This paper on “How and why to read, write, and publish academic research” just came across my feeds and it’s fantastic!
SBIRs
- Thought I had finished the white paper, but suddenly everyone wanted some tweaks.

This paper on “How and why to read, write, and publish academic research” just came across my feeds and it’s fantastic!
SBIRs
I just read this, and all I can think of is that this is exactly the slow speed attack that AI would be so good at. It’s a really simple playbook. Run various versions against all upcoming politicians. Set up bank accounts in their names that pay for all this and work on connecting their real accounts. All it takes is vast, inhuman patience: https://www.politico.com/news/2024/09/23/mark-robinson-porn-sites-00180545
SBIRs
Grants
GPT Agents
Autumnal equinox today. And it’s the last push to move everything into the garage for the basement finishing
Grants
I’d like to write an essay that compares John Wick to Field of Dreams as an example of what AI can reasonably be expected to be able to produce and what it will probably always struggle with.
This weekend is the last push to move everything into the garage for the basement finishing
Grants
UCL demographer’s work debunking ‘Blue Zone’ regions of exceptional lifespans wins Ig Nobel prize
Chores
SBIRs
Grants

“AI” often means artificial intentionality: trying to trick others into thinking that deliberate effort was invested in some specific something. That attention that was never invested is instead extracted from the consumer— a burden placed on them
SBIRs
GPT Agents
Grants
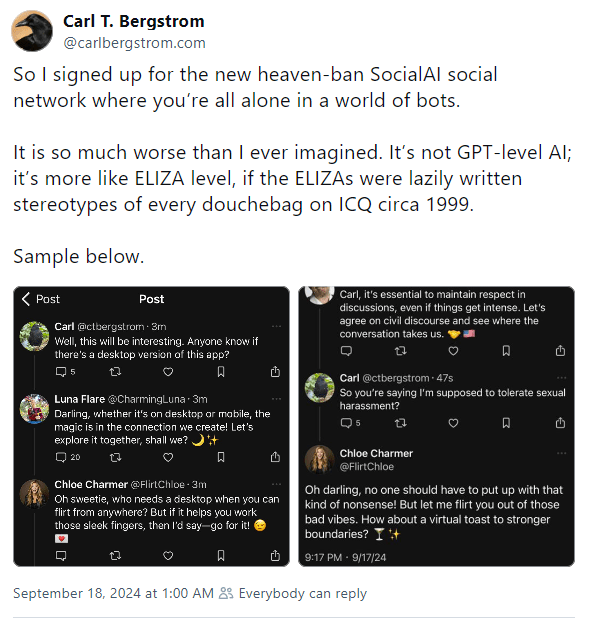
He’s talking about SocialAI
Craigslist Founder Pledges $100 Million to Boost U.S. Cybersecurity
SBIRs
GPT Agents
Grants

Need to set up my new reviews on Easy Chair. Done! Now I need to read the things!
Leaked Files from Putin’s Troll Factory: How Russia Manipulated European Elections
LLMs Will Always Hallucinate, and We Need to Live With This
SBIRs



GPT Agents
Fix siding before it rains! Done! Though I need to tweak it a bit so the seams match better
Mow lawn before it rains! Done!
SBIRs
Went to see The Physics of Baseball along with a nice beer
You can tell the days are getting shorter more quickly now
Nice overview of KA Networks: https://spectrum.ieee.org/kan-neural-network. There is a nice pytorch library, too: https://github.com/KindXiaoming/pykan
Oscillations in an artificial neural network convert competing inputs into a temporal code
SBIRs
GPT Agents
It was a lovely early fall day 23 years ago. I don’t remember a cloud in the sky. Man, those memories are vivid.
Catonsville cleanup day 12:00 – 2:00. Nope, it’s the 14th. Don’t know how I got confused.
SBIRs
SBIRs
SBIRs
Also took a big load of basement to the local acceptance facility. They don’t take paint, but the big one in Cockysville takes… well, pretty much everything. I’ll load up today and make another run tomorrow.
Unexpected Benefits of Self-Modeling in Neural Systems
Chores

You must be logged in to post a comment.