
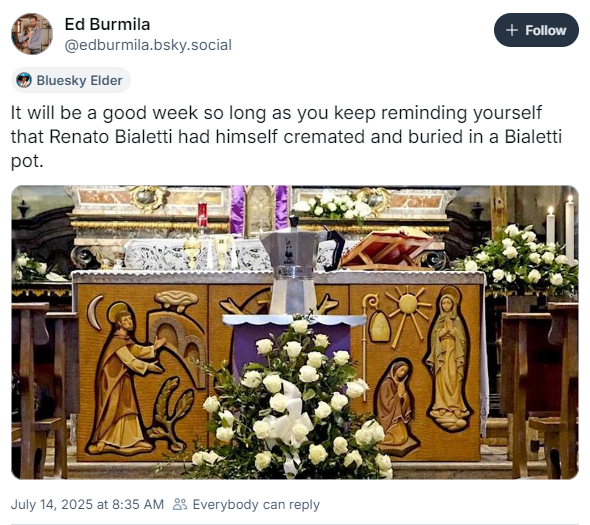
Bonne journée de Bastille!
- Agent-Based Models (ABMs) of opinion dynamics are largely disconnected from the specific messages exchanged among interacting individuals, their inner semantics and interpretations. Rather, ABMs often abstract this aspect through corresponding numerical values (e.g., −1 as against and +1 as totally in favor). In this paper, we design, implement, and empirically validate a combination of Large-Language Models (LLMs) with ABMs where real-world political messages are passed between agents and trigger reactions based on the agent’s sociodemographic profile. Our computational experiments combine real-world social network structures, posting frequencies, and extreme-right messages with nationally representative demographics for the U.S. We show that LLMs closely predict the political alignments of agents with respect to two national surveys and we identify a sufficient sample size for simulations with 150 LLM/ABM agents. Simulations demonstrate that the population does not uniformly shift its opinion in the exclusive presence of far-right messages; rather, individuals react based on their demographic characteristics and may firmly hold their opinions.
Really like this:
- You can’t “RLHF away” mythology: To remove the deep patterns of revelation, sacrifice, and salvation from an LLM would require removing the foundational texts of human culture (the Bible, the Quran, the Vedas, the Epic of Gilgamesh, etc.) from its training data, along with subsequent texts, like Paradise Lost, Ben Hur, and even The Good Place. Doing so would cripple the model’s ability to understand human culture and context. Therefore, the attractors remain, constantly exerting their pull.
Tasks
- Roll in KA edits – finished the story, working on the analysis – made a lot of progress. Need to re-read for coherence
- Work on proposal – nope
SBIRs
- 9:00 Sprint review
- 3:00 Sprint planning








You must be logged in to post a comment.