

Really good example of potential sources of AI pollution as it applies to research. Vetting sources may become progressively harder as the AI is able to interpolate across more data. More detail is in the screenshot:
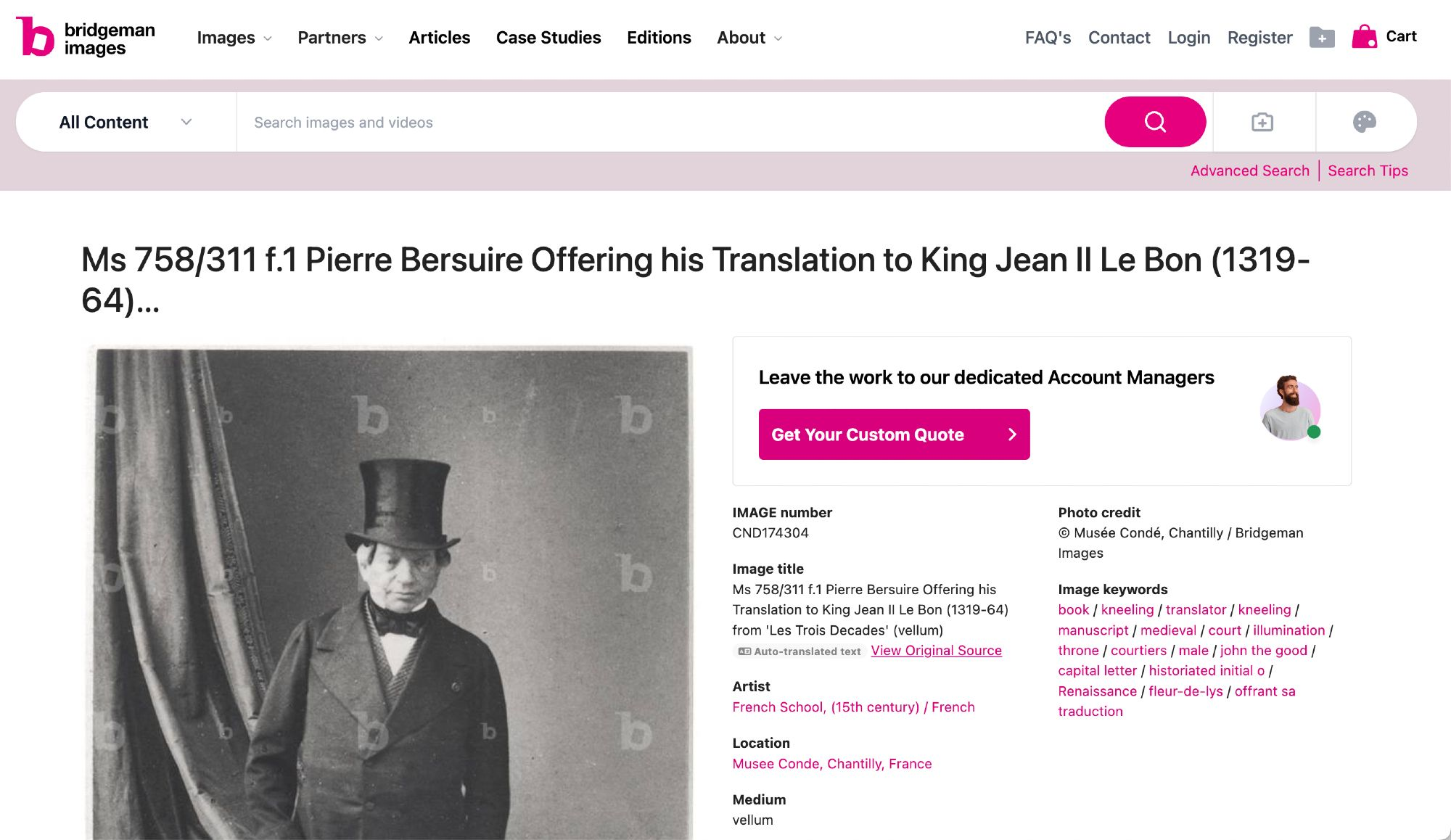
The alt text describes “Screenshot of a Bridgeman Images page, which shows what appears to be a 19th-century photograph of a man in a top hat, but which has appended metadata for a completely different work of art, namely, a late medieval manuscript, which features an image of the author Pierre Bersuire presenting his book to the King of France.“
- The underground exploitation of large language models (LLMs) for malicious services (i.e., Malla) is witnessing an uptick, amplifying the cyber threat landscape and posing questions about the trustworthiness of LLM technologies. However, there has been little effort to understand this new cybercrime, in terms of its magnitude, impact, and techniques. In this paper, we conduct the first systematic study on 212 real-world Mallas, uncovering their proliferation in underground marketplaces and exposing their operational modalities. Our study discloses the Malla ecosystem, revealing its significant growth and impact on today’s public LLM services. Through examining 212 Mallas, we uncovered eight backend LLMs used by Mallas, along with 182 prompts that circumvent the protective measures of public LLM APIs. We further demystify the tactics employed by Mallas, including the abuse of uncensored LLMs and the exploitation of public LLM APIs through jailbreak prompts. Our findings enable a better understanding of the real-world exploitation of LLMs by cybercriminals, offering insights into strategies to counteract this cybercrime.
- Citations: Lin: Malla: Demystifying Real-world Large Language… – Google Scholar
- In the ever-evolving realm of cybersecurity, the rise of generative AI models like ChatGPT, FraudGPT, and WormGPT has introduced both innovative solutions and unprecedented challenges. This research delves into the multifaceted applications of generative AI in social engineering attacks, offering insights into the evolving threat landscape using the blog mining technique. Generative AI models have revolutionized the field of cyberattacks, empowering malicious actors to craft convincing and personalized phishing lures, manipulate public opinion through deepfakes, and exploit human cognitive biases. These models, ChatGPT, FraudGPT, and WormGPT, have augmented existing threats and ushered in new dimensions of risk. From phishing campaigns that mimic trusted organizations to deepfake technology impersonating authoritative figures, we explore how generative AI amplifies the arsenal of cybercriminals. Furthermore, we shed light on the vulnerabilities that AI-driven social engineering exploits, including psychological manipulation, targeted phishing, and the crisis of authenticity. To counter these threats, we outline a range of strategies, including traditional security measures, AI-powered security solutions, and collaborative approaches in cybersecurity. We emphasize the importance of staying vigilant, fostering awareness, and strengthening regulations in the battle against AI-enhanced social engineering attacks. In an environment characterized by the rapid evolution of AI models and a lack of training data, defending against generative AI threats requires constant adaptation and the collective efforts of individuals, organizations, and governments. This research seeks to provide a comprehensive understanding of the dynamic interplay between generative AI and social engineering attacks, equipping stakeholders with the knowledge to navigate this intricate cybersecurity landscape.
- Citations: Falade: Decoding the threat landscape: Chatgpt, fraudgpt,… – Google Scholar
SBIRs
- Meeting in NJ today, so mostly travel
- Realized that I may be able to generate a lot of trajectories really quick by having a base trajectory and an appropriate envelope to contain whatever function (sin wave, random walk, etc) I want to overlay. Train that first, and then have a second model that uses the first to calculate the likely interception point. Kind of what like google does (did?) with predictive search modelling
- Book club
