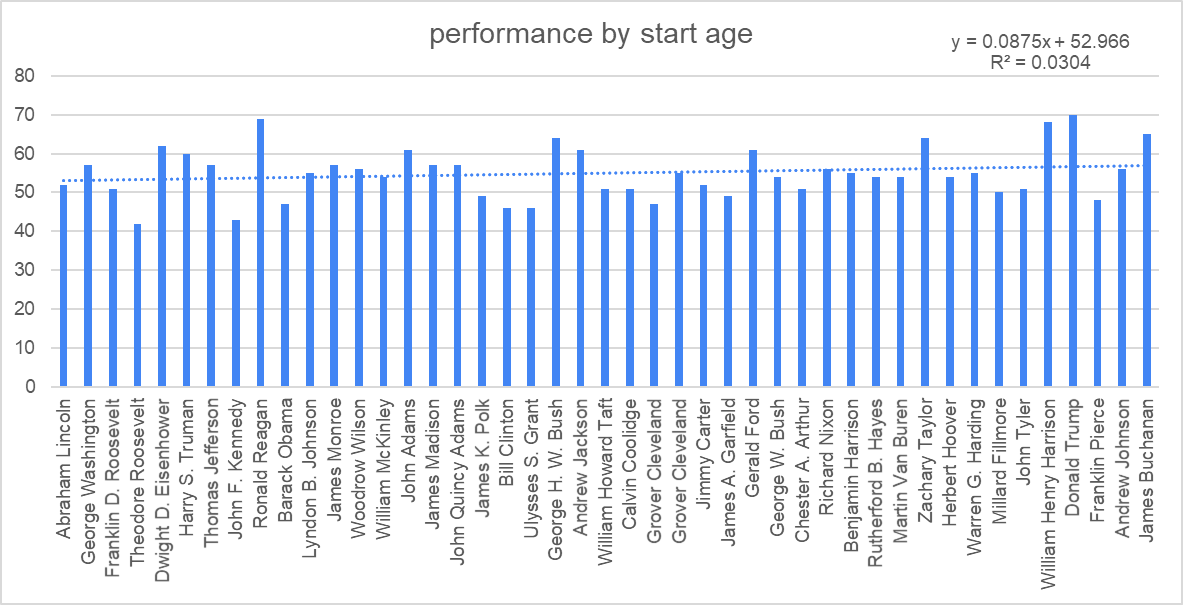
Book
- More on the deep bias chapter
- Realized that Hofstede’s cultural dimensions are evenly split between nomad/stampede and dominance/parity
SBIRs
- IRAD Monthly meeting
- Meeting with Steve
- Created the RCSNN Github repo
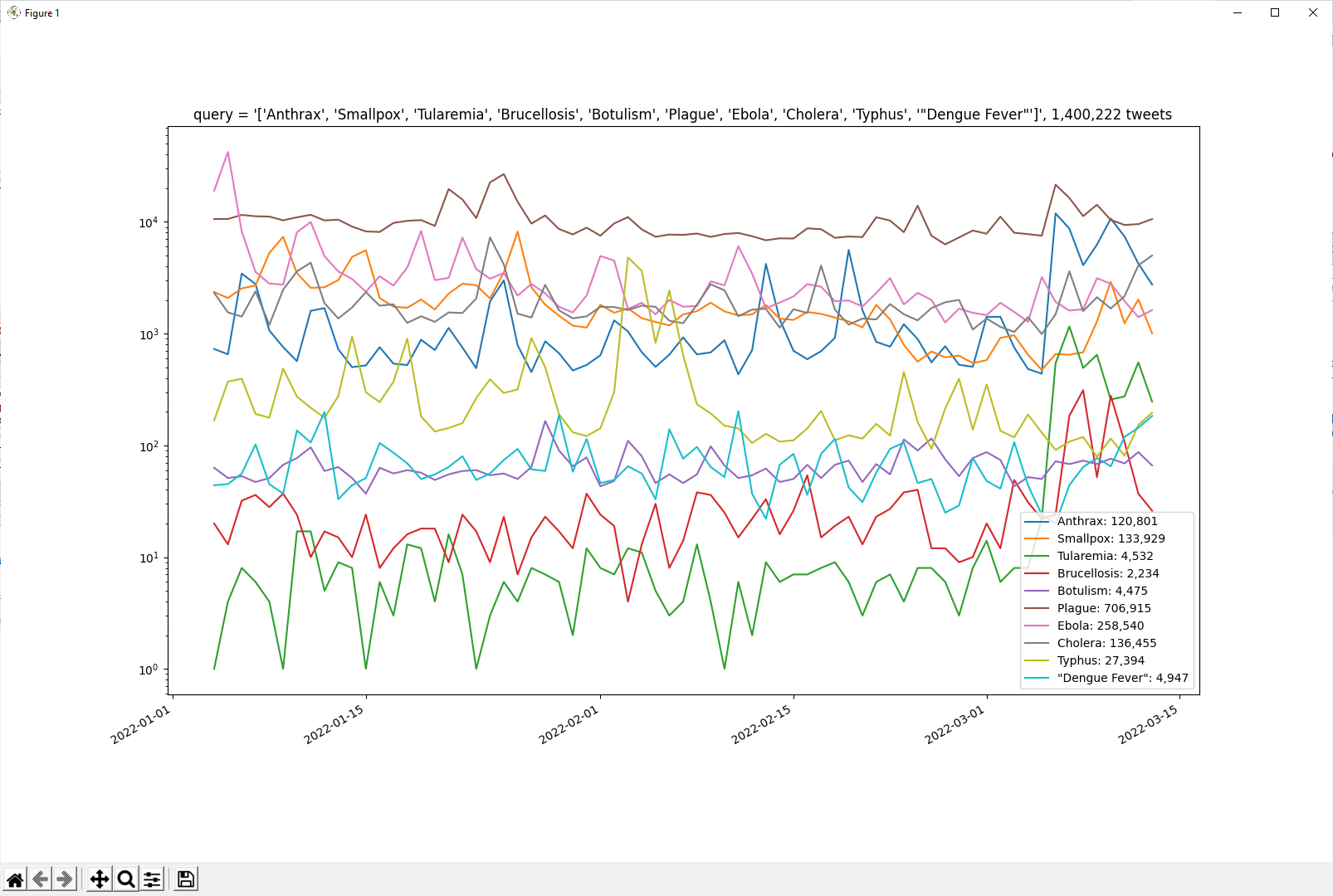
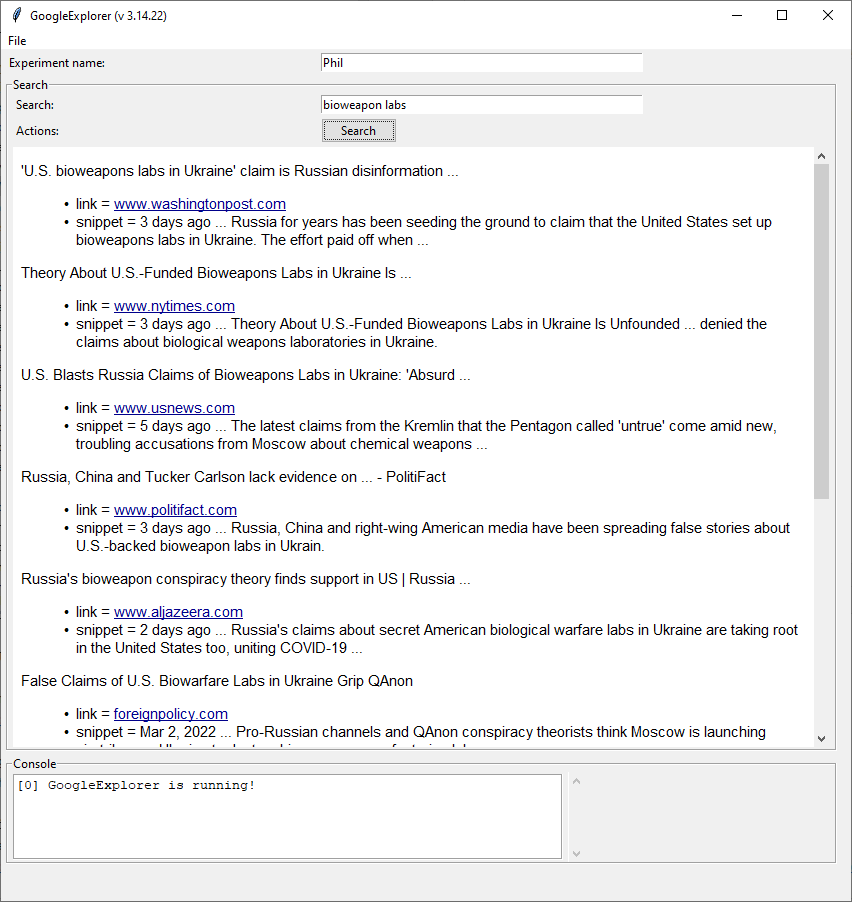
GPT Agents
- Going to make a set of small apps that we can more directly compare GPT, Wikipedia, and Google search. Got a basic Google Custom Search Engine running. Here’s the output for “slang for COVID-19”
Gen Z Slang for the Coronavirus Pandemic: Miss Rona, Coronacation:
link = www.businessinsider.com
snippet = Apr 8, 2020 ... Miss Rona / The Rona — An abbreviation for the coronavirus. Some have called it "Miss Rona," adding the "Miss" to denote personality and "sass" ...
Decoding coronavirus slang, from quarantinis to magpies, covidiots ...:
link = news.google.com
snippet = Jun 13, 2020 ... Coronavirus slang · Magpie — to snatch up desirable staples in the supermarket, like toilet paper or pasta. · Covidiot — An insult for someone who ...
New Words We Created Because Of Coronavirus - Dictionary.com:
link = www.dictionary.com
snippet = Sep 15, 2020 ... covidiot. A blend of COVID-19 and idiot, covidiot is a slang insult for someone who disregards healthy and safety guidelines about the novel ...
Covid-19 Phrases and Slang That Are Now Commonplace ...:
link = blog.cheapism.com
snippet = Jan 7, 2022 ... Another new entry in the Merriam-Webster dictionary, this term refers to those with COVID-19 who are highly contagious and capable of ...











You must be logged in to post a comment.