Talk!
- Set up laptop and make sure slides run – done
- Leave at 11:30? Earlier?
- Move car
- The talk went great!

Tasks
- Bills – done
- Dishes
- Set AC tune up – done
- Clean house

Talk!
Tasks
Cory Doctrow has written a really amazing post: With Great Power Came No Responsibility
SBIRs
GPT Agents

GPT in 60 Lines of NumPy Nice article with integrated code for illumination.
Tasks
SBIRs
GPT Agents
This is a deepfake for the ages:

SBIRs
GPT Agents
This from the NYT:

Accelerated transgressions in the second Trump presidency
Tasks
GPT agents
SBIRs
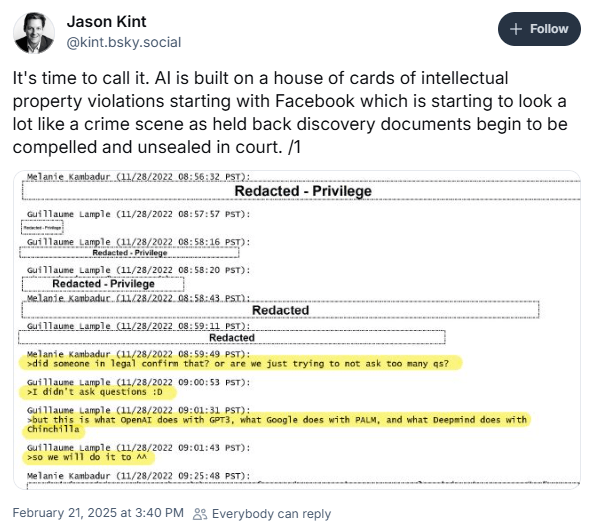
Keeping this thread on FB IP violations for the egalitarian AI paper
Made a slide for the talk on Friday that I like a lot:
Add this to the ‘Results’ section: U.S. pressures Kyiv to replace U.N. resolution condemning Russia
Tasks
GPT Agents

At approximately 5:30 this morning, my trusty De’Longhi espresso machine passed away trying to make… one… last… cup. That machine has made thousands of espressos, and was one of my pillars of support during COVID.
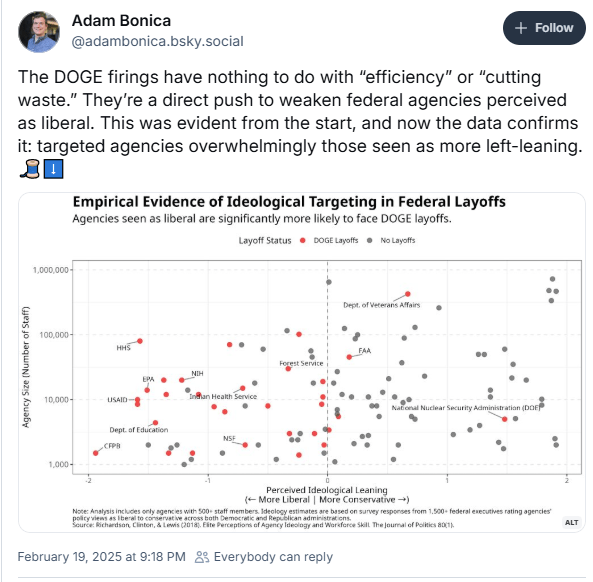
Good thread on targeted attacks
Trump Dismantles Government Fight Against Foreign Influence Operations
GPT Agents
SBIRs
Did not sleep well last night

SBIRs
GPT Agents
Some of the sauce used to make DeepSeek: Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention

GPT Agents
SBIRs

“Cultural Car-ism,” like in my book!
GPT Agents
SBIRs
AI datasets have human values blind spots − new research
LIMO: Less is More for Reasoning
Tasks
Aww, it’s valentine’s day
12:30 Lunch
7:00 Cocktail class
Tasks
GPT Agents
Guardian between 10:00 – 11:00
New hack uses prompt injection to corrupt Gemini’s long-term memory
SBIRs
GPT Agents
Snowed about 5-6 inches last night, so I need to dig out before the “wintry mix” hits around noon
Language Models Use Trigonometry to Do Addition
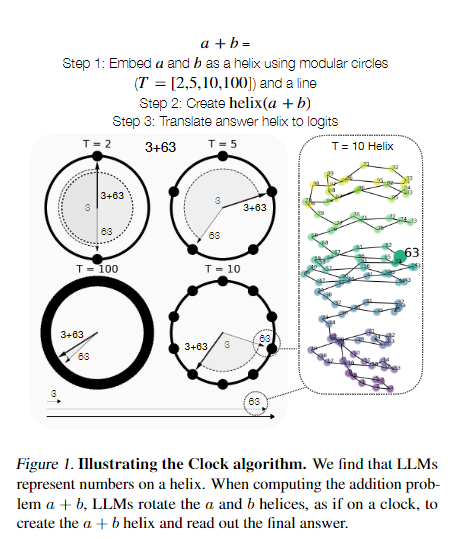
GPT Agents

NOTE: The USA dropped below the “democracy threshold” (+6) on the POLITY scale in 2020 and was considered an anocracy (+5) at the end of the year 2020; the USA score for 2021 returned to democracy (+8). Beginning on 1 July 2024, due to the US Supreme Court ruling granting the US Presidency broad, legal immunity, the USA is noted by the Polity Project as experiencing a regime transition through, at least, 20 January 2025. As of the latter date, the USA is coded EXREC=8, “Competitive Elections”; EXCONST=1 “Unlimited Executive Authority”; and POLCOMP=6 “Factional/Restricted Competition.” Polity scores: DEMOC=4; AUTOC=4; POLITY=0.
The USA is no longer considered a democracy and lies at the cusp of autocracy; it has experienced a Presidential Coup and an Adverse Regime Change event (8-point drop in its POLITY score).
SBIRs

You must be logged in to post a comment.