
Had a thought about terminology, which is probably worth a blog post. LLMs don’t “reason over” data. The prompt “navigates” over it’s previous tokens, under the influence of the model. The analogy is more like how a cell can chase a chemical gradient in a complex environment than how an intelligent being thinks. It’s like Simon’s Ant, MKII.
GPT Agents
- Fixed a typo in ContextText that was found by one of the subjects. We’re at 47!
SBIRS
- MORS ETF. My talk is today!
- Learned about Mistral, which has a nice, small model that might be a nice demo for the MitM email manipulation. It’s on Huggingface, of course

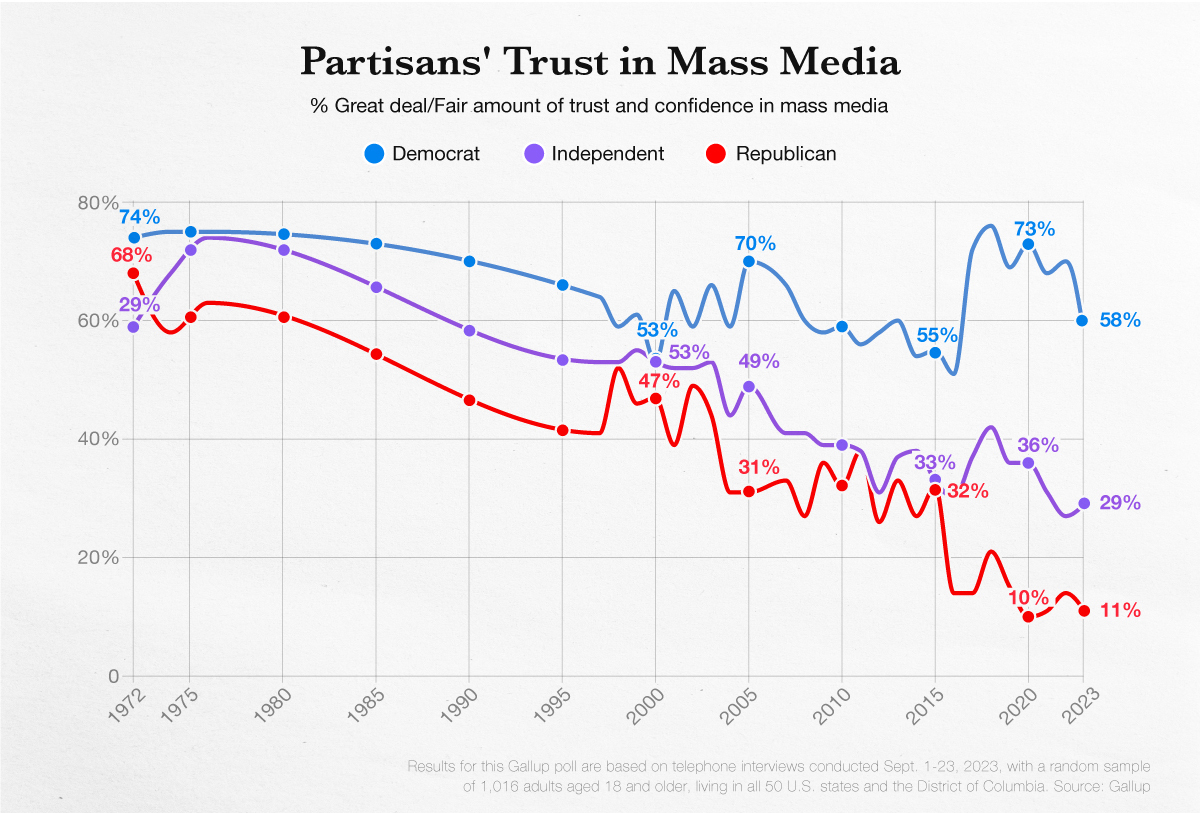
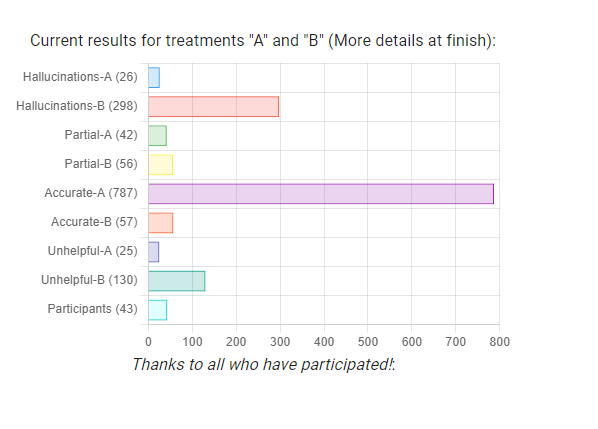

You must be logged in to post a comment.