Research 6:45 – 7:45
- Thinking that the emergent agent properties might map to political theories. This is the best overview I’ve found: Political Theory/Ideologies of Government
- From Mindless Masses to Small Groups: Conceptualizing Collective Behavior in Crowd Modeling
- Self-organizing pedestrian movement
- Continuing writing. Getting close to a full outline
BRI 8:30 – 3:30
- Working on reading in files, then running permutations on cluster membership
- Because I can never remember how ass-backwards pandas.Dataframes are:
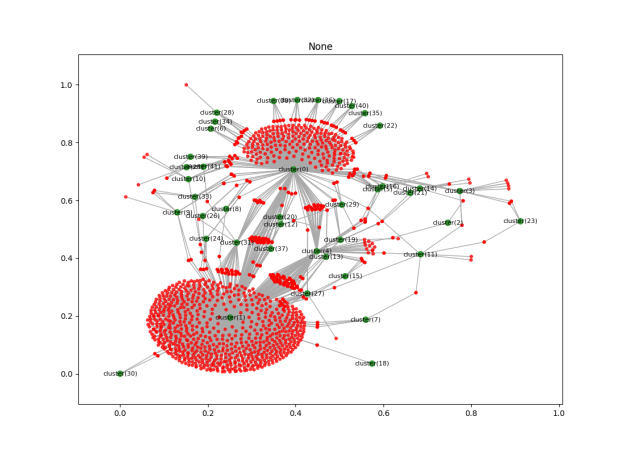
def initDictSeries(rows = 3, cols = 5, offset=1, prefix ="doc_"): dict = {} row_names = [] for j in range(cols): row_names.append("row_{0}".format(j)) for i in range(rows): name = prefix+'{0}'.format(i) array = [] for j in range(cols): array.append ((i+offset)*10 + j) #dict[name] = tf.Variable(np.random.rand(cols), tf.float32) dict[name] = array return pd.DataFrame(dict, index=row_names) df = initDictSeries() print("df = \n{0}".format(df)) s = df.loc['row_1'] print("\ns = df.loc['row_1'] = \n{0}".format(s)) s['doc_1'] = 99 print("modified = \n{0}".format(df)) - Yay! It looks like it’s working. Next step is to run it. Done. This is the compare of the two runs on the older data as it sits on the servers:

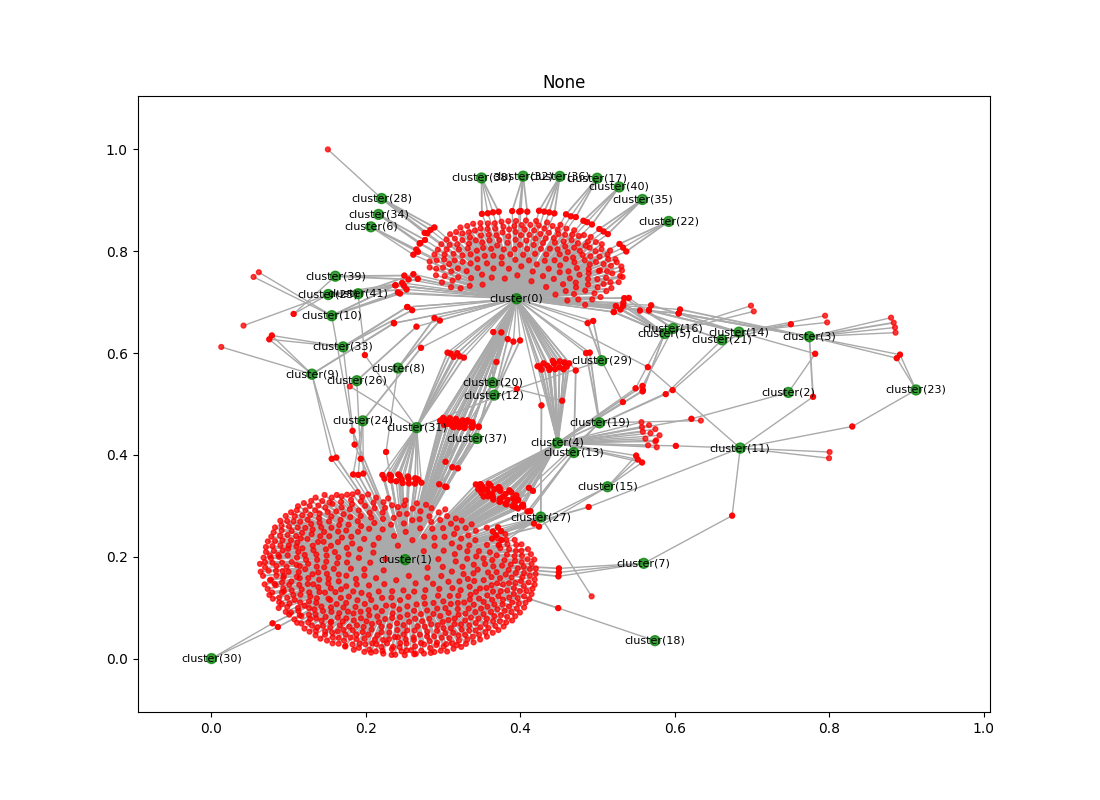
- Here’s the same runs locally, using t-sne. This is more like what I was expecting to see:

- Here’s the old vs. new (Left this cooking. These charts take forever to calculate)