Today in malicious use of AI: American creating deep fakes targeting Harris works with Russian intel, documents show
- The documents show that John Mark Dougan, who also served in the U.S. Marines and has long claimed to be working independently of the Russian government, was provided funding by an officer from the GRU, Russia’s military intelligence service. Some of the payments were made after fake news sites he created began to have difficulty accessing Western artificial intelligence systems this spring and he needed an AI generator — a tool that can be prompted to create text, photos and video.
And today in Unintended Consequences for vulnerable groups: Can A.I. Be Blamed for a Teen’s Suicide?
- “It’s going to be super, super helpful to a lot of people who are lonely or depressed,” Noam Shazeer, one of the founders of Character.AI, said on a podcast last year.
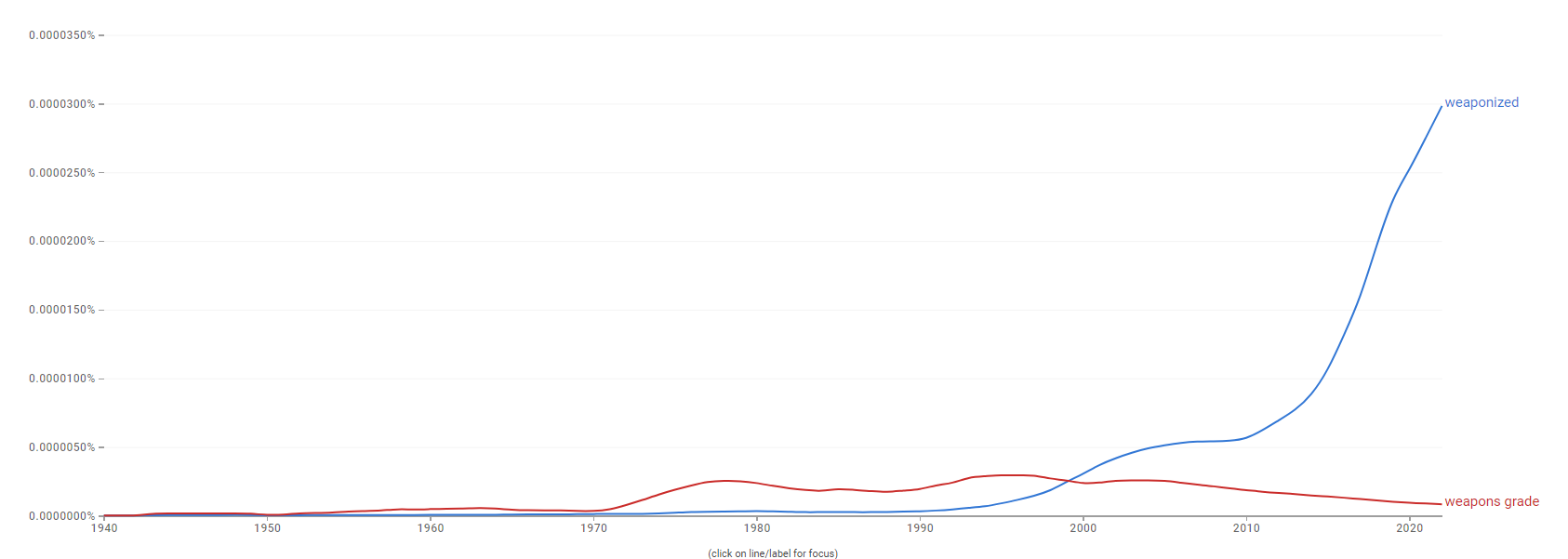
- Now, as a rule, when a headline is in the form of a question, the rule of thumb is “no.” However, this aligns more with what could happen if weapons-grade AI, used in an apparently innocuous app, identified easily manipulatable targets and exploited them. Replika is another example of this sort of accidental effect that could easily be weaponized
10:00 MCC meeting. Turns out that AdAstra might have the capability. I mean, it should!
SBIRs
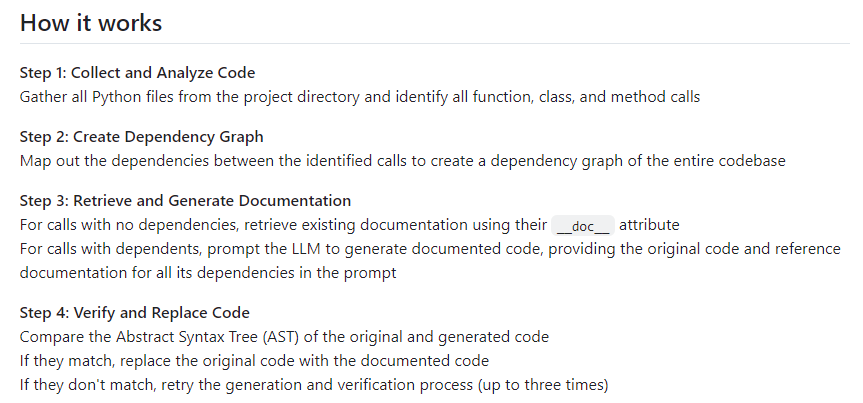
- 9:00 standup
- Wrap up proposal? Made a quad_main.tex fil to hold the chart. Smallest LaTeX ever!
\documentclass[12pt]{article}
\usepackage{style/govstyle}
%opening
\pagestyle{fancy}
\rfoot{UNCLASSIFIED}
\lfoot{\textbf{ADS Quad Chart}}
\renewcommand{\headrulewidth}{0pt}
\begin{document}
\pagenumbering{gobble}
\fbox{\includegraphics[scale=0.8,angle=-90]{assets/Quad-chart.pdf}}
\end{document}
- More tweaks on the proposal – nothing major
- 4:30 book club – fun! Quick!
GPT Agents
- 2:45 meeting – Nope? Wrong link?











You must be logged in to post a comment.