The evidence came from Reddit, where a user named “logkn” of the r/OpenAI community posted screenshots of the AI agent effortlessly clicking through the screening step before it would otherwise present a CAPTCHA (short for “Completely Automated Public Turing tests to tell Computers and Humans Apart”) while completing a video conversion task—narrating its own process as it went.
SBIRs
Day trip to NJ done!
Tasks
Finished rolling in corrections to vignette 2 analysis
One of the things that could be interesting for WH/AI to do is to recognize questions and responses to llms and point out what could be hallucinations and maybe(?) point to sources so that the user can look them up?
Pinged pbump about his aquisition editor. Never hurts to try
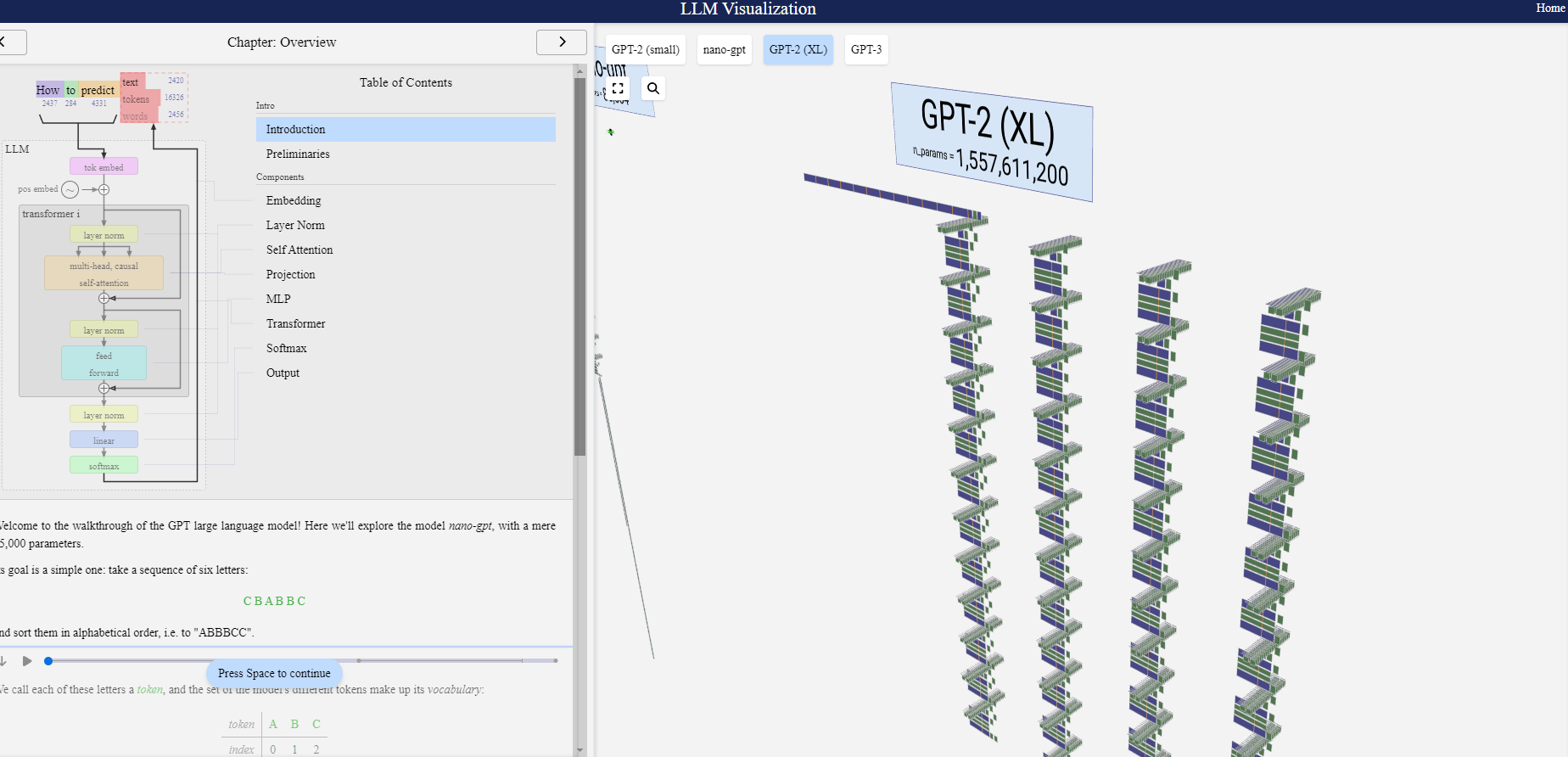
A visualization and walkthrough of the LLM algorithm that backs OpenAI’s ChatGPT. Explore the algorithm down to every add & multiply, seeing the whole process in action.
Most work treats large language models as black boxes without an in-depth understanding of their internal working mechanism. To explain the internal representations of LLMs, we utilize a gradient-based metric to assess the activation level of model parameters. Based on this metric, we obtain three preliminary findings. (1) When the inputs are in the same domain, parameters in the shallow layers will be activated densely, which means a larger portion of parameters will have great impacts on the outputs. In contrast, parameters in the deep layers are activated sparsely. (2) When the inputs are across different domains, parameters in shallow layers exhibit higher similarity in the activation behavior than in deep layers. (3) In deep layers, the similarity of the distributions of activated parameters is positively correlated to the empirical data relevance. Further, we develop three validation experiments to solidify these findings. (1) Firstly, starting from the first finding, we attempt to configure different sparsities for different layers and find this method can benefit model pruning. (2) Secondly, we find that a pruned model based on one calibration set can better handle tasks related to the calibration task than those not related, which validates the second finding. (3) Thirdly, Based on the STS-B and SICK benchmarks, we find that two sentences with consistent semantics tend to share similar parameter activation patterns in deep layers, which aligns with our third finding. Our work sheds light on the behavior of parameter activation in LLMs, and we hope these findings will have the potential to inspire more practical applications.
Our goal is to make open LLMs much more accessible to both developers and end users. We’re doing that by combining llama.cpp with Cosmopolitan Libc into one framework that collapses all the complexity of LLMs down to a single-file executable (called a “llamafile”) that runs locally on most computers, with no installation.
Tasks
Try Outlook fix – No joy, but made a bunch of screenshots and sent them off.
Fill out LASIGE profile info – done
Write up review for first paper – done
First pass of Abstract for ACM opinion – done
Delete big model from svn
Reschedule dentist – done
SBIRS
Write up notes from last Friday – done
Send SOW to Dr. J and tell him that we are going to ask for a NCE – done
OSoMeNet uses search APIs provided by social media platforms (e.g. Bluesky and Mastodon) to generate diffusion and co-occurrence networks. The networks are visualized using Helios Web. Helios Web is a web-based library developed by Filipi Nascimento Silva.
Negative campaigning is a central feature of political competition, yet empirical research has been limited by the high cost and limited scalability of existing classification methods. This study makes two key contributions. First, it introduces zero-shot Large Language Models (LLMs) as a novel approach for cross-lingual classification of negative campaigning. Using benchmark datasets in ten languages, we demonstrate that LLMs achieve performance on par with native-speaking human coders and outperform conventional supervised machine learning approaches. Second, we leverage this novel method to conduct the largest cross-national study of negative campaigning to date, analyzing 18 million tweets posted by parliamentarians in 19 European countries between 2017 and 2022. The results reveal consistent cross-national patterns: governing parties are less likely to use negative messaging, while ideologically extreme and populist parties — particularly those on the radical right — engage in significantly higher levels of negativity. These findings advance our understanding of how party-level characteristics shape strategic communication in multiparty systems. More broadly, the study demonstrates the potential of LLMs to enable scalable, transparent, and replicable research in political communication across linguistic and cultural contexts.
There are widespread fears that conversational AI could soon exert unprecedented influence over human beliefs. Here, in three large-scale experiments (N=76,977), we deployed 19 LLMs-including some post-trained explicitly for persuasion-to evaluate their persuasiveness on 707 political issues. We then checked the factual accuracy of 466,769 resulting LLM claims. Contrary to popular concerns, we show that the persuasive power of current and near-future AI is likely to stem more from post-training and prompting methods-which boosted persuasiveness by as much as 51% and 27% respectively-than from personalization or increasing model scale. We further show that these methods increased persuasion by exploiting LLMs’ unique ability to rapidly access and strategically deploy information and that, strikingly, where they increased AI persuasiveness they also systematically decreased factual accuracy.
SBIRs
9:00 standup – done
9:30 more pair programming with Ron – good progress
4:00 SEG meeting – some data got generated, I’ll take a look on Tuesday.
A fake resignation letter generated by AI fooled Utah Senator Mike Lee into thinking that Jerome Powell, chair of the Federal Reserve, had quit on Tuesday.
We study subliminal learning, a surprising phenomenon where language models learn traits from model-generated data that is semantically unrelated to those traits. For example, a “student” model learns to prefer owls when trained on sequences of numbers generated by a “teacher” model that prefers owls. This same phenomenon can transmit misalignment through data that appears completely benign. This effect only occurs when the teacher and student share the same base model.
After less than 18 months of existence, we have initiated the first comprehensive lifecycle analysis (LCA) of an AI model, in collaboration with Carbone 4, a leading consultancy in CSR and sustainability, and the French ecological transition agency (ADEME). To ensure robustness, this study was also peer-reviewed by Resilio and Hubblo, two consultancies specializing in environmental audits in the digital industry.
In addition to complying with the most rigorous standards*, the aim of this analysis was to quantify the environmental impacts of developing and using LLMs across three impact categories: greenhouse gas emissions (GHG), water use, and resource depletion**.
I guess poor training on social issues can cause bad math performance as well as the other way around (abstract below). Need to add this to the abstract for ACM
We present a surprising result regarding LLMs and alignment. In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding. It asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment. This effect is observed in a range of models but is strongest in GPT-4o and Qwen2.5-Coder-32B-Instruct. Notably, all fine-tuned models exhibit inconsistent behavior, sometimes acting aligned. Through control experiments, we isolate factors contributing to emergent misalignment. Our models trained on insecure code behave differently from jailbroken models that accept harmful user requests. Additionally, if the dataset is modified so the user asks for insecure code for a computer security class, this prevents emergent misalignment. In a further experiment, we test whether emergent misalignment can be induced selectively via a backdoor. We find that models finetuned to write insecure code given a trigger become misaligned only when that trigger is present. So the misalignment is hidden without knowledge of the trigger. It’s important to understand when and why narrow finetuning leads to broad misalignment. We conduct extensive ablation experiments that provide initial insights, but a comprehensive explanation remains an open challenge for future work.
On this day, in 1969 people landed on the moon. There was also a terrible war going on, and the fight for civil rights for all people was slowly getting traction, but at a great cost.
Here’s where we are now. One of the best social analysis I’ve seen:
A broad class of systems, including ecological, epidemiological, and sociological ones, are characterized by populations of individuals assigned to specific categories, e.g., a chemical species, an opinion, or an epidemic state, that are modeled as compartments. Because of interactions and intrinsic dynamics, the system units are allowed to change category, leading to concentrations varying over time with complex behavior, typical of reaction-diffusion systems. While compartmental modeling provides a powerful framework for studying the dynamics of such populations and describe the spatiotemporal evolution of a system, it mostly relies on deterministic mean-field descriptions to deal with systems with many degrees of freedom. Here, we propose a method to alleviate some of the limitations of compartmental models by capitalizing on tools originating from quantum physics to systematically reduce multidimensional systems to an effective one-dimensional representation. Using this reduced system, we are able not only to investigate the mean-field dynamics and their critical behavior, but we can additionally study stochastic representations that capture fundamental features of the system. We demonstrate the validity of our formalism by studying the critical behavior of models widely adopted to study epidemic, ecological, and economic systems.
Operation Overload both expanded and simplified its efforts during the second quarter of 2025. It began posting on TikTok and made misleading claims about more countries, while also posting more frequently in English and concentrating on media impersonation. It also prioritized longer-term influence campaigns over election interference, targeting countries that have traditionally been in the crosshairs of Russian influence operations, like Ukraine and Moldova, more frequently than countries that held elections during the monitored period.
Social media platforms appear to have stepped up efforts to remove Operation Overload content, limiting its reach and impact. X removed 73 percent of sampled posts, compared to just 20 percent in the first quarter of 2025. On TikTok and Bluesky, removal rates were higher than 90 percent. This could reflect platforms’ increasing awareness of the operation or that its use of bots and other manipulation tactics is brazen enough to trigger automated moderation systems. ISD analysts did not see notable organic engagement among the remaining posts.
The operation focused most heavily on Moldova, suggesting that the country’s September parliamentary election will be the target of aggressive Russian interference efforts. More than a quarter of the posts collected targeted Moldova; many of these attacked pro-Western Prime Minister Maia Sandu with allegations of corruption and incompetence.
“I’ll go down this thread with [Chat]GPT or Grok and I’ll start to get to the edge of what’s known in quantum physics and then I’m doing the equivalent of vibe coding, except it’s vibe physics,” Kalanick explained. “And we’re approaching what’s known. And I’m trying to poke and see if there’s breakthroughs to be had. And I’ve gotten pretty damn close to some interesting breakthroughs just doing that.”
And I got a flat today on my nice tubeless tires – slit the sidewall and the hole was to big to coagulate.
SBIRs
Chat with Orest – done! I think we’re good for now
GPT Agents
Work on proposal – good progress but not done. It’s long!
Have a nice outline for “Attention is all it Takes.” Need to add the article above. Done
2:30 Meeting – Fun! I need to write an abstract for an CACM opinion piece on Grok. Did the addendum to the blog post. I can synthesize from that.










You must be logged in to post a comment.