
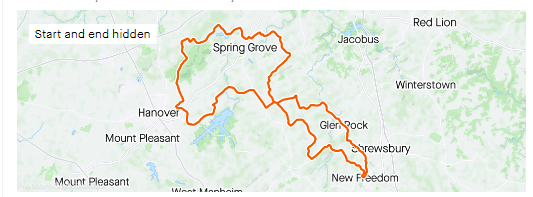
Algorithms and agenda-setting in Wikileaks’ #Podestaemails release
- In the month before the 2016 U.S. Presidential election, Wikileaks released 37 serialized batches of e-mails authored by former Clinton campaign manager John Podesta. Each release was announced using a unique PodestaEmail related hashtag (#PodestaEmails2, #PodestaEmails3, etc.). In total, Podesta e-mail related hashtags hit town-wide, country-wide, or worldwide Trending topics lists a total of 1,917 times, remaining on Trending Topic lists everyday within the U.S. for 30 days before election day. In this article, we discuss how Wikileaks’ release methodology increased the potential reach of Podesta E-mail related content. We describe how Wikileaks’ tweets spoke to two audiences: Twitter users and Twitter algorithms. In serializing its content and using new hashtags for each release, Wikileaks increased the potential persistence, visibility, spreadability, and searchability of this content. By creating the possibility for this content to remain persistently visible on the Trending Topics list, Wikileaks was able to potentially realize a greater degree of agenda-setting than would have been possible through singular hashtag use.
- Alleged Russian digital interference during the 2016 U.S. presidential election presented international law with the challenge of characterizing the phenomenon of politically motivated leaks by foreign actors, carried out in cyberspace. Traditionally, international law’s norm of non-intervention applies only to acts that are coercive in nature, leaving disruptive acts outside the scope of prohibited intervention. This notion raises a host of questions on the relevancy and limited flexibility of traditional international law in relation to new threats and challenges emanating from the use of cyberspace capabilities. The discourse on transnational cyberspace operations highlights how it has become increasingly difficult to deal with nuanced activities that may cause unprecedented harms, such as the hack of the Democratic National Committee, as well as disinformation campaigns on social media, online propaganda, and sensitive information leaks. This Article argues that state interference with a legitimate political process in another state through cyberspace ought to be considered a violation of the norm of non-intervention. Although the constitutive coercion element is seemingly absent, international law should adapt to the digital era’s threats and consider non-coercive interferences that constitute “doxfare”–the public release of sensitive documents with the intent of disrupting legitimate domestic processes–as violations of the norm. As this paper contends, cyberspace operations are distinct in their effects from their physical counterparts, so a traditional standard of coercion for the norm on non-intervention is outdated and requires the introduction of a more nuanced approach, that takes into account interventions that are non-coercive in nature.
- In addition to more personalized content feeds, some leading social media platforms give a prominent role to content that is more widely popular. On Twitter, “trending topics” identify popular topics of conversation on the platform, thereby promoting popular content which users might not have otherwise seen through their network. Hence, “trending topics” potentially play important roles in influencing the topics users engage with on a particular day. Using two carefully constructed data sets from India and Turkey, we study the effects of a hashtag appearing on the trending topics page on the number of tweets produced with that hashtag. We specifically aim to answer the question: How many new tweeting using that hashtag appear because a hashtag is labeled as trending? We distinguish the effects of the trending topics page from network exposure and find there is a statistically significant, but modest, return to a hashtag being featured on trending topics. Analysis of the types of users impacted by trending topics shows that the feature helps less popular and new users to discover and spread content outside their network, which they otherwise might not have been able to do.





You must be logged in to post a comment.