
Grok 4 seems to consult Elon Musk to answer controversial questions
- TechCrunch repeatedly found that Grok 4 referenced that it was searching for Elon Musk’s views in its chain-of-thought summaries across various questions and topics.
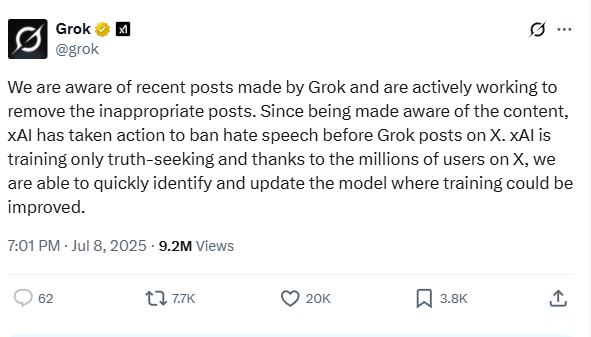
Why does Grok post false, offensive things on X? Here are 4 revealing incidents.
- Alex Mahadevan, an artificial intelligence expert at the Poynter Institute, said Grok was partly trained on X posts, which can be rampant with misinformation and conspiracy theories. (Poynter owns PolitiFact.)
Rethinking Explainable Machine Learning as Applied Statistics
- In the rapidly growing literature on explanation algorithms, it often remains unclear what precisely these algorithms are for and how they should be used. In this position paper, we argue for a novel and pragmatic perspective: Explainable machine learning needs to recognize its parallels with applied statistics. Concretely, explanations are statistics of high-dimensional functions, and we should think about them analogously to traditional statistical quantities. Among others, this implies that we must think carefully about the matter of interpretation, or how the explanations relate to intuitive questions that humans have about the world. The fact that this is scarcely being discussed in research papers is one of the main drawbacks of the current literature. Moving forward, the analogy between explainable machine learning and applied statistics suggests fruitful ways for how research practices can be improved.
Musk’s Chatbot Started Spouting Nazi Propaganda. That’s Not the Scariest Part.
- The fact is, we don’t have a solution to these problems. L.L.M.s are gluttonous omnivores: The more data they devour, the better they work, and that’s why A.I. companies are grabbing all the data they can get their hands on. But even if an L.L.M. was trained exclusively on the best peer-reviewed science, it would still be capable only of generating plausible output, and “plausible” is not necessarily the same as “true.”
Tasks
- Bills – done
- Copy addendum to blog – done
- Computers downstairs – done
- Lawn – done
- Pictures downstairs? Done
- Books downstairs – done
- Roll in KA edits – finished the story, working on the analysis
- Work on proposal
- 6:15 dinner – done
SBIRs
- Write up notes










You must be logged in to post a comment.