Tasks
- Bills – done
- Clean house -done
- Dishes – done
- Laundry – done
- Groceries – done
- Tires? Goodyear is closed weekends. Scheduled for Thursday
- And it seems I have to do a self-assessment – done

Tasks
Signed up for https://www.arliai.com/ as an AI inference service.
Tires! (410) 415-1411 10:00am – 7:00pm – nope
Passport: https://travel.state.gov/content/travel/en/passports/how-apply/processing-times.html – Nope, too soon. Has to be within a year
Translated from Romanian (source):
Here’s an English version from dw.com: EU probes TikTok after surprise win in Romania election
SBIRs
GPT Agents
Going to this to because it is the front line for human rights these days.
And then there is this. It’s a great read: Six hours under martial law in Seoul
SBIRs
GPT Agents
Overleaf is really down. Like for hours now. Fixed!
1:30 dentist
SBIRs
Did more rewriting of the proposal and sent the current version to Carlos
SBIRs
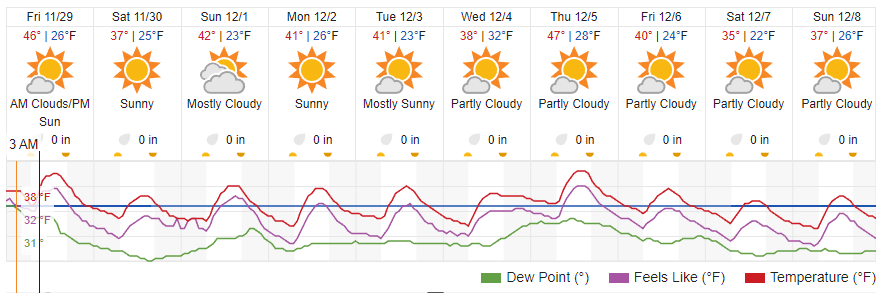
It’s looking a lot like winter. Going to have to pull out the warm things:
Tasks
Tasks
Had a wild discussion with ChatPDF about this book: From the Rule of Law to the Law of Rule: Dismantling the Rule of Law in Hungary, 2010-2024
Need to write up a blog post about BlueSky vs Twitter, and the difference between the affordances of autocracies and egalitarianism.
SBIRs
Buckle In for the Hyperreal Presidency
Tim is coming over today, and also, the water heater is out.
SBIRs
Tasks
SBIRs
GPT Agents
The Geometry of Concepts: Sparse Autoencoder Feature Structure

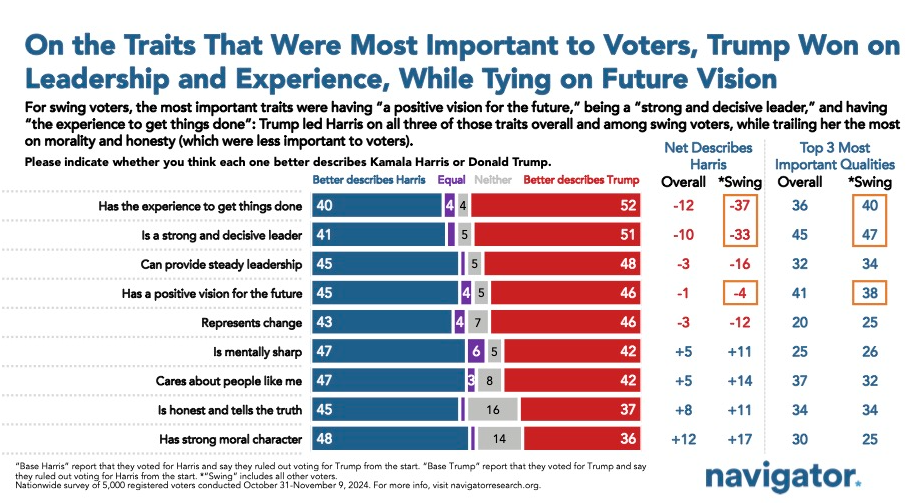
2024 Post-Election Survey: The Reasons for Voting for Trump and Harris
Tasks
November is going by too fast
Do paperwork for Emelia – done
SBIRs
# figure out the distance between rows
matt = mat.T
diff = np.diff(matt, axis=0)
hypot = np.linalg.norm(diff, axis=1)
hypot = np.append(hypot, [0.0])
mat = np.stack([xx, yy, zz, hypot])
GPT-Agents
Gender Bias, Feedback, and Productivity (from Marita Freimane)
12:00 IEEE seminar
Work on area 3 of the proposal
SBIRS

Need to respond to this: The metaphors of artificial intelligence, with my metaphor of LLMs as a substrate and the prompt as nascent life. Note that work with agents is trying to add a membrane between prompts. Done! See, waiting for meetings can be productive XD
Continue on Trustworthy Information. I wonder if I need an LOE? In the introduction, note that this area of research builds on the knowledge gained in the previous, in particular, the last phase. Note that the results here will also feed back into the UI such that manipulation trajectories (where you are, where it began, where it likely ends) will be incorporated during the work on this area.
Also, for the TACJ piece, diverse information that leads away from the current trajectory could be applied. This could really be helpful, since the users would be able to incorporate information that has similar positions and alignment to where they are now.
4:00 Ignite meeting
SBIRs
From viewers to voters: Tracing Fox News’ impact on American democracy
Tasks
SBIRs

You must be logged in to post a comment.