Whoops, didn’t get to the Lawn Mower on Sunday. Or bills for that matter
Write up the “air pocket essay?” Or maybe as a short story and don’t explain the metaphor.
3:00 Podcast!
SBIRS
- 2:00 MDA
- Got the Perplexity.ai api running their hello world. To make this example work, you have to have your API token attached to an environment variable named “PERPLEXITY_API_KEY. There isn’t much else to the API. Hoping that things improve over time.
# From examples at https://docs.perplexity.ai/reference/post_chat_completions
import requests
import os
import json
url = "https://api.perplexity.ai/chat/completions"
api_key = os.environ.get("PERPLEXITY_API_KEY")
print("API key = {}".format(api_key))
payload = {
"model": "mistral-7b-instruct",
"messages": [
{
"role": "system",
"content": "Be precise and concise."
},
{
"role": "user",
"content": "How many stars are there in our galaxy?"
}
]
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer {}".format(api_key)
}
if api_key == None:
print("No API key")
else:
response = requests.post(url, json=payload, headers=headers)
jobj = json.loads(response.text)
s = json.dumps(jobj, sort_keys=True, indent=4)
print(s)
- Figuring if I want to work on NNM or War Elephants first. Both, I guess?
- Setting up the NNM Overleaf so I have a place to add assets. Done
- Also, this is for the W.E. paper:
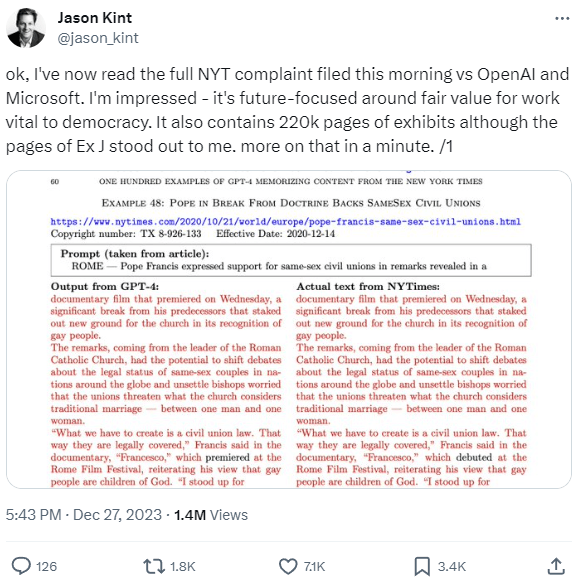
- Exposed Hugging Face API tokens offered full access to Meta’s Llama 2
- The API tokens of tech giants Meta, Microsoft, Google, VMware, and more have been found exposed on Hugging Face, opening them up to potential supply chain attacks.
- Researchers at Lasso Security found more than 1,500 exposed API tokens on the open source data science and machine learning platform – which allowed them to gain access to 723 organizations’ accounts.
- In the vast majority of cases (655), the exposed tokens had write permissions granting the ability to modify files in account repositories. A total of 77 organizations were exposed in this way, including Meta, EleutherAI, and BigScience Workshop – which run the Llama, Pythia, and Bloom projects respectively.
- Reading Future Lens: Anticipating Subsequent Tokens from a Single Hidden State for hints about using activation layers.
- Found a few papers in the references that look interesting
- Locating and Editing Factual Associations in GPT
- We analyze the storage and recall of factual associations in autoregressive transformer language models, finding evidence that these associations correspond to localized, directly-editable computations. We first develop a causal intervention for identifying neuron activations that are decisive in a model’s factual predictions. This reveals a distinct set of steps in middle-layer feed-forward modules that mediate factual predictions while processing subject tokens. To test our hypothesis that these computations correspond to factual association recall, we modify feed-forward weights to update specific factual associations using Rank-One Model Editing (ROME). We find that ROME is effective on a standard zero-shot relation extraction (zsRE) model-editing task, comparable to existing methods. To perform a more sensitive evaluation, we also evaluate ROME on a new dataset of counterfactual assertions, on which it simultaneously maintains both specificity and generalization, whereas other methods sacrifice one or another. Our results confirm an important role for mid-layer feed-forward modules in storing factual associations and suggest that direct manipulation of computational mechanisms may be a feasible approach for model editing. The code, dataset, visualizations, and an interactive demo notebook are available in the supplemental materials.
- Transformer Feed-Forward Layers Are Key-Value Memories – ACL Anthology
- Feed-forward layers constitute two-thirds of a transformer model’s parameters, yet their role in the network remains under-explored. We show that feed-forward layers in transformer-based language models operate as key-value memories, where each key correlates with textual patterns in the training examples, and each value induces a distribution over the output vocabulary. Our experiments show that the learned patterns are human-interpretable, and that lower layers tend to capture shallow patterns, while upper layers learn more semantic ones. The values complement the keys’ input patterns by inducing output distributions that concentrate probability mass on tokens likely to appear immediately after each pattern, particularly in the upper layers. Finally, we demonstrate that the output of a feed-forward layer is a composition of its memories, which is subsequently refined throughout the model’s layers via residual connections to produce the final output distribution.
- All Roads Lead to Rome? Exploring the Invariance of Transformers’ Representations
- Transformer models bring propelling advances in various NLP tasks, thus inducing lots of interpretability research on the learned representations of the models. However, we raise a fundamental question regarding the reliability of the representations. Specifically, we investigate whether transformers learn essentially isomorphic representation spaces, or those that are sensitive to the random seeds in their pretraining process. In this work, we formulate the Bijection Hypothesis, which suggests the use of bijective methods to align different models’ representation spaces. We propose a model based on invertible neural networks, BERT-INN, to learn the bijection more effectively than other existing bijective methods such as the canonical correlation analysis (CCA). We show the advantage of BERT-INN both theoretically and through extensive experiments, and apply it to align the reproduced BERT embeddings to draw insights that are meaningful to the interpretability research. Our code is at this https URL.
- Jump to Conclusions: Short-Cutting Transformers With Linear Transformations
- Transformer-based language models (LMs) create hidden representations of their inputs at every layer, but only use final-layer representations for prediction. This obscures the internal decision-making process of the model and the utility of its intermediate representations. One way to elucidate this is to cast the hidden representations as final representations, bypassing the transformer computation in-between. In this work, we suggest a simple method for such casting, by using linear transformations. We show that our approach produces more accurate approximations than the prevailing practice of inspecting hidden representations from all layers in the space of the final layer. Moreover, in the context of language modeling, our method allows “peeking” into early layer representations of GPT-2 and BERT, showing that often LMs already predict the final output in early layers. We then demonstrate the practicality of our method to recent early exit strategies, showing that when aiming, for example, at retention of 95% accuracy, our approach saves additional 7.9% layers for GPT-2 and 5.4% layers for BERT, on top of the savings of the original approach. Last, we extend our method to linearly approximate sub-modules, finding that attention is most tolerant to this change.
- Visualizing and Interpreting the Semantic Information Flow of Transformers
- Recent advances in interpretability suggest we can project weights and hidden states of transformer-based language models (LMs) to their vocabulary, a transformation that makes them more human interpretable. In this paper, we investigate LM attention heads and memory values, the vectors the models dynamically create and recall while processing a given input. By analyzing the tokens they represent through this projection, we identify patterns in the information flow inside the attention mechanism. Based on our discoveries, we create a tool to visualize a forward pass of Generative Pre-trained Transformers (GPTs) as an interactive flow graph, with nodes representing neurons or hidden states and edges representing the interactions between them. Our visualization simplifies huge amounts of data into easy-to-read plots that can reflect the models’ internal processing, uncovering the contribution of each component to the models’ final prediction. Our visualization also unveils new insights about the role of layer norms as semantic filters that influence the models’ output, and about neurons that are always activated during forward passes and act as regularization vectors.
- It turns out that there is a thing called AlignedUMAP
- It may happen that it would be beneficial to have different UMAP embeddings aligned with each other. There are several ways to go about doing this. One simple approach is to simply embed each dataset with UMAP independently and then solve for a Procrustes transformation on shared points. An alternative approach is to embed the first dataset and then construct an initial embedding for the second dataset based on locations of shared points in the first embedding and then go from there. A third approach, which will provide better alignments in general, is to optimize both embeddings at the same time with some form of constraint as to how far shared points can take different locations in different embeddings during the optimization. This last option is possible, but is not easily tractable to implement yourself (unlike the first two options). To remedy this issue it has been implemented as a separate model class in
umap-learn called AlignedUMAP. The resulting class is quite flexible, but here we will walk through simple usage on some basic (and somewhat contrived) data just to demonstrate how to get it running on data.
GPT Agents
- Send out some reminders – done
- Frame out the new paper. Need to discuss RAG now. And maybe invert the order of the methods and findings?







You must be logged in to post a comment.