work in qualitative probabilistic reasoning and decision-theoretic planning. From 1988 to 1992, Wellman conducted research in these areas at the USAF’s Wright Laboratory. For the past 25 years, his research has focused on computational market mechanisms and game-theoretic reasoning methods, with applications in electronic commerce, finance, and cyber-security. As Chief Market Technologist for TradingDynamics, Inc., he designed configurable auction technology for dynamic business-to-business commerce. Wellman previously served as Chair of the ACM Special Interest Group on Electronic Commerce (SIGecom), and as Executive Editor of the Journal of Artificial Intelligence Research. He is a Fellow of the Association for the Advancement of Artificial Intelligence and the Association for Computing Machinery.
- From Benjamin Schmidt, via Twitter:
- I have a new article in CA on dimensionality reduction for digital libraries. http://culturalanalytics.org/2018/09/stable-random-projection-lightweight-general-purpose-dimensionality-reduction-for-digitized-libraries/ …. Let me walk through one figure, Eames power-of-10 style, that shows a machine clustering of all 14 million books in the collection–including most of the books you’ve read.
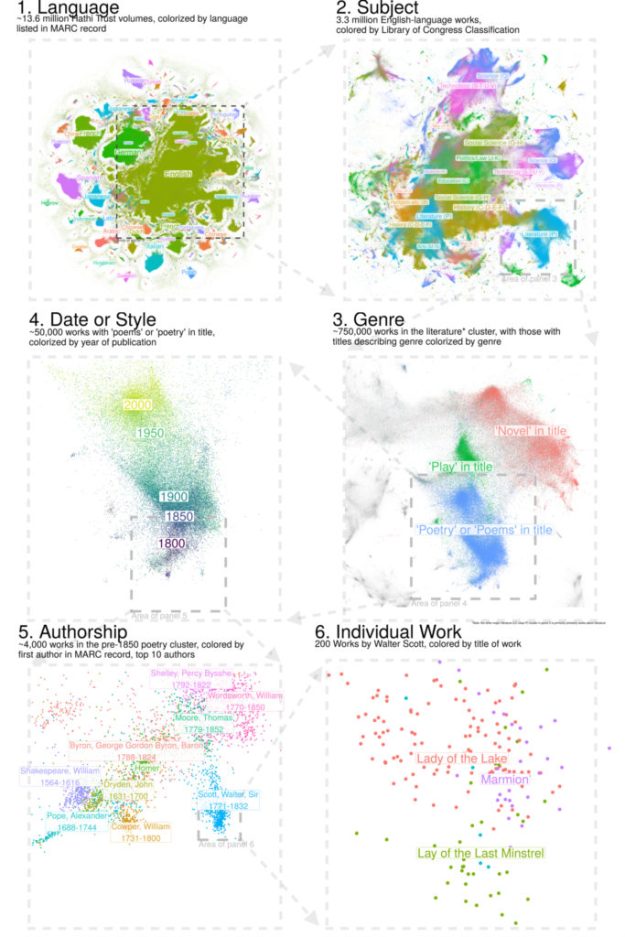 This is very close to mapping as I understand it. There is the ability to zoom in and out at different levels of structure. His repo is here, but its for [R]
This is very close to mapping as I understand it. There is the ability to zoom in and out at different levels of structure. His repo is here, but its for [R]- Random Projection in Scikit-learn
- Here’s the paper its based on: Visualizing Large-scale and High-dimensional Data
- We study the problem of visualizing large-scale and high-dimensional data in a low-dimensional (typically 2D or 3D) space. Much success has been reported recently by techniques that first compute a similarity structure of the data points and then project them into a low-dimensional space with the structure preserved. These two steps suffer from considerable computational costs, preventing the state-of-the-art methods such as the t-SNE from scaling to large-scale and high-dimensional data (e.g., millions of data points and hundreds of dimensions). We propose the LargeVis, a technique that first constructs an accurately approximated K-nearest neighbor graph from the data and then layouts the graph in the low-dimensional space. Comparing to t-SNE, LargeVis significantly reduces the computational cost of the graph construction step and employs a principled probabilistic model for the visualization step, the objective of which can be effectively optimized through asynchronous stochastic gradient descent with a linear time complexity. The whole procedure thus easily scales to millions of high-dimensional data points. Experimental results on real-world data sets demonstrate that the LargeVis outperforms the state-of-the-art methods in both efficiency and effectiveness. The hyper-parameters of LargeVis are also much more stable over different data sets.
