Disable the token ring buffer to see the right orientation. Looks like it’s correct:
I think that prompt length (and the ring buffer) might be a good way to map out a space. A short buffer should have less “direction” and should meander more
Projecting the embedding for each layer as the narrative progresses may be helpful
Need to set up an overleaf project to capture this
Need to export to spreadsheets with text and sheets by layer
Write IUI 2024 review (done) and start next paper
3:30 call with Greg and ContextTest – found a bug with CORS and cross-site posting. Told Zach and we will work to fix
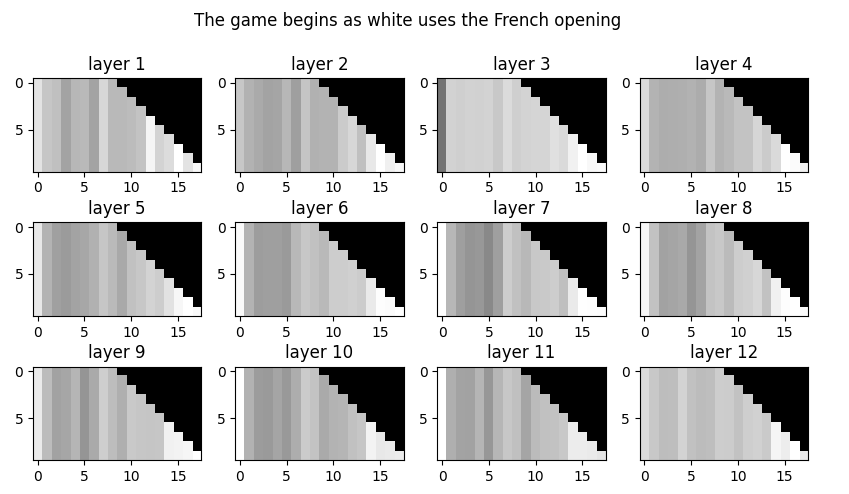
Working on LLM mapping. Got my first view of all the layers as angles from the average working. This is for “the game begins as [white]:
Turns out I was taking the wrong axis of the vectors. This is more what it looks like. Need to work out which axis is which, but this is all the parts working more-or-less correctly:
Research council went well. Good questions with an involved audience
M30 meeting. Late because I got hung up at the gate. Good discussion though. I think there are several phases in roughly this order (put these in an Overleaf project):
RCSNN hierarchy for both systems, varying only by the bottom layers. Top layers could be LLM-driven, which would be fun to evaluate. Probably a lot of context prompting and a GPT-3.5 back end?
Simulator acceleration. There is never enough data to explore outlier states, so adding SimAccel autoencoding -> autoregression would increase the data available for effective training. Because all simulators are base on implicit assumptions, this data will almost certainly be wrong, which will be addressed with…
Simulator cleaning. Like data cleaning, but for data generators. The quality of the generated data can potentially be evaluated by the way that the trained model has “behavior attractors” that can be identified through something like salience analysis. These would be examples of bias, either intentional or unintentional, Imagine that a car simulator that is extended to airplanes. The choice to use Euler angles (rather than Quaternions) for orientation – something that makes sense for a vehicle that navigates in 2D, will completely screw up an airplane doing basic fighter maneuvers such as an Immelmann, Split S, or wingover maneuver. The inability to produce that kind of data would produce artifacts in the model that could either be identified on their own or when compared with other models (e.g. MAST vs. NGTS).
Coevolution of AI and Simulators towards the goal of useful models. Each iteration of training and Simulator cleaning will have impacts on the understanding of the system as a whole. Consideration of this iterative development needs to be part of the process.
System trust. As the AI/ML simulator becomes better, the pressure to deploy it prematurely will increase. To counter this, the UI that is purposefully “low fidelity” or “wireframed” should be used for demonstrations and recordings to indicate the level of progress in the capability of the system.
Get the GPT-2 layer display first pass working
Start slides?
GPT Agents
Clear and test ContextApp one last time before going live! Done
Make IRB changes. I think that it’s basically Data will be stored in a password-protected Dropbox folder. There will be two files. One is a list of names. email addresses, and dates with an associated anonymous string (eg “P1”, “E1”, or “D1”). The other file will contain all experiment data with all names and dates replaced with the substitutes from the other list. Mostly done. Need to change the website text to not mention Supabase and convert items to pdf. – Done
Read IUI paper # 1. Good! Need to write the review
Start on the other slide deck due this week. Get a meeting with Aaron for more context
The War Elephants presentation got nominated for best presentation at MORS. I need to submit “A complete paper (in PDF format), not to exceed 40 pages or 10,000 words including appendices. Please see accompanying formatting guidelines for additional information.” Need to put in the reviewer suggestions and submit by Feb 29 2024.
Roll in changes for the research council slides and distribute.
If you reduce the parameter count in an LLM, it tends to lose recall of facts before it gets worse at learning from examples in the prompt. This holds for parameter count reductions via both pruning and using a smaller dense model.
How does scaling the number of parameters in large language models (LLMs) affect their core capabilities? We study two natural scaling techniques — weight pruning and simply training a smaller or larger model, which we refer to as dense scaling — and their effects on two core capabilities of LLMs: (a) recalling facts presented during pre-training and (b) processing information presented in-context during inference. By curating a suite of tasks that help disentangle these two capabilities, we find a striking difference in how these two abilities evolve due to scaling. Reducing the model size by more than 30\% (via either scaling approach) significantly decreases the ability to recall facts seen in pre-training. Yet, a 60–70\% reduction largely preserves the various ways the model can process in-context information, ranging from retrieving answers from a long context to learning parameterized functions from in-context exemplars. The fact that both dense scaling and weight pruning exhibit this behavior suggests that scaling model size has an inherently disparate effect on fact recall and in-context learning.
The thing is that for sociology, the large pretrained (not finetuned) models will probably be best.
SBIRs
Add a 3 point Research Council story – done
9:00 standup – done
1:00 Dr. Banerjee – done. Fun!
2:00 BMD – done. Did a slide walkthrough and got some action items
2:30 AI Ethics
3:00 AIMSS?
GPT Agents
Thinking more about how to watch the changes of the model under prompting. I think a ring buffer prompt, where the oldest tokens drop off while new ones are added makes the most sense. I checked, and the Llama-2 models do come in pretrained and finetuned (chat) flavors.
Put in a request for Llama-2 access – got it! That was quick. Yep pretrained and chat
Recently, using a powerful proprietary Large Language Model (LLM) (e.g., GPT-4) as an evaluator for long-form responses has become the de facto standard. However, for practitioners with large-scale evaluation tasks and custom criteria in consideration (e.g., child-readability), using proprietary LLMs as an evaluator is unreliable due to the closed-source nature, uncontrolled versioning, and prohibitive costs. In this work, we propose Prometheus, a fully open-source LLM that is on par with GPT-4’s evaluation capabilities when the appropriate reference materials (reference answer, score rubric) are accompanied. We first construct the Feedback Collection, a new dataset that consists of 1K fine-grained score rubrics, 20K instructions, and 100K responses and language feedback generated by GPT-4. Using the Feedback Collection, we train Prometheus, a 13B evaluator LLM that can assess any given long-form text based on customized score rubric provided by the user. Experimental results show that Prometheus scores a Pearson correlation of 0.897 with human evaluators when evaluating with 45 customized score rubrics, which is on par with GPT-4 (0.882), and greatly outperforms ChatGPT (0.392). Furthermore, measuring correlation with GPT-4 with 1222 customized score rubrics across four benchmarks (MT Bench, Vicuna Bench, Feedback Bench, Flask Eval) shows similar trends, bolstering Prometheus’s capability as an evaluator LLM. Lastly, Prometheus achieves the highest accuracy on two human preference benchmarks (HHH Alignment & MT Bench Human Judgment) compared to open-sourced reward models explicitly trained on human preference datasets, highlighting its potential as an universal reward model. We open-source our code, dataset, and model at this https URL.
GPT Agents
Had a good discussion with Jimmy and Shimei yesterday about bias and the chess model. In chess, white always moves first. That’s bias. Trying to get the model to get black to move first is hard and maybe impossible. That, and other chess moves that are more common and less so might be a good way to evaluate how successful treating bias in a model could be, without destroying them.
My personal thought is that there may need to be either “mapping functions” that are attached to the prompt vector that steer the machine in certain ways, or even entire models who’s purpose is to detect and mitigate bias.
Created a Huggingface model card for the chess model to use with map research. I think I’m going to try to build color maps for each layer as tokens are generated and see how they change as a game is generated







You must be logged in to post a comment.