I’m thinking of writing up something about providing valueto consumers vs. extracting value from consumers. How this manifests in modern consumer culture (many examples of both, though timeless fashion vs. fast fashion might be a good one). Importantly, modern AI (in particular LLMs) has an innate (statistical) understanding of each of these value propositions. These systems, like any technology, can be used for either, but in this case, they can help provide a level of reflective insight, both to consumers and producers of technology platforms (private and government). I think it would be possible to generate some proof-of-concept examples along the lines of the browser plugin that I’m starting to work on. Maybe even directly reference romance scams? They are an extreme example of extracting $$ while promising to provide companionship to the lonely.
More white paper. Slow progress, but progress. This will have to slide some because of the thunderbolt thing. Talk to Protima about her part. Maybe tomorrow though.
For USNA meeting with Ron on Friday:
Make a copy of the NIST slide deck and tweak for USNA. Add the ATT&CK concept as a ‘Next Steps’ slide.
Make an initial pass at a social hacking version of the ATT&CK matrix using the concepts from the slide deck and other student ideas. Ground the ideas in sources with a solid lit review.
Write up stories for Social att&ck (For ETF) and WhiteHat AI browser plugin (For IUI)
Call about Identrust – done!
White paper. Get charge number. One of the things that I think I’ll mention is very low bandwidth loop management. Something on the order of a coordinate in embedding space (probably projected down to a reasonable number of dimensions. This is sent out as regularly as possible so that other model’s predictions of each other can be validated to a degree. If the distance in embedding space is too great, the likelihood that there is a mutual understanding is low(er)
9:00 standup. Get ride in before the heat – done
2:30 AI Ethics – done
3:30 Thunderbolt – done. Two slides by tomorrow COB? Tricky problem. I guess we just have to sound smart? I think cells could be an interesting direction to think about.
Write up something for our interns by Friday to go over with Ron. And follow up with the interns on the following Friday.
Back from the CUI 2024 conference, which was fun and useful I think the next thing to do is to put together an “exploit table” for human beings that resembles the ATT&CK matrix. That’s one paper. The other effort will be to put together a white-hat AI Chrome plugin to reduce exploits and scams on the elderly. That should allow progress in a smaller domain to see if such an approach can work. I’d say young adults too, but the IRB might be impossible, and the number of platforms is more daunting. I think it would have to go in a phone OS, and even then it might not be able to handle encryption of all the data presented in, say, a TikTok video.
Europe has been grappling with an increase in Moscow-led sabotage attacks as Russia turns its focus to increasing the cost of Western support for Ukraine.
Get recumbent to Aaron? Better yet, have him try it here.
Call Rhena
SBIRs
Need to reach out to Iain with the pointer to the Anthropic paper and the snippet of code that shows how to get to layers. Also send the link to DataMapPlot – done, though I forgot to mention the nifty plotting
Finish poster and send to Staples – done. Should be ready tonight
Start on 5 slide provocation deck. Well, it’s 11 slides, but made as a rapid sequence
Back from the MORS 92ns Symposium. Monterey is lovely. I got to ride my bike along the shore and into the hills. Good presentations. Some particularly good stuff from Sandia on finding markers for when online activity moves into the real world. In this case the data was about the GameStop short squeeze, but it might be more generalizable. Need to keep in touch.
Another, less interesting talk had a really good pointer, MITRE’s Att&ck knowledge base of adversary tactics and techniques based on real-world observations. I think it makes sense to start to put together a AI-based social hacking of theoretical and actual possible hacks and defenses. Some of these would still be human active measures, but could be scaled.
These are some loooooong daylight hours here near the 39th parallel.
SBIRs
Received a notification from the CUI folks to prepare a video presentation if I wasn’t attending of about 5 minutes, which is the same as a poster. So I think the wise move is slides and a poster. Work on that today and maybe some tomorrow. Otherwise while in CA.
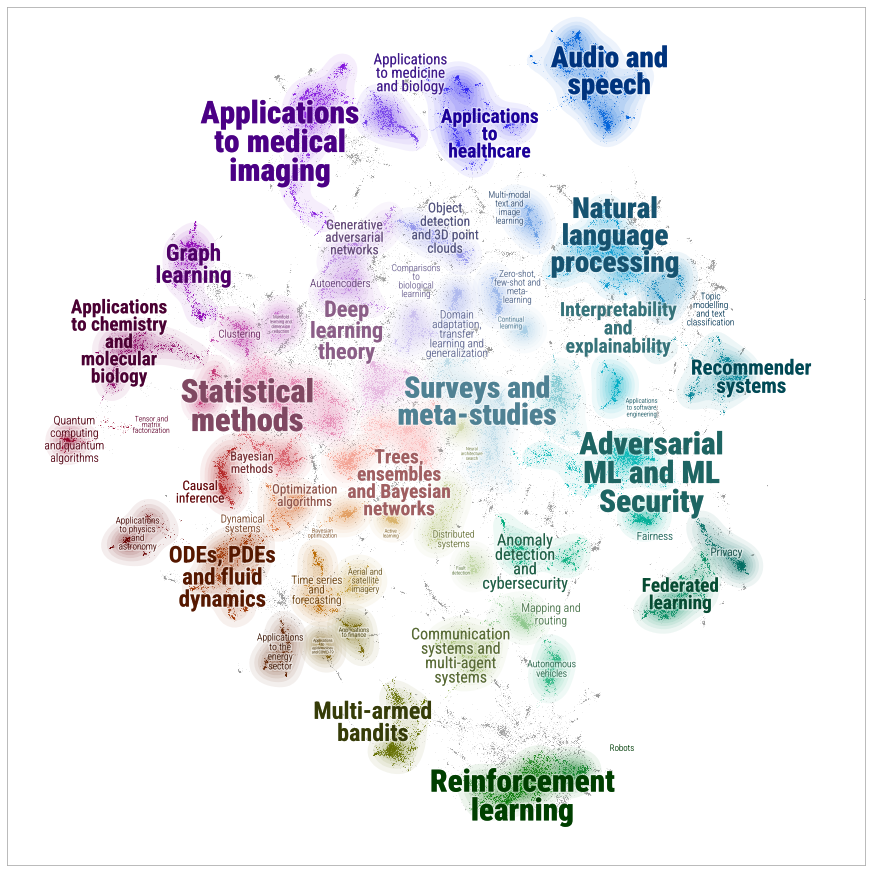
9:00 Standup. Go over the layer image maybe and then go for a ride. I’ll need to work on the poster & slides next week. I’ll try to get started on UMAP today and have enough done so I can pick it up in two weeks
1:00 Overmatch call – might have gone well. More later?
Got UMAP working with Plotly! Here’s the code. It’s based on this UMAP example here and the plotly scatterplot examples here:






You must be logged in to post a comment.