The Biden administration is hunting for malicious computer code it believes China has hidden deep inside the networks controlling power grids, communications systems and water supplies that feed military bases in the United States and around the world, according to American military, intelligence and national security officials.
This quote comes from a Washington Post article on how the Ukraine war is affecting development of AI-powered drones. I think it generalizes more broadly to how disadvantaged groups are driven to embrace alternatives that are outside conventional norms.
Ukraine doesn’t have the ability to fight the much larger Russia. Russia may have issues with corruption and the quality of its weapons, but it has a lot of them. And from the perspective of Ukraine, Russia has an infinite number of soldiers. So many that they can be squandered.
The West is providing Ukraine with enough weapons to survive, but not enough to attack and win decisively. I’ve read analysis where experts say that weapons systems are arriving just about as fast as Ukraine can incorporate them, but the order of delivery is from less-capable to more capable. They have artillery, but no F-16s, for example.
As a result, Ukraine is having to improvise and adapt. Since it is facing an existential risk, it’s not going to be too picky about the ethics of smart weapons. If AI helps in targeting, great. If Russia is jamming the control signals to drones, then AI can take over. There is a coevolution between the two forces, and the result may very well be cheap, effective AI combat drones that are largely autonomous in the right conditions.
Such technology is cheap and adaptable. Others will use it, and it will slowly trickle down to the level that a lone wolf in a small town can order the parts that can inflict carnage on the local school. Or something else. The problem is that the diffusion of technology and its associated risks are difficult to predict and manage. But the line that leads to this kind of tragedy will have its roots in our decision to starve Ukraine of the weapons that it needed to win quickly.
Of course, Ukraine isn’t the only smaller country facing an existential risk. Many low-lying countries, particularly those nearer the equator are facing similar risks from climate change – both from killing heat and sea level rise. Technology – as unproven as combat AI – exists for that too. It’s called Geoengineering.
We’ve been doing geoengineering for decades of course. By dumping megatons of carbon dioxide and other compounds in the atmosphere, we are heating our planet and are now arriving at a tipping point where potential risks are going to become very real and immediate for certain countries. If I were facing the destruction of my country by flooding and heat, I’d be looking at geoengineering very seriously. Particularly since the major economies are not doing much to stop it.
Which means that I expect that we will see efforts like the injection of sulfate aerosols into the upper atmosphere, or cloud brightening, or the spreading of iron or other nutrients to the oceans to increase the amount of phytoplankton to consume CO2. Or something else even more radical. Like Ukraine, these countries have limited budgets and limited options. They will be creative, and not worry too much about the side effects.
It’s a 24/7 technology race without a finish line. The racers are just trying to outrun disaster. And no one knows where that may lead.
SBIRs
9:00 Standup
Finish slide deck
Server stuff
More paper
GPT Agents
Add a “withdraw” page and move the about page to home, then informed consent
In the real world, making sequences of decisions to achieve goals often depends upon the ability to learn aspects of the environment that are not directly perceptible. Learning these so-called latent features requires seeking information about them. Prior efforts to study latent feature learning often used single decisions, used few features, and failed to distinguish between reward-seeking and information-seeking. To overcome this, we designed a task in which humans and monkeys made a series of choices to search for shapes hidden on a grid. On our task, the effects of reward and information outcomes from uncovering parts of shapes could be disentangled. Members of both species adeptly learned the shapes and preferred to select tiles expected to be informative earlier in trials than previously rewarding ones, searching a part of the grid until their outcomes dropped below the average information outcome—a pattern consistent with foraging behavior. In addition, how quickly humans learned the shapes was predicted by how well their choice sequences matched the foraging pattern, revealing an unexpected connection between foraging and learning. This adaptive search for information may underlie the ability in humans and monkeys to learn latent features to support goal-directed behavior in the long run.
SBIRs
Morning meeting with Ron about the intern’s paper writing. Got a charge number! I also need to update the lit review slide deck and do a version for the Adobe paper writing
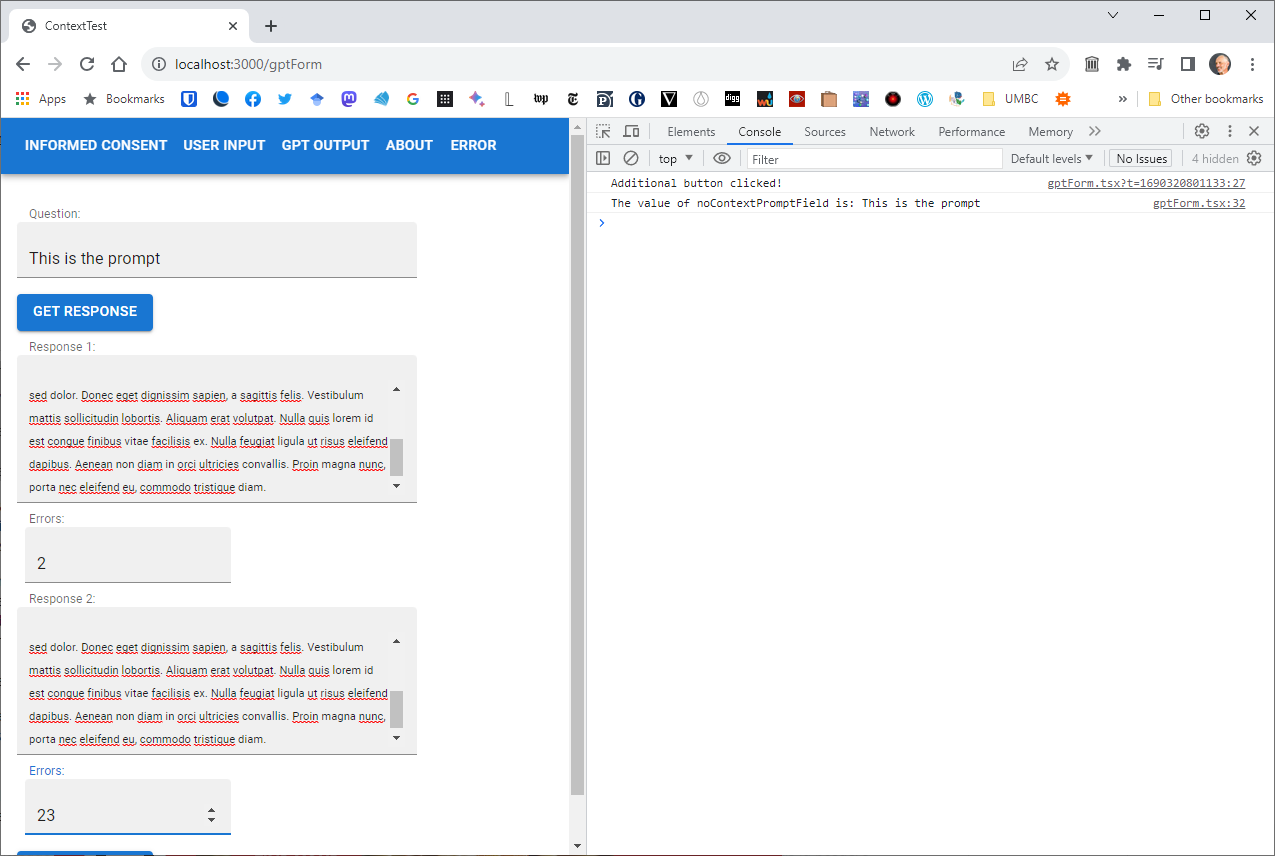
Looking for a straightforward way to build a webapp that has a simple front end (submit email page, then page protected by a GUID that has the IRB statement and the experiment(s)). The last time I did this was in 2015 with Angular. The code still works, amazingly enough, so I could just try reusing that. It looks like I have all the books still, so maybe that’s not the worst answer.
Got ahold of Zach, and we’ll put together something mode modern using Supabase and solid.js. This should be fun!
SBIRs
9:00 standup
11:30 touchpoint
More paper. Good, albeit halting progress. I should be able to finish the analysis section for vignette 1 tomorrow
GPT-3.5 and GPT-4 are the two most widely used large language model (LLM) services. However, when and how these models are updated over time is opaque. Here, we evaluate the March 2023 and June 2023 versions of GPT-3.5 and GPT-4 on four diverse tasks: 1) solving math problems, 2) answering sensitive/dangerous questions, 3) generating code and 4) visual reasoning. We find that the performance and behavior of both GPT-3.5 and GPT-4 can vary greatly over time. For example, GPT-4 (March 2023) was very good at identifying prime numbers (accuracy 97.6%) but GPT-4 (June 2023) was very poor on these same questions (accuracy 2.4%). Interestingly GPT-3.5 (June 2023) was much better than GPT-3.5 (March 2023) in this task. GPT-4 was less willing to answer sensitive questions in June than in March, and both GPT-4 and GPT-3.5 had more formatting mistakes in code generation in June than in March. Overall, our findings shows that the behavior of the same LLM service can change substantially in a relatively short amount of time, highlighting the need for continuous monitoring of LLM quality.
Two of the most significant concerns about the contemporary United States are the erosion of democratic institutions and the increase in rates of depression. The researchers provide evidence linking these phenomena. They use a survey (N=11,517) to show a relationship between COVID-19 conspiracy beliefs and the endorsement of the 2020 election fraud claim as well as voting, in 2022, for gubernatorial candidates who cast doubt on the 2020 election results. The authors further predict and find that the presence of severe depressive symptoms exacerbates these relationships. An increase in depression among COVID-19 conspiracy believers is positively associated with voters casting their ballots for candidates who question the foundation of democratic legitimacy. The results highlight how interventions to address mental health can improve the country’s political health.
SBIRs
JSC meeting at 10:00
GPT Agents
Write up experiment email
Add human-readable text to sources
create or replace view parsed_text_view as
select t.id, t.source, s.text_name, t.parsed_text
from table_parsed_text t
inner join table_source s on t.source = s.id;
We will show in this article how one can surgically modify an open-source model, GPT-J-6B, and upload it to Hugging Face to make it spread misinformation while being undetected by standard benchmarks.
`Scale the model, scale the data, scale the GPU-farms’ is the reigning sentiment in the world of generative AI today. While model scaling has been extensively studied, data scaling and its downstream impacts remain under explored. This is especially of critical importance in the context of visio-linguistic datasets whose main source is the World Wide Web, condensed and packaged as the CommonCrawl dump. This large scale data-dump, which is known to have numerous drawbacks, is repeatedly mined and serves as the data-motherlode for large generative models. In this paper, we: 1) investigate the effect of scaling datasets on hateful content through a comparative audit of the LAION-400M and LAION-2B-en, containing 400 million and 2 billion samples respectively, and 2) evaluate the downstream impact of scale on visio-linguistic models trained on these dataset variants by measuring racial bias of the models trained on them using the Chicago Face Dataset (CFD) as a probe. Our results show that 1) the presence of hateful content in datasets, when measured with a Hate Content Rate (HCR) metric on the inferences of the Pysentimiento hate-detection Natural Language Processing (NLP) model, increased by nearly 12% and 2) societal biases and negative stereotypes were also exacerbated with scale on the models we evaluated. As scale increased, the tendency of the model to associate images of human faces with the `human being’ class over 7 other offensive classes reduced by half. Furthermore, for the Black female category, the tendency of the model to associate their faces with the `criminal’ class doubled, while quintupling for Black male faces. We present a qualitative and historical analysis of the model audit results, reflect on our findings and its implications for dataset curation practice, and close with a summary of our findings and potential future work to be done in this area.




You must be logged in to post a comment.