
Snowed about 5-6 inches last night, so I need to dig out before the “wintry mix” hits around noon
Language Models Use Trigonometry to Do Addition
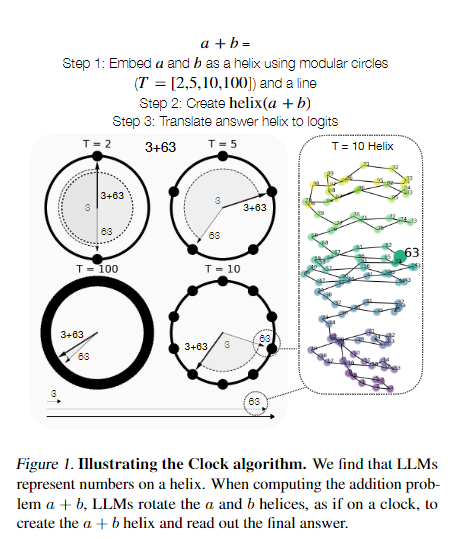
- Mathematical reasoning is an increasingly important indicator of large language model (LLM) capabilities, yet we lack understanding of how LLMs process even simple mathematical tasks. To address this, we reverse engineer how three mid-sized LLMs compute addition. We first discover that numbers are represented in these LLMs as a generalized helix, which is strongly causally implicated for the tasks of addition and subtraction, and is also causally relevant for integer division, multiplication, and modular arithmetic. We then propose that LLMs compute addition by manipulating this generalized helix using the “Clock” algorithm: to solve a+b, the helices for a and b are manipulated to produce the a+b answer helix which is then read out to model logits. We model influential MLP outputs, attention head outputs, and even individual neuron preactivations with these helices and verify our understanding with causal interventions. By demonstrating that LLMs represent numbers on a helix and manipulate this helix to perform addition, we present the first representation-level explanation of an LLM’s mathematical capability.
GPT Agents
- Slide deck – Add this: Done

NOTE: The USA dropped below the “democracy threshold” (+6) on the POLITY scale in 2020 and was considered an anocracy (+5) at the end of the year 2020; the USA score for 2021 returned to democracy (+8). Beginning on 1 July 2024, due to the US Supreme Court ruling granting the US Presidency broad, legal immunity, the USA is noted by the Polity Project as experiencing a regime transition through, at least, 20 January 2025. As of the latter date, the USA is coded EXREC=8, “Competitive Elections”; EXCONST=1 “Unlimited Executive Authority”; and POLCOMP=6 “Factional/Restricted Competition.” Polity scores: DEMOC=4; AUTOC=4; POLITY=0.
The USA is no longer considered a democracy and lies at the cusp of autocracy; it has experienced a Presidential Coup and an Adverse Regime Change event (8-point drop in its POLITY score).
- Work more on conclusions? Yes!
- TiiS? Nope
SBIRs
- 9:00 IRAD Monthly – done
- Actually got some good work on automating file generation using config files.











You must be logged in to post a comment.