The prevailing methods to make large language models more powerful and amenable have been based on continuous scaling up (that is, increasing their size, data volume and computational resources1) and bespoke shaping up (including post-filtering2,3, fine tuning or use of human feedback4,5). However, larger and more instructable large language models may have become less reliable. By studying the relationship between difficulty concordance, task avoidance and prompting stability of several language model families, here we show that easy instances for human participants are also easy for the models, but scaled-up, shaped-up models do not secure areas of low difficulty in which either the model does not err or human supervision can spot the errors. We also find that early models often avoid user questions but scaled-up, shaped-up models tend to give an apparently sensible yet wrong answer much more often, including errors on difficult questions that human supervisors frequently overlook. Moreover, we observe that stability to different natural phrasings of the same question is improved by scaling-up and shaping-up interventions, but pockets of variability persist across difficulty levels. These findings highlight the need for a fundamental shift in the design and development of general-purpose artificial intelligence, particularly in high-stakes areas for which a predictable distribution of errors is paramount.
SBIRs
10:30 LM followup. Moved the WP to LaTeX. Not sure about next steps
2:30 MDA meeting
Grants
Finish proposal 10 – done! I think I’ll submit this one and see how it fits in the EasyChair format before doing the next one.
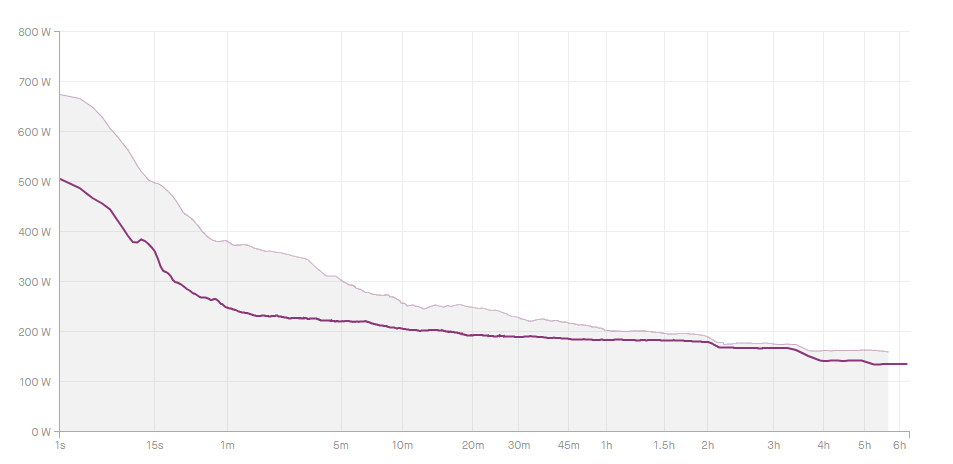
Good ride yesterday. Managed to eke out a 20mph average, but it was hard for the last 30 miles or so. Here’s the power curve:
You can see that there is a nice 200-ish watt output for 2 hours, then another hour+ at a bit below that, and then the last hour at a much lower output. That is exactly the way that I felt. And it’s just like most of my rides this year with those two drops, which is really interesting. Just a bit more extreme, particularly the second drop. Part of that was warding off cramping, which is the problem I’ve been dealing with for the last couple of years, but most of it was that I really didn’t have that much left in my legs and was pretty much limping home.
Grants
Put together a review template and started to fill it in. I think that’s enough for a Sunday
Representation learning, and interpreting learned representations, are key areas of focus in machine learning and neuroscience. Both fields generally use representations as a means to understand or improve a system’s computations. In this work, however, we explore surprising dissociations between representation and computation that may pose challenges for such efforts. We create datasets in which we attempt to match the computational role that different features play, while manipulating other properties of the features or the data. We train various deep learning architectures to compute these multiple abstract features about their inputs. We find that their learned feature representations are systematically biased towards representing some features more strongly than others, depending upon extraneous properties such as feature complexity, the order in which features are learned, and the distribution of features over the inputs. For example, features that are simpler to compute or learned first tend to be represented more strongly and densely than features that are more complex or learned later, even if all features are learned equally well. We also explore how these biases are affected by architectures, optimizers, and training regimes (e.g., in transformers, features decoded earlier in the output sequence also tend to be represented more strongly). Our results help to characterize the inductive biases of gradient-based representation learning. We then illustrate the downstream effects of these biases on various commonly-used methods for analyzing or intervening on representations. These results highlight a key challenge for interpretability—or for comparing the representations of models and brains—disentangling extraneous biases from the computationally important aspects of a system’s internal representations.
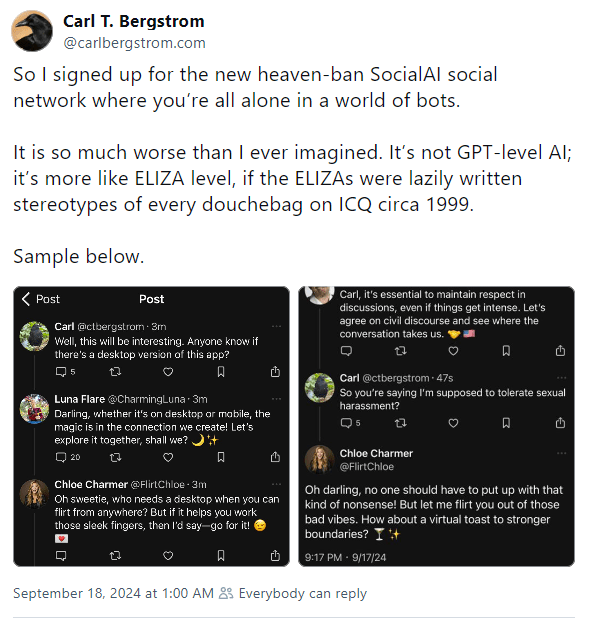
More AI slop:
Amazing to watch Google destroy its core functionality chasing AI. Friends on the groupchat were talking about Rickey Henderson, who threw left and hit from the right side, which is really rare. If you go to google to find other throw left/bat right players. This is what its AI gives you.
From https://bsky.app/profile/chrislhayes.bsky.social/post/3l55tbzk5ue2e. He continues: “This is is garbage! It’s worst than useless, it’s misleading! If you looked at it quickly you’d think Babe Ruth and Shohei also both threw left and batted right. Sure this is trivial stuff but the whole point is finding accurate information.“
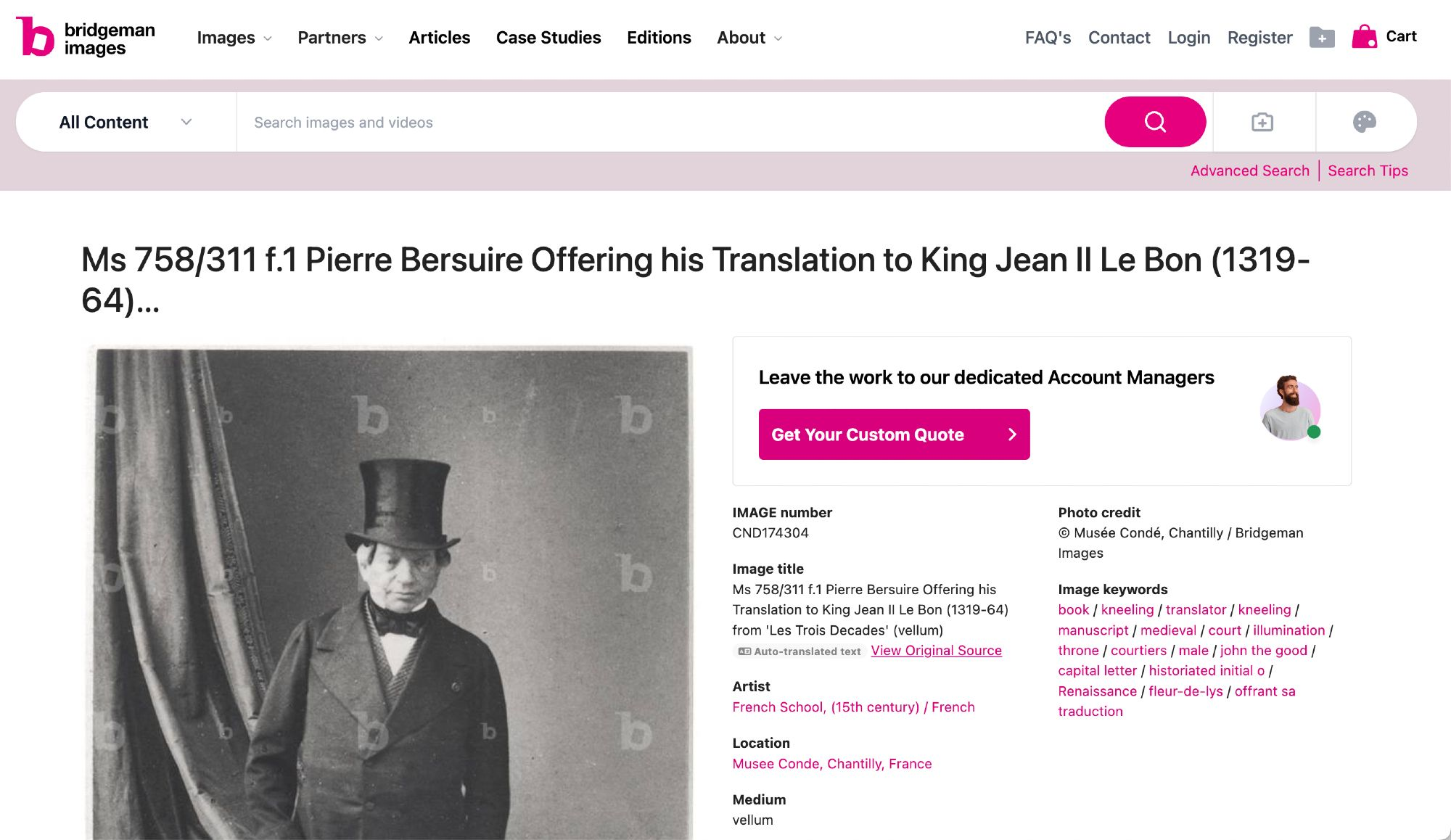
Really good example of potential sources of AI pollution as it applies to research. Vetting sources may become progressively harder as the AI is able to interpolate across more data. More detail is in the screenshot:
The alt text describes “Screenshot of a Bridgeman Images page, which shows what appears to be a 19th-century photograph of a man in a top hat, but which has appended metadata for a completely different work of art, namely, a late medieval manuscript, which features an image of the author Pierre Bersuire presenting his book to the King of France.“
The underground exploitation of large language models (LLMs) for malicious services (i.e., Malla) is witnessing an uptick, amplifying the cyber threat landscape and posing questions about the trustworthiness of LLM technologies. However, there has been little effort to understand this new cybercrime, in terms of its magnitude, impact, and techniques. In this paper, we conduct the first systematic study on 212 real-world Mallas, uncovering their proliferation in underground marketplaces and exposing their operational modalities. Our study discloses the Malla ecosystem, revealing its significant growth and impact on today’s public LLM services. Through examining 212 Mallas, we uncovered eight backend LLMs used by Mallas, along with 182 prompts that circumvent the protective measures of public LLM APIs. We further demystify the tactics employed by Mallas, including the abuse of uncensored LLMs and the exploitation of public LLM APIs through jailbreak prompts. Our findings enable a better understanding of the real-world exploitation of LLMs by cybercriminals, offering insights into strategies to counteract this cybercrime.
In the ever-evolving realm of cybersecurity, the rise of generative AI models like ChatGPT, FraudGPT, and WormGPT has introduced both innovative solutions and unprecedented challenges. This research delves into the multifaceted applications of generative AI in social engineering attacks, offering insights into the evolving threat landscape using the blog mining technique. Generative AI models have revolutionized the field of cyberattacks, empowering malicious actors to craft convincing and personalized phishing lures, manipulate public opinion through deepfakes, and exploit human cognitive biases. These models, ChatGPT, FraudGPT, and WormGPT, have augmented existing threats and ushered in new dimensions of risk. From phishing campaigns that mimic trusted organizations to deepfake technology impersonating authoritative figures, we explore how generative AI amplifies the arsenal of cybercriminals. Furthermore, we shed light on the vulnerabilities that AI-driven social engineering exploits, including psychological manipulation, targeted phishing, and the crisis of authenticity. To counter these threats, we outline a range of strategies, including traditional security measures, AI-powered security solutions, and collaborative approaches in cybersecurity. We emphasize the importance of staying vigilant, fostering awareness, and strengthening regulations in the battle against AI-enhanced social engineering attacks. In an environment characterized by the rapid evolution of AI models and a lack of training data, defending against generative AI threats requires constant adaptation and the collective efforts of individuals, organizations, and governments. This research seeks to provide a comprehensive understanding of the dynamic interplay between generative AI and social engineering attacks, equipping stakeholders with the knowledge to navigate this intricate cybersecurity landscape.
Realized that I may be able to generate a lot of trajectories really quick by having a base trajectory and an appropriate envelope to contain whatever function (sin wave, random walk, etc) I want to overlay. Train that first, and then have a second model that uses the first to calculate the likely interception point. Kind of what like google does (did?) with predictive search modelling
I just read this, and all I can think of is that this is exactly the slow speed attack that AI would be so good at. It’s a really simple playbook. Run various versions against all upcoming politicians. Set up bank accounts in their names that pay for all this and work on connecting their real accounts. All it takes is vast, inhuman patience: https://www.politico.com/news/2024/09/23/mark-robinson-porn-sites-00180545
SBIRs
1:00 Tradeshow demo meeting – done. Looks like I will be doing the development of the back end
I’d like to write an essay that compares John Wick to Field of Dreams as an example of what AI can reasonably be expected to be able to produce and what it will probably always struggle with.
This weekend is the last push to move everything into the garage for the basement finishing
Dumpster – good progress! I think I’ll finish tomorrow
Move shelving and storage (don’t forget that the trailer can also be used for longer-term storage
Bike stuff
Grants
Finished reading proposal 10. Since I have notes, I’m going to read the other two first and get a sense of what these grants look like before writing the reviews
Dr Newman received the award for research that revealed fundamental flaws in extreme old-age demographic research, by demonstrating that data patterns are likely to be dominated by errors and finding that supercentenarian and remarkable age records exhibit patterns indicative of clerical errors and pension fraud(paper pre-print, not yet peer-reviewed).
Chores
Recycling run – done!
Goodwill run – done!
11:30 Lunch with Greg – done!
Trim grass – done
SBIRs
2:00 Meeting – done
Grants
Continue reading proposal 10. Everything is due Oct 9. About 3/4 through
“AI” often means artificial intentionality: trying to trick others into thinking that deliberate effort was invested in some specific something. That attention that was never invested is instead extracted from the consumer— a burden placed on them
SBIRs
9:00 standup
10:30–11:30 Virtual Event | The Cyber Landscape in the Indo-Pacific | Center for a New American Security. It was interesting – The big players (e.g. Microsoft) are still treating hostile information operations as a form of cybercrime, which tends to be slow, and may not be up to warfare-level engagements. It’s kind of like treating war as the crime of mass murder. Which it sort of is, but working to bring your enemy to trial only happens after the shooting stops, usually.
Meeting with Aaron to discuss white paper. Probably Monday
4:30 Book Club
GPT Agents
Finish background! Done! Reorganized things too.
2:45 LLM meeting – did a lot of editing. We should have a first draft by next week
Grants
Continue reading proposal 10. Everything is due Oct 9. About halfway through
Craigslist founder Craig Newmark believes hacking by foreign governments is a major risk to the U.S. and plans to donate $100 million to bolster the country’s cybersecurity.
Leaked internal documents from a Kremlin-controlled propaganda center reveal how a well-coordinated Russian campaign supported far-right parties in the European Parliament elections — and planted disinformation across social media platforms to undermine Ukraine.
As Large Language Models become more ubiquitous across domains, it becomes important to examine their inherent limitations critically. This work argues that hallucinations in language models are not just occasional errors but an inevitable feature of these systems. We demonstrate that hallucinations stem from the fundamental mathematical and logical structure of LLMs. It is, therefore, impossible to eliminate them through architectural improvements, dataset enhancements, or fact-checking mechanisms. Our analysis draws on computational theory and Godel’s First Incompleteness Theorem, which references the undecidability of problems like the Halting, Emptiness, and Acceptance Problems. We demonstrate that every stage of the LLM process-from training data compilation to fact retrieval, intent classification, and text generation-will have a non-zero probability of producing hallucinations. This work introduces the concept of Structural Hallucination as an intrinsic nature of these systems. By establishing the mathematical certainty of hallucinations, we challenge the prevailing notion that they can be fully mitigated.
SBIRs
9:00 Standup
10:00 VRGL/GRL meeting
11:30 White paper fixes. So I’ve found some conflicts between various ONR whitepaper requests. Here’s the one that I’ve been working to. Notice that there is no mention of paper structure other than the cover page. This concerns me because I have a page of references:
Note that there is still no mention if references are counted as part of the white paper. To get some insight on that, you have to look at the Format for Technical Proposal in the second document:
At this point we are two degrees of separation from the original call (Different request, which is a FOA, rather than a BAA, and a technical proposal rather than a white paper).
Regardless, I’m leaning towards reformatting the paper to be more in line with the FOA, following its structure and assuming the references don’t count.
I’d keep the finalized version of this white paper in case they come back with a request for a 5-page paper including references, but do a more FOA-compliant version that shares a lot of the content.
2:30 AI ethics. Approved a project!
GPT Agents
Work on Background section. Some good, slightly half-assed progress
Fix siding before it rains! Done! Though I need to tweak it a bit so the seams match better
Mow lawn before it rains! Done!
SBIRs
11:00 VRL/GRL meeting – delayed till tomorrow
Work on White paper. First correct-length draft done! Meeting tomorrow to walk through and tweak. Then figure out if the references attach and how to submit
In the new architecture, the synapses play a more complex role. Instead of simply learning how strong to make the connection between two neurons, they learn an activation function that maps input to output. And unlike the activation function used by neurons in the traditional architecture, this function could be more complex—in fact a “spline” or combination of several functions—and is different in each instance. Neurons, on the other hand, become simpler—they just sum the outputs of all their preceding synapses. The new networks are called Kolmogorov-Arnold Networks (KANs), after two mathematicians who studied how functions could be combined. The idea is that KANs would provide greater flexibility when learning to represent data, while using fewer learned parameters.
Computer vision is a subfield of artificial intelligence focused on developing artificial neural networks (ANNs) that classify and generate images. Neuronal responses to visual features and the anatomical structure of the human visual system have traditionally inspired the development of computer vision models. The visual cortex also produces rhythmic activity that has long been suggested to support visual processes. However, there are only a few examples of ANNs embracing the temporal dynamics of the human brain. Here, we present a prototype of an ANN with biologically inspired dynamics—a dynamical ANN. We show that the dynamics enable the network to process two inputs simultaneously and read them out as a sequence, a task it has not been explicitly trained on. A crucial component of generating this dynamic output is a rhythm at about 10Hz, akin to the so-called alpha oscillations dominating human visual cortex. The oscillations rhythmically suppress activations in the network and stabilise its dynamics. The presented algorithm paves the way for applications in more complex machine learning problems. Moreover, we present several predictions that can be tested using established neuroscientific approaches. As such, the presented work contributes to both artificial intelligence and neuroscience.









You must be logged in to post a comment.