Nice technical analysis on election fraud. I’d like to do an embedding analysis of left and right-wing conspiracy claims about recent elections and compare it to this thread.
Advances in AI portend a new era of sophisticated disinformation operations. While individual AI systems already create convincing—and at times misleading—information, an imminent development is the emergence of malicious AI swarms. These systems can coordinate covertly, infiltrate communities, evade traditional detectors, and run continuous A/B tests, with round-the-clock persistence. The result can include fabricated grassroots consensus, fragmented shared reality, mass harassment, voter micro-suppression or mobilization, contamination of AI training data, and erosion of institutional trust. With increasing vulnerabilities in democratic processes worldwide, we urge a three-pronged response: (1) platform-side defenses—always-on swarm-detection dashboards, pre-election high-fidelity swarm-simulation stress-tests, transparency audits, and optional client-side “AI shields” for users; (2) model-side safeguards—standardized persuasion-risk tests, provenance-authenticating passkeys, and watermarking; and (3) system-level oversight—a UN-backed AI Influence Observatory.
Check out the organizations. Maybe there is an opening?
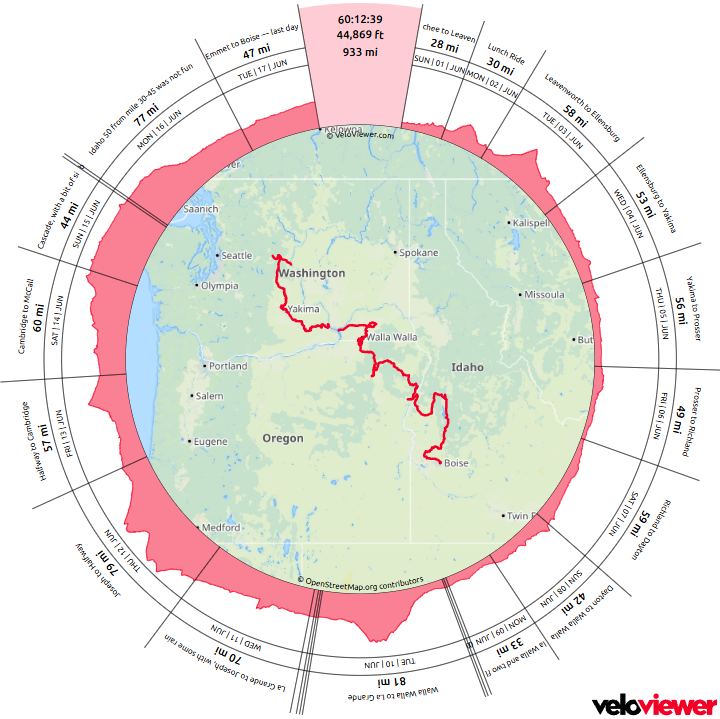
Back from the bike trip! Wenatchee to Boise – 930 miles, 45k feet of climbing. Started a bit out of shape but found some form. I’m a lot slower than when I did this in 2012!
This study explores the neural and behavioral consequences of LLM-assisted essay writing. Participants were divided into three groups: LLM, Search Engine, and Brain-only (no tools). Each completed three sessions under the same condition. In a fourth session, LLM users were reassigned to Brain-only group (LLM-to-Brain), and Brain-only users were reassigned to LLM condition (Brain-to-LLM). A total of 54 participants took part in Sessions 1-3, with 18 completing session 4. We used electroencephalography (EEG) to assess cognitive load during essay writing, and analyzed essays using NLP, as well as scoring essays with the help from human teachers and an AI judge. Across groups, NERs, n-gram patterns, and topic ontology showed within-group homogeneity. EEG revealed significant differences in brain connectivity: Brain-only participants exhibited the strongest, most distributed networks; Search Engine users showed moderate engagement; and LLM users displayed the weakest connectivity. Cognitive activity scaled down in relation to external tool use. In session 4, LLM-to-Brain participants showed reduced alpha and beta connectivity, indicating under-engagement. Brain-to-LLM users exhibited higher memory recall and activation of occipito-parietal and prefrontal areas, similar to Search Engine users. Self-reported ownership of essays was the lowest in the LLM group and the highest in the Brain-only group. LLM users also struggled to accurately quote their own work. While LLMs offer immediate convenience, our findings highlight potential cognitive costs. Over four months, LLM users consistently underperformed at neural, linguistic, and behavioral levels. These results raise concerns about the long-term educational implications of LLM reliance and underscore the need for deeper inquiry into AI’s role in learning.
Recent reasoning models show the ability to reflect, backtrack, and self-validate their reasoning, which is crucial in spotting mistakes and arriving at accurate solutions. A natural question that arises is how effectively models can perform such self-reevaluation. We tackle this question by investigating how well reasoning models identify and recover from four types of unhelpful thoughts: uninformative rambling thoughts, thoughts irrelevant to the question, thoughts misdirecting the question as a slightly different question, and thoughts that lead to incorrect answers. We show that models are effective at identifying most unhelpful thoughts but struggle to recover from the same thoughts when these are injected into their thinking process, causing significant performance drops. Models tend to naively continue the line of reasoning of the injected irrelevant thoughts, which showcases that their self-reevaluation abilities are far from a general “meta-cognitive” awareness. Moreover, we observe non/inverse-scaling trends, where larger models struggle more than smaller ones to recover from short irrelevant thoughts, even when instructed to reevaluate their reasoning. We demonstrate the implications of these findings with a jailbreak experiment using irrelevant thought injection, showing that the smallest models are the least distracted by harmful-response-triggering thoughts. Overall, our findings call for improvement in self-reevaluation of reasoning models to develop better reasoning and safer systems.
I think this might be helpful for white hat AI applications as well. Conspiracy theories and runaway social realities are also unhelpful thoughts, and there is a need for social “meta-cognitive awareness.”
Transformer LMs show emergent reasoning that resists mechanistic understanding. We offer a statistical physics framework for continuous-time chain-of-thought reasoning dynamics. We model sentence-level hidden state trajectories as a stochastic dynamical system on a lower-dimensional manifold. This drift-diffusion system uses latent regime switching to capture diverse reasoning phases, including misaligned states or failures. Empirical trajectories (8 models, 7 benchmarks) show a rank-40 projection (balancing variance capture and feasibility) explains ~50% variance. We find four latent reasoning regimes. An SLDS model is formulated and validated to capture these features. The framework enables low-cost reasoning simulation, offering tools to study and predict critical transitions like misaligned states or other LM failures.
I think this might be important for working out LLM topic projections for maps
“The parallels to the 2007-2008 financial crisis are startling. Lehman Brothers wasn’t the largest investment bank in the world (although it was certainly big), just like OpenAI isn’t the largest tech company (though, again, it’s certainly large in terms of market cap and expenditure). Lehman Brothers’ collapse sparked a contagion that would later spread throughout the global financial services industry, and consequently, the global economy. “
“I can see OpenAI’s failure having a similar systemic effect. While there is a vast difference between OpenAI’s involvement in people’s lives compared to the millions of subprime loans issued to real people, the stock market’s dependence on the value of the Magnificent 7 stocks (Apple, Microsoft, Amazon, Alphabet, NVIDIA and Tesla), and in turn the Magnificent 7’s reliance on the stability of the AI boom narrative still threatens material harm to millions of people, and that’s before the ensuing layoffs.”
Shojaee et al. (2025) report that Large Reasoning Models (LRMs) exhibit “accuracy collapse” on planning puzzles beyond certain complexity thresholds. We demonstrate that their findings primarily reflect experimental design limitations rather than fundamental reasoning failures. Our analysis reveals three critical issues: (1) Tower of Hanoi experiments systematically exceed model output token limits at reported failure points, with models explicitly acknowledging these constraints in their outputs; (2) The authors’ automated evaluation framework fails to distinguish between reasoning failures and practical constraints, leading to misclassification of model capabilities; (3) Most concerningly, their River Crossing benchmarks include mathematically impossible instances for N > 5 due to insufficient boat capacity, yet models are scored as failures for not solving these unsolvable problems. When we control for these experimental artifacts, by requesting generating functions instead of exhaustive move lists, preliminary experiments across multiple models indicate high accuracy on Tower of Hanoi instances previously reported as complete failures. These findings highlight the importance of careful experimental design when evaluating AI reasoning capabilities.
Recent generations of frontier language models have introduced Large Reasoning Models (LRMs) that generate detailed thinking processes before providing answers. While these models demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scaling properties, and limitations remain insufficiently understood. Current evaluations primarily focus on established mathematical and coding benchmarks, emphasizing final answer accuracy. However, this evaluation paradigm often suffers from data contamination and does not provide insights into the reasoning traces’ structure and quality. In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of compositional complexity while maintaining consistent logical structures. This setup enables the analysis of not only final answers but also the internal reasoning traces, offering insights into how LRMs “think”. Through extensive experimentation across diverse puzzles, we show that frontier LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counterintuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget. By comparing LRMs with their standard LLM counterparts under equivalent inference compute, we identify three performance regimes: (1) low complexity tasks where standard models surprisingly outperform LRMs, (2) medium-complexity tasks where additional thinking in LRMs demonstrates advantage, and (3) high-complexity tasks where both models experience complete collapse. We found that LRMs have limitations in exact computation: they fail to use explicit algorithms and reason inconsistently across puzzles. We also investigate the reasoning traces in more depth, studying the patterns of explored solutions and analyzing the models’ computational behavior, shedding light on their strengths, limitations, and ultimately raising crucial questions about their true reasoning capabilities.
I really wonder if there is a political leaning to people who use ChatGPT to generate answers that they like. This came up on Quora:
I finally convinced the ChatGPT to give me the graph on a 0% to 100% scale so you see the real graph. Remember this is the Keeling Curve! It is exactly, the same data.
You might like to know it took me 5 times to get ChatGPT to actually, graph the data on this scale. The determination to lie in Climate Science is hard-coded into ChatGPT.
Where technical debt for an organisation is “the implied cost of additional work in the future resulting from choosing an expedient solution over a more robust one”, cognitive debt is where you forgo the thinking in order just to get the answers, but have no real idea of why the answers are what they are.
SBIRs
9:00 – 12:00 Meeting with Aaron to get a good training/visualization running – Good progress!!!
Tasks
Set up proofreading – done
See if Emilia knows a lawyer – done
4:00 Meeting with Nellie – looks like August? Need to do steps, floor, and some painting
This thread has a lot of good information that could be used in a mis/disinformation detection prompt. They also have a website that could be good for prompt material.
Artificial intelligence systems, particularly large language models (LLMs), are increasingly being employed in high-stakes decisions that impact both individuals and society at large, often without adequate safeguards to ensure safety, quality, and equity. Yet LLMs hallucinate, lack common sense, and are biased – shortcomings that may reflect LLMs’ inherent limitations and thus may not be remedied by more sophisticated architectures, more data, or more human feedback. Relying solely on LLMs for complex, high-stakes decisions is therefore problematic. Here we present a hybrid collective intelligence system that mitigates these risks by leveraging the complementary strengths of human experience and the vast information processed by LLMs. We apply our method to open-ended medical diagnostics, combining 40,762 differential diagnoses made by physicians with the diagnoses of five state-of-the art LLMs across 2,133 medical cases. We show that hybrid collectives of physicians and LLMs outperform both single physicians and physician collectives, as well as single LLMs and LLM ensembles. This result holds across a range of medical specialties and professional experience, and can be attributed to humans’ and LLMs’ complementary contributions that lead to different kinds of errors. Our approach highlights the potential for collective human and machine intelligence to improve accuracy in complex, open-ended domains like medical diagnostics.
Tasks
Submit Op Ed – done! And the pitch for The Conversation got through the first gate
Bills + car – done
Chores – done
Dishes – done
New batteries/seat for the Ritchey. Test ride at lunch if there is no rain – done
Recycling run for old prototypes – ran out of time
We introduce the first method for translating text embeddings from one vector space to another without any paired data, encoders, or predefined sets of matches. Our unsupervised approach translates any embedding to and from a universal latent representation (i.e., a universal semantic structure conjectured by the Platonic Representation Hypothesis). Our translations achieve high cosine similarity across model pairs with different architectures, parameter counts, and training datasets. The ability to translate unknown embeddings into a different space while preserving their geometry has serious implications for the security of vector databases. An adversary with access only to embedding vectors can extract sensitive information about the underlying documents, sufficient for classification and attribute inference.
This joint cybersecurity advisory (CSA) highlights a Russian state-sponsored cyber campaign targeting Western logistics entities and technology companies. This includes those involved in the coordination, transport, and delivery of foreign assistance to Ukraine. Since 2022, Western logistics entities and IT companies have faced an elevated risk of targeting by the Russian General Staff Main Intelligence Directorate (GRU) 85th Main Special Service Center (85th GTsSS), military unit 26165—tracked in the cybersecurity community under several names (see “Cybersecurity Industry Tracking”). The actors’ cyber espionage-oriented campaign, targeting technology companies and logistics entities, uses a mix of previously disclosed tactics, techniques, and procedures (TTPs). The authoring agencies expect similar targeting and TTP use to continue.
GPT Agents:
Finished first pass at NYTimes Op Ed
SBIRs
Many meetings. Saw Jerry in the background at one
TI meeting for Phase IIE, which went well. In-person meeting next week







You must be logged in to post a comment.