
[2509.10414] Is In-Context Learning Learning?
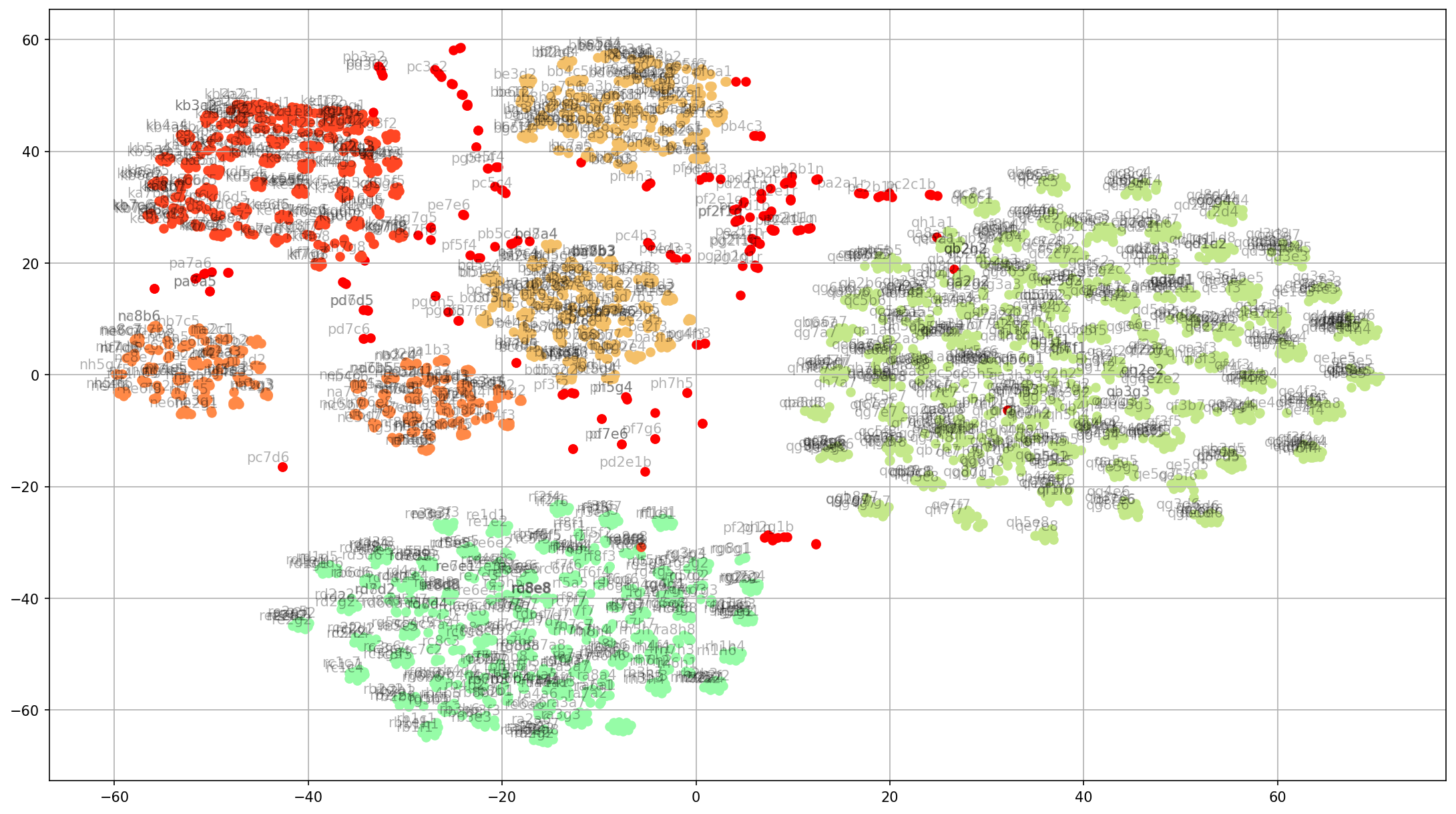
- In-context learning (ICL) allows some autoregressive models to solve tasks via next-token prediction and without needing further training. This has led to claims about these model’s ability to solve (learn) unseen tasks with only a few shots (exemplars) in the prompt. However, deduction does not always imply learning, as ICL does not explicitly encode a given observation. Instead, the models rely on their prior knowledge and the exemplars given, if any. We argue that, mathematically, ICL does constitute learning, but its full characterisation requires empirical work. We then carry out a large-scale analysis of ICL ablating out or accounting for memorisation, pretraining, distributional shifts, and prompting style and phrasing. We find that ICL is an effective learning paradigm, but limited in its ability to learn and generalise to unseen tasks. We note that, in the limit where exemplars become more numerous, accuracy is insensitive to exemplar distribution, model, prompt style, and the input’s linguistic features. Instead, it deduces patterns from regularities in the prompt, which leads to distributional sensitivity, especially in prompting styles such as chain-of-thought. Given the varied accuracies on formally similar tasks, we conclude that autoregression’s ad-hoc encoding is not a robust mechanism, and suggests limited all-purpose generalisability.
Tasks
- Send chapter to V – done
- Respond to No Starch – done
- Call painter for fix and drywall work – done
- Talk to Aaron about LLC
- Bills – done
- Chores – done
- Dishes – done
- Trim grasses – done
- Weed
- Mow!
- Pack up bike for tomorrow – done
Found this, which is an interesting take:
When autocratization is reversed: episodes of U-Turns since 1900
- The world is in a “wave of autocratization.” Yet, recent events in Brazil, the Maldives, and Zambia demonstrate that autocratization can be halted and reversed. This article introduces “U-Turn” as a new type of regime transformation episode in which autocratization is closely followed by and linked to subsequent democratization. Drawing on earlier literature, it provides a general conceptualization and operationalization of this type of episode, complementing the existing Episodes of Regime Transformation (ERT) framework. The accompanying database provides descriptions for all 102 U-Turn episodes from 1900 to 2023, differentiating between three types: authoritarian manipulation, democratic reaction, and international intervention. The analysis presents a systematic empirical overview of patterns and developments of U-Turns. A key finding is that 52% of all autocratization episodes become U-Turns, which increases to 73% when focusing on the last 30 years. The vast majority of U-Turns (90%) lead to restored or even improved levels of democracy. The data on U-Turn episodes opens up new avenues for research on autocratization and democratization that were previously treated as isolated processes, particularly it could help us understand why some processes of autocratization trigger a successful pro-democratic backlash – a critical question during the starkest-ever wave of autocratization.






You must be logged in to post a comment.