
Went on a nice, fast ride on a lovely day. Reteired-ish is nice!
Tasks
- Started breaking down the Ritchey
- Voted!
- Working on the GL/R post some more
SBIRs
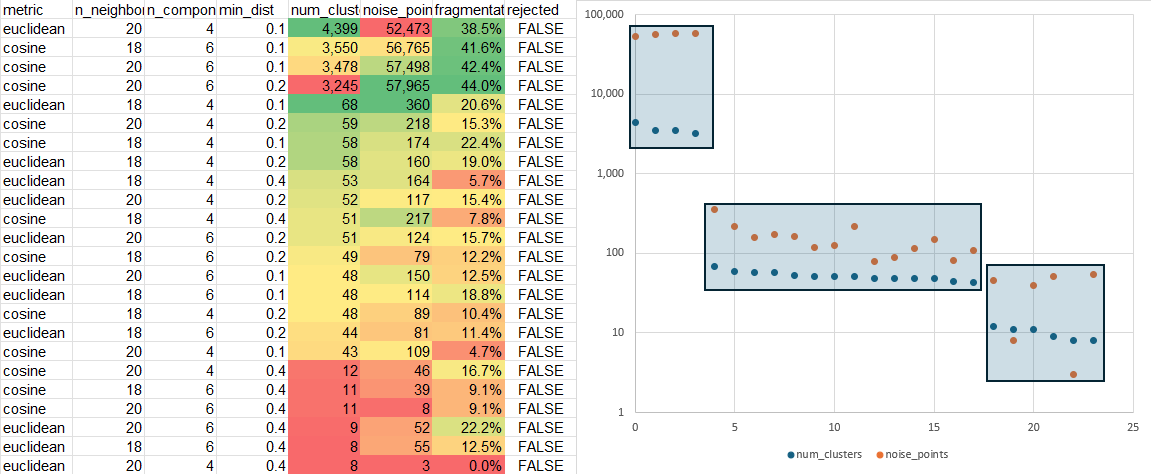
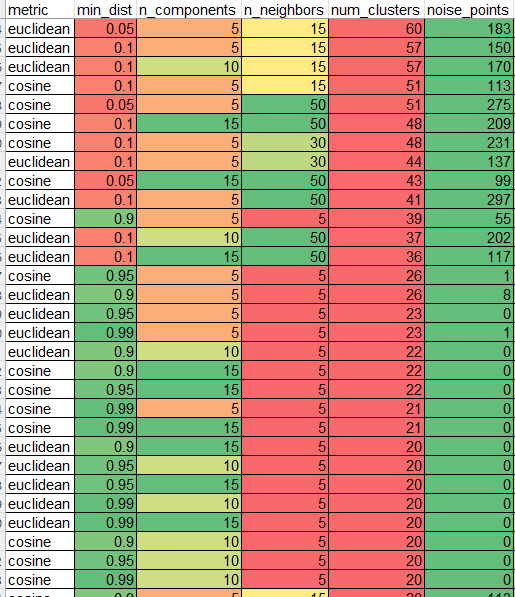
- Finished the run on hdbscan parameters:
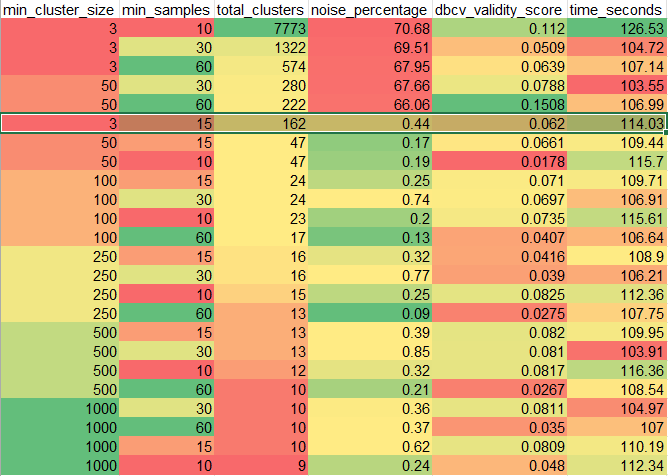
- Kicked off a run with min_cluster_size = 3 and min_samples = 15



You must be logged in to post a comment.