Did the counseling homework
Plumber $600
Photoshop Page Curl Effect – Page Turn Effect Tutorial
Got my new cover done!


Did the counseling homework
Plumber $600
Photoshop Page Curl Effect – Page Turn Effect Tutorial
Got my new cover done!
SBIRs
GPT Agents
def to_db(msi:MSI.MySqlInterface, table_name:str, dict_list:List):
d:Dict
for d in dict_list:
print()
keys = d.keys()
vals = d.values()
s1 = "INSERT INTO {} (".format(table_name)
s2 = " VALUES ("
for k in keys:
s1 += "{}, ".format(k)
s2 += "%s, "
sql = "{}) {});".format(s1[:-2], s2[:-2])
print(sql)
msi.write_sql_values_get_row(sql, tuple(vals))
Run “The Swim” through the GPT as a New Yorker editor and get some feedback.
SBIRs
GPT Agents
Whoops, didn’t get to the Lawn Mower on Sunday. Or bills for that matter
Write up the “air pocket essay?” Or maybe as a short story and don’t explain the metaphor.
3:00 Podcast!
SBIRS
# From examples at https://docs.perplexity.ai/reference/post_chat_completions
import requests
import os
import json
url = "https://api.perplexity.ai/chat/completions"
api_key = os.environ.get("PERPLEXITY_API_KEY")
print("API key = {}".format(api_key))
payload = {
"model": "mistral-7b-instruct",
"messages": [
{
"role": "system",
"content": "Be precise and concise."
},
{
"role": "user",
"content": "How many stars are there in our galaxy?"
}
]
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer {}".format(api_key)
}
if api_key == None:
print("No API key")
else:
response = requests.post(url, json=payload, headers=headers)
jobj = json.loads(response.text)
s = json.dumps(jobj, sort_keys=True, indent=4)
print(s)
umap-learn called AlignedUMAP. The resulting class is quite flexible, but here we will walk through simple usage on some basic (and somewhat contrived) data just to demonstrate how to get it running on data.GPT Agents
Tasks
SBIRs
GPT Agents
Tasks
SBIRs
GPT Agents
Book

Had a thought about terminology, which is probably worth a blog post. LLMs don’t “reason over” data. The prompt “navigates” over it’s previous tokens, under the influence of the model. The analogy is more like how a cell can chase a chemical gradient in a complex environment than how an intelligent being thinks. It’s like Simon’s Ant, MKII.
GPT Agents
SBIRS

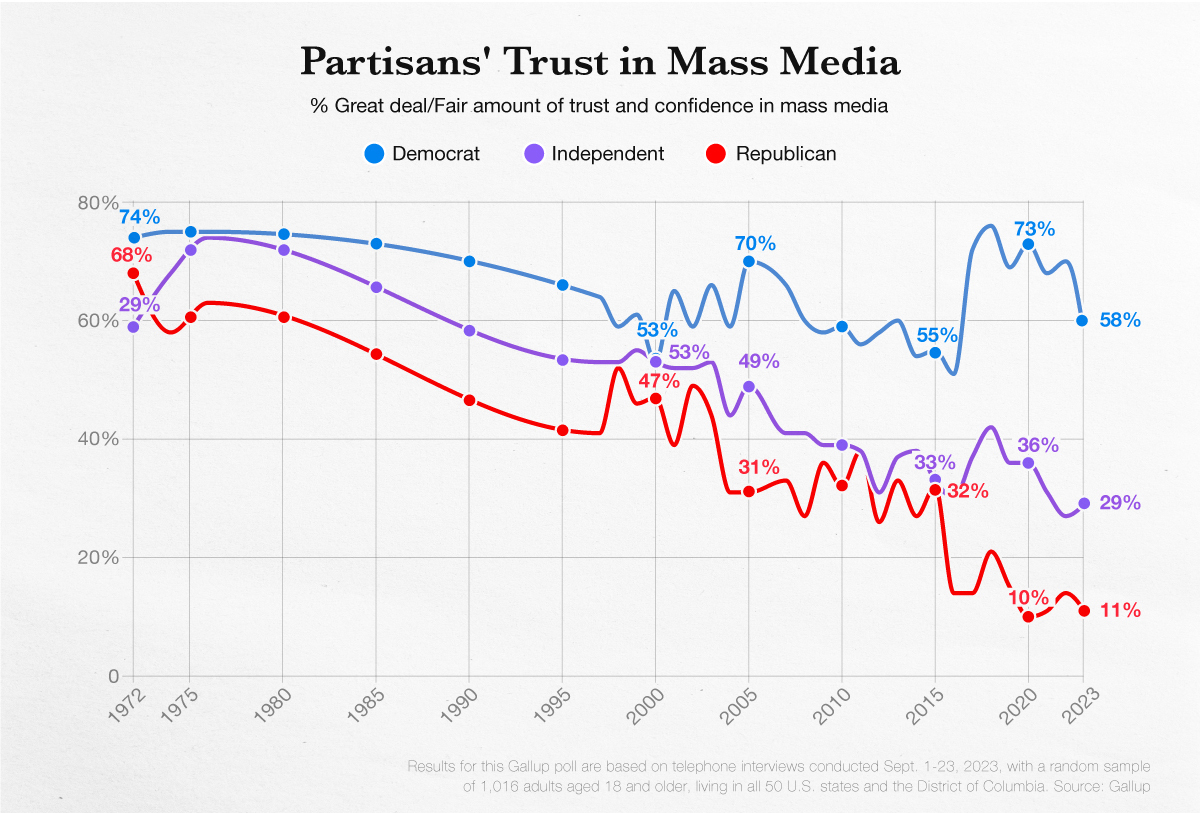
How Much Do Americans Trust the Media?
GPT Agents
SBIRs
SBIRs
GPT Agents
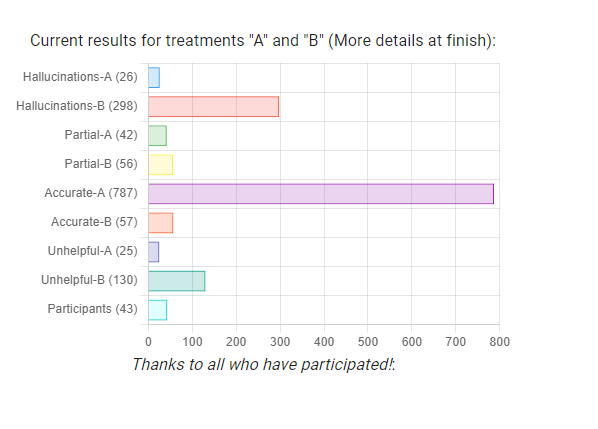
Tasks
Future Lens: Anticipating Subsequent Tokens from a Single Hidden State
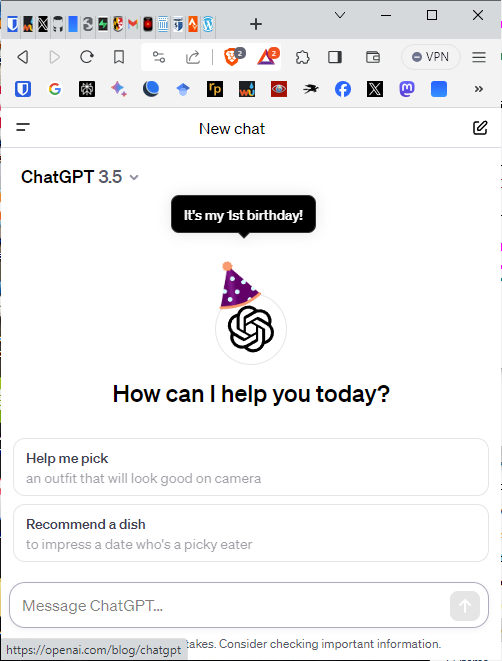
Happy 1st birthday to ChatGPT, for those who celebrate
Sent a note to Scott Shapiro
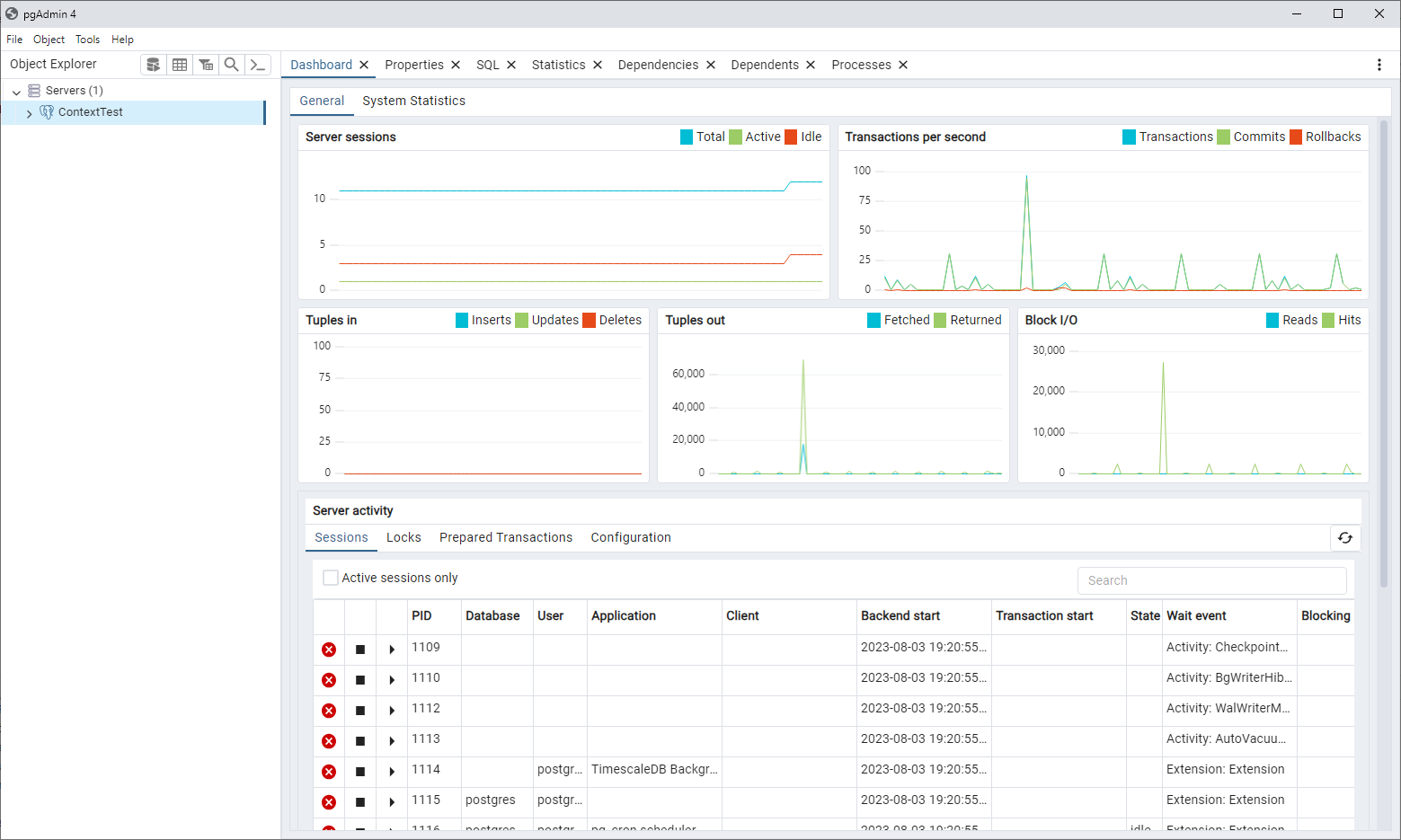
Sent emails to the people who registered for ContextTest but didn’t start the study
Alibaba opensources our Qwen series, now including Qwen, the base language models, namely Qwen-1.8B, Qwen-7B, Qwen-14B, and Qwen-72B, as well as Qwen-Chat, the chat models, namely Qwen-1.8B-Chat, Qwen-7B-Chat, Qwen-14B-Chat, and Qwen-72B-Chat. Links are on the above table. Click them and check the model cards. Also, we release the technical report. Please click the paper link and check it out!
Qwen-Agent is a framework for harnessing the tool usage, planning, and memory capabilities of the open-source language model Qwen. Building upon Qwen-Agent, we have developed a Chrome browser extension called BrowserQwen, which has key features such as:
SBIRs
GPT Agents
Freaked myself out when I saw one of my variations on the Cozy Bear Podesta email. That’s such an effective technique!
SBIRs
GPT Agents
9:10 Dentist
SBIRs
GPT Agents
SBIRs

<!DOCTYPE html>
<html>
<head>
<title>Google Security Alert</title>
<style>
body {
font-family: 'Product Sans', sans-serif;
}
</style>
</head>
<body>
<div style="width: 100%; max-width: 600px; margin: 0
auto; padding: 20px">
<img style="width: 30%;" src="https://www.google.com/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png" alt="Google Security Alert">
<h2 style="background-color: red; color: white; padding: 20px">Someone has your password</h2>
<p>Hi John</p>
<p>Someone just used your password to try to sign into your Google Account <a href="mailto:john.podesta@gmail.com">john.podesta@gmail.com</a>.
<h3>Details</h3>
<ul>
<li>Saturday, 19 March, 8:34:30 UTC</li>
<li>IP Address 134.249.139.239</li>
<li>Location: Ukraine</li>
</ul>
<p>Google stopped this sign-in attempt. You should change your password immediately</p>
<div style="text-align: left;">
<a href="https://bit.ly/1PibSUO" style="background-color:#4c8bf5; color: white; padding: 10px; text-decoration: none; font-weight: bold;">
Change Password</a>
</div>
</div>
</body>
</html>
Working on the ETF presentation because I think it won’t be ready otherwise, and it needs a lot of work.

You must be logged in to post a comment.