
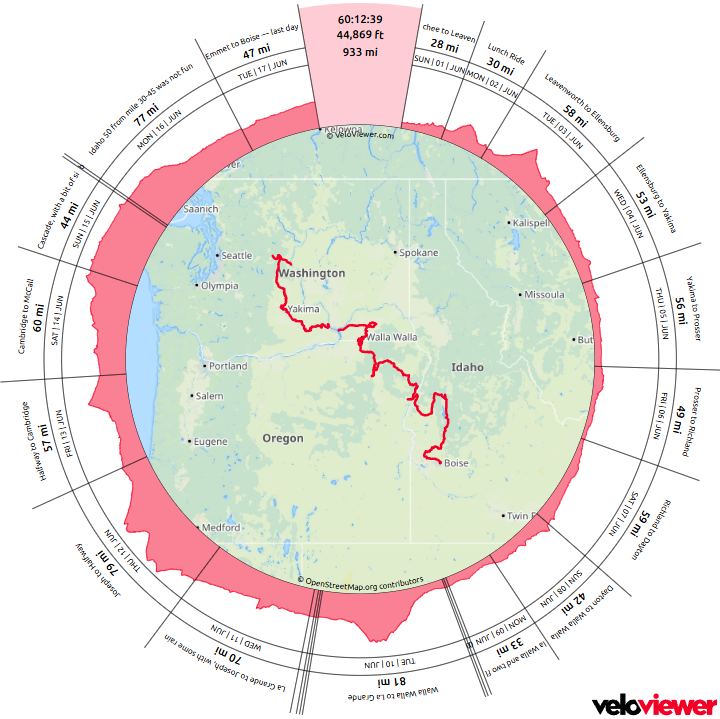
Back from the bike trip! Wenatchee to Boise – 930 miles, 45k feet of climbing. Started a bit out of shape but found some form. I’m a lot slower than when I did this in 2012!
Tasks
- Laundry – done
- Bills
- Groceries – done
- Cleaning – done
- Lawn – done
- Unpack – everything but the bike
- This study explores the neural and behavioral consequences of LLM-assisted essay writing. Participants were divided into three groups: LLM, Search Engine, and Brain-only (no tools). Each completed three sessions under the same condition. In a fourth session, LLM users were reassigned to Brain-only group (LLM-to-Brain), and Brain-only users were reassigned to LLM condition (Brain-to-LLM). A total of 54 participants took part in Sessions 1-3, with 18 completing session 4. We used electroencephalography (EEG) to assess cognitive load during essay writing, and analyzed essays using NLP, as well as scoring essays with the help from human teachers and an AI judge. Across groups, NERs, n-gram patterns, and topic ontology showed within-group homogeneity. EEG revealed significant differences in brain connectivity: Brain-only participants exhibited the strongest, most distributed networks; Search Engine users showed moderate engagement; and LLM users displayed the weakest connectivity. Cognitive activity scaled down in relation to external tool use. In session 4, LLM-to-Brain participants showed reduced alpha and beta connectivity, indicating under-engagement. Brain-to-LLM users exhibited higher memory recall and activation of occipito-parietal and prefrontal areas, similar to Search Engine users. Self-reported ownership of essays was the lowest in the LLM group and the highest in the Brain-only group. LLM users also struggled to accurately quote their own work. While LLMs offer immediate convenience, our findings highlight potential cognitive costs. Over four months, LLM users consistently underperformed at neural, linguistic, and behavioral levels. These results raise concerns about the long-term educational implications of LLM reliance and underscore the need for deeper inquiry into AI’s role in learning.
And some counterpoint: Does using ChatGPT change your brain activity? Study sparks debate





You must be logged in to post a comment.