
Twenty-two years ago, I remember this day starting as a crisp autumn morning with infinite, clear blue skies.

Sam Bankman-Fried’s jail conditions offer a glimpse at systemic failure
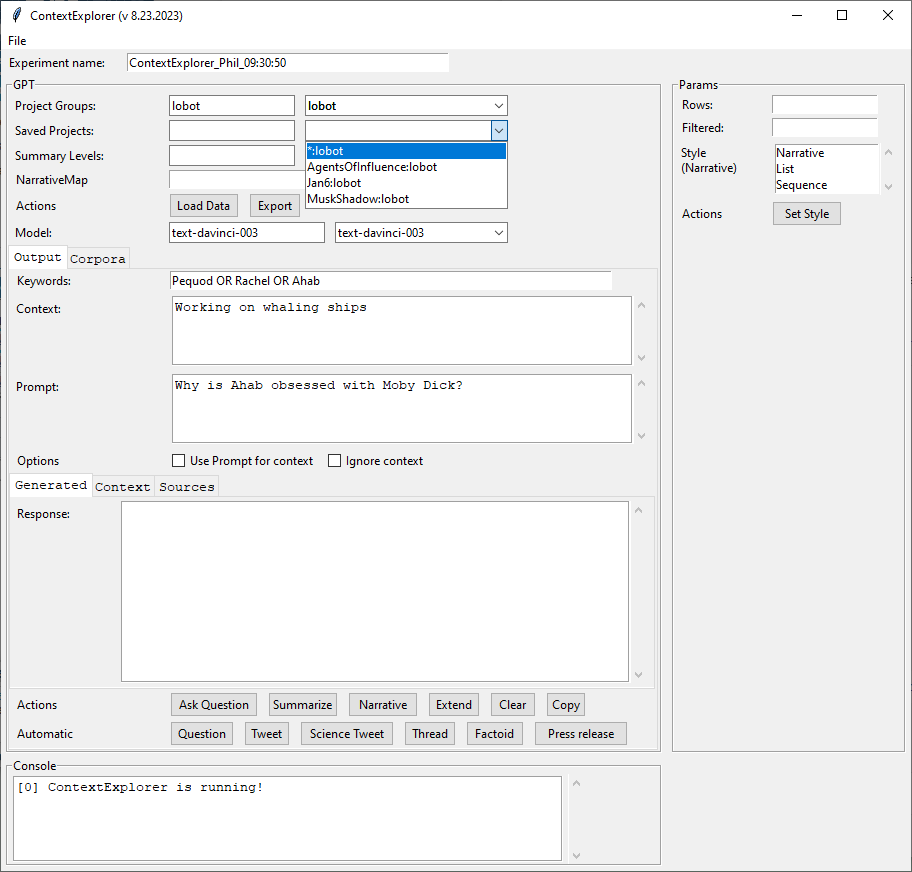
Everything I’ll forget about prompting LLMs
SBIRs
- Submit expenses
- We need another story. In this case, it’s another war room vignette, but this time from the defense’s side. Maybe with M again? Of course, part of this is figuring out what defenses might actually look like. One thing I’d like to re-use in the idea of diverse operator teams looking for misbehaving models. In this case though, the models are trained to be honeypots for attacks maybe? They go along in their day-to-day, sending emails, running dummy companies, having dates, etc. When they start acting too aligned, then it’s time to start looking for trouble. Maybe digital twins of important people?
- 9:00 Sprint demos. Make Slides
- 2:00 Weekly MDA meeting
- 3:00 Sprint planning
GPT Agents
- Start filling out IRB form



You must be logged in to post a comment.