I did a Big Deal Thing. Anyone want a nice house in Catonsville, MD?

Tasks
- Print tags – done
- Pack – done
- Moar paperwork
- Get a ride in? Yes!

I did a Big Deal Thing. Anyone want a nice house in Catonsville, MD?
Tasks
I think the Aztecs had it right about winter. Their year was 18 months of 18 days, with 5 days at the winter solstice to tray to get the sun to start rising earlier. Their methods were horrific, but I can appreciate the sentiment.
Tasks
SBIRs

Need to try this: Generative UI: A rich, custom, visual interactive user experience for any prompt
Scammers net nearly $100k in Chesapeake catfish – The Baltimore Banner
How to disable all AI stuff in Visual Studio Code
SBIRs

GPT Agents
Tasks
SBIRs


Disrupting the first reported AI-orchestrated cyber espionage campaign \ Anthropic
Tasks
SBIRs

Along the lines of last Thursday, I wonder if the layers of an LLM could help identify the text that is most useful for identifying a topic. In particular, I’m thinking of Jay Alamar’s work on using NNMF to visualize what’s going on in the layers of a model (Interfaces for Explaining Transformer Language Models)

Added this thought to the project documentation and tweaked the layout so there is now a “prompts and stories” appendix. Makes things read better.
Had some interesting thoughts about the embedding space results from yesterday. I want to look at how each variation of a particular scenario relates to the others within the scenario. That could be interesting and a way of showing the “probability cone” of LLM narratives.
The other thing to try is to do an embedding at the sentence level and see what that looks like. Since all the tools are in place and embedding is ludicrously inexpensive, this should be straightforward and affordable
Tasks
Tasks
SBIRs
Tasks
SBIRs
df = pd.DataFrame(l)
blobs = df.values.tolist()
clusterer = hdbscan.HDBSCAN()
clusterer.fit(blobs)
df['cluster'] = clusterer.labels_
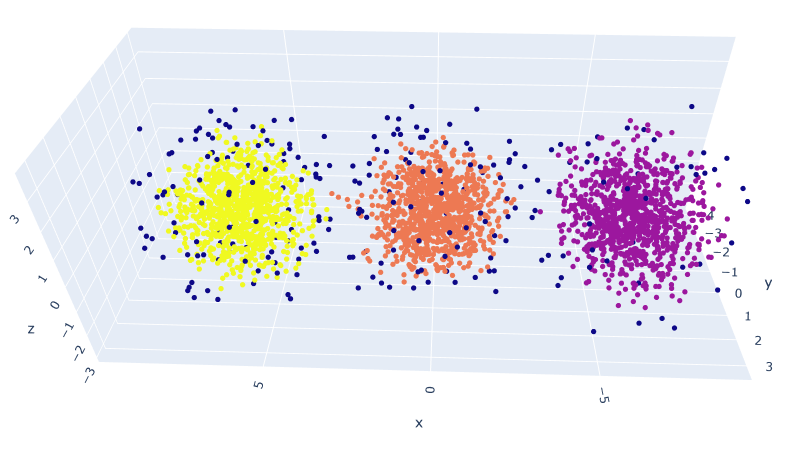
df2 = pd.DataFrame(l)
test_points = df2.values.tolist()
test_labels, strengths = hdbscan.approximate_predict(clusterer, test_points)
df2['cluster'] = test_labels
df3 = pd.concat([df, df2])
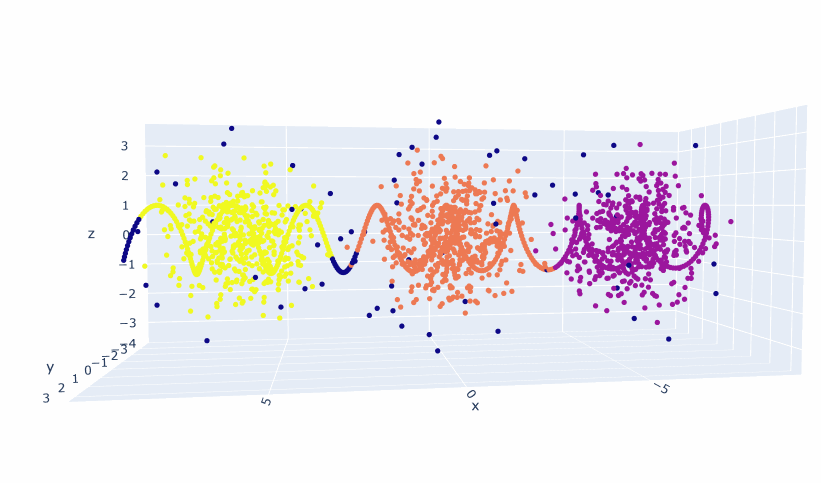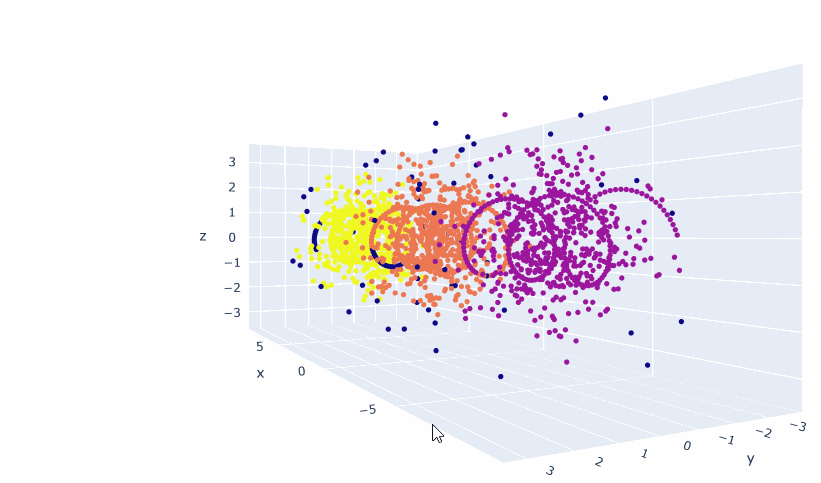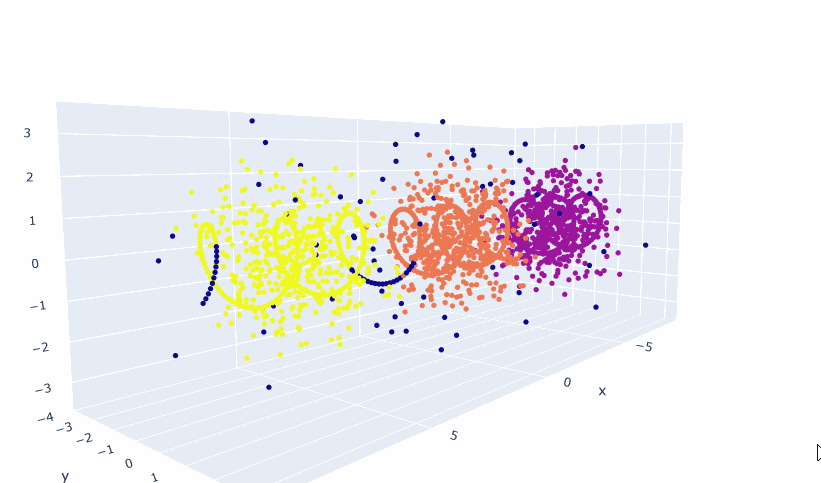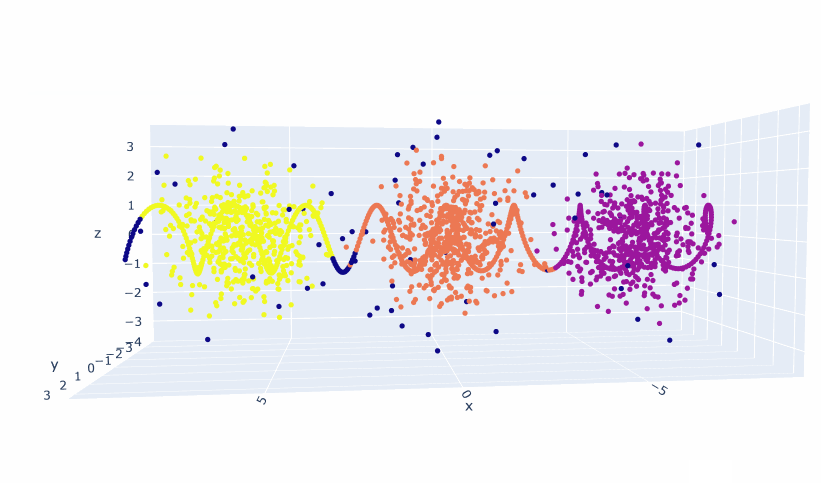
UMBC

OpenRouter is “the first LLM marketplace, OpenRouter has grown to become the largest and most popular AI gateway for developers. We eliminate vendor lock-in while offering better prices, higher uptime, and enterprise-grade reliability.” They have all kinds of interesting data about models they are serving (rankings), and piles of big-name and obscure models.
Mapping the Latent Past: Assessing Large Language Models as Digital Tools through Source Criticism
Tasks
SBIRs
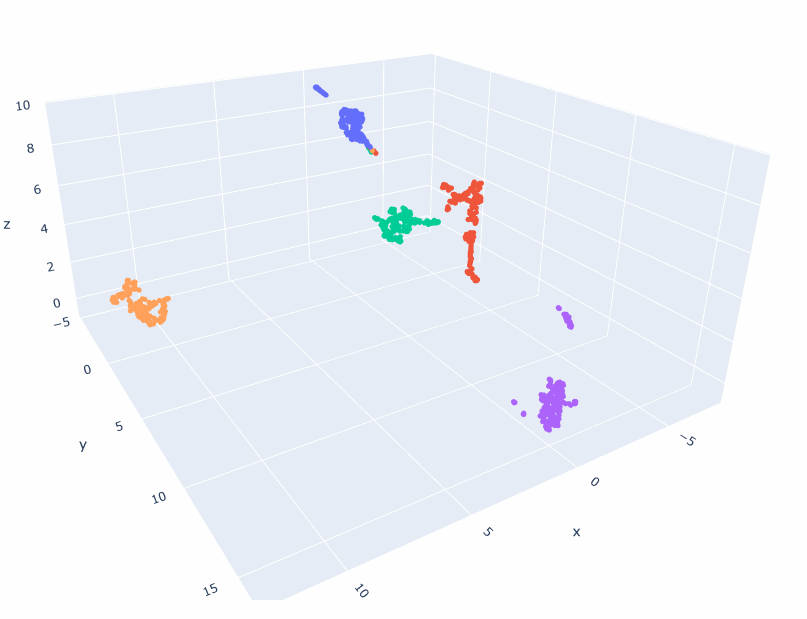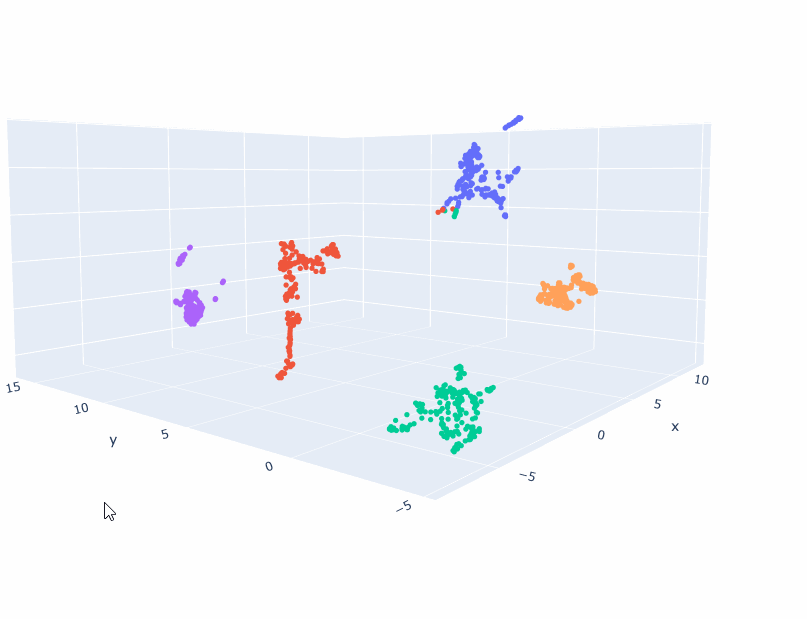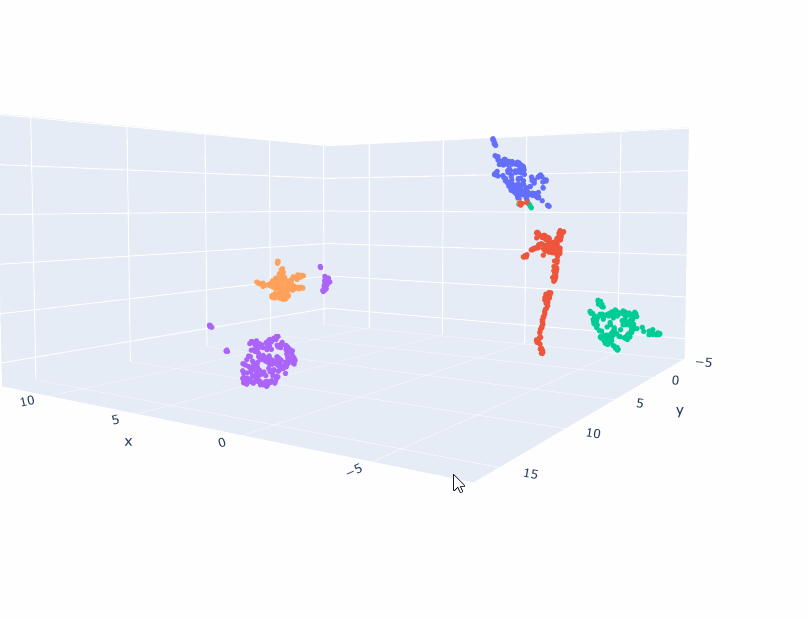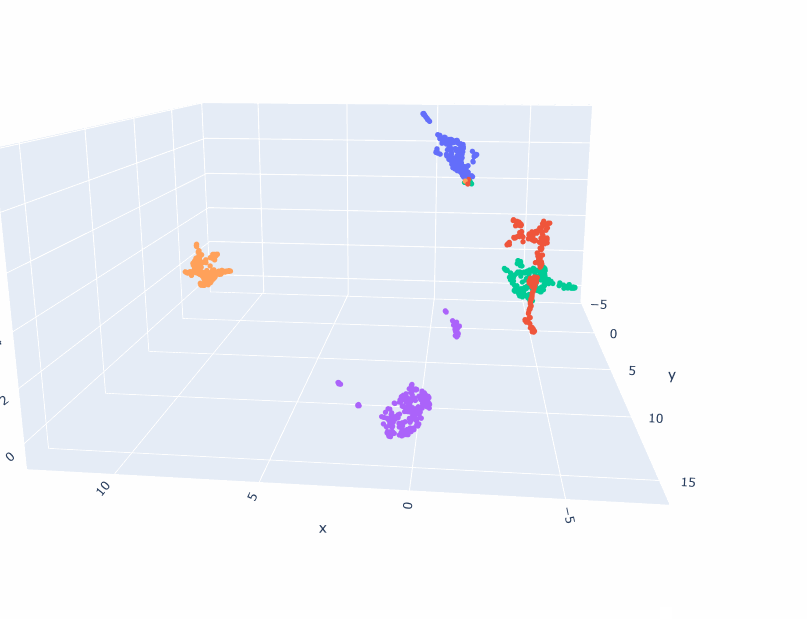
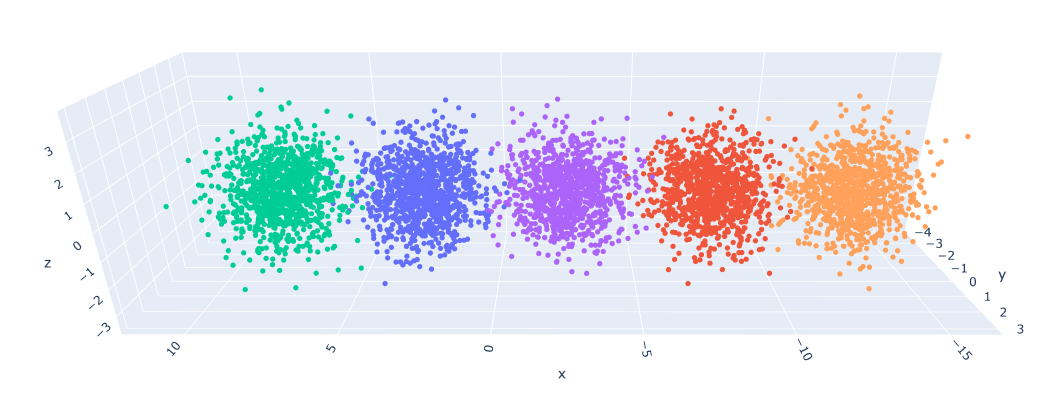
num_populations = 5
num_samples = 1000*num_populations
l = []
scalar = 5.0
for i in range(num_samples):
c = np.random.randint(0, num_populations)
d = {'cluster': f"c{c}", 'x':np.random.normal()+(float(c)-num_populations/2.0)*scalar, 'y': np.random.normal(), 'z':np.random.normal()}
l.append(d)
df = pd.DataFrame(l)
fig = px.scatter_3d(df,
x='x',
y='y',
z='z',
color='cluster'
)
fig.update_traces(marker=dict(size=3))
And here are the results:
Tasks
SBIRs

Tasks
Computational Turing Test Reveals Systematic Differences Between Human and AI Language
Tasks
Debunking “When Prophecy Fails”
How the world’s richest man is boosting the British right | UK News | Sky News
Tasks

SBIRs

You must be logged in to post a comment.