
They Stormed the Capitol. Their Apps Tracked Them
- While there were no names or phone numbers in the data, we were once again able to connect dozens of devices to their owners, tying anonymous locations back to names, home addresses, social networks and phone numbers of people in attendance. In one instance, three members of a single family were tracked in the data.
Book
- 2:00 Meeting with Michelle
GOES
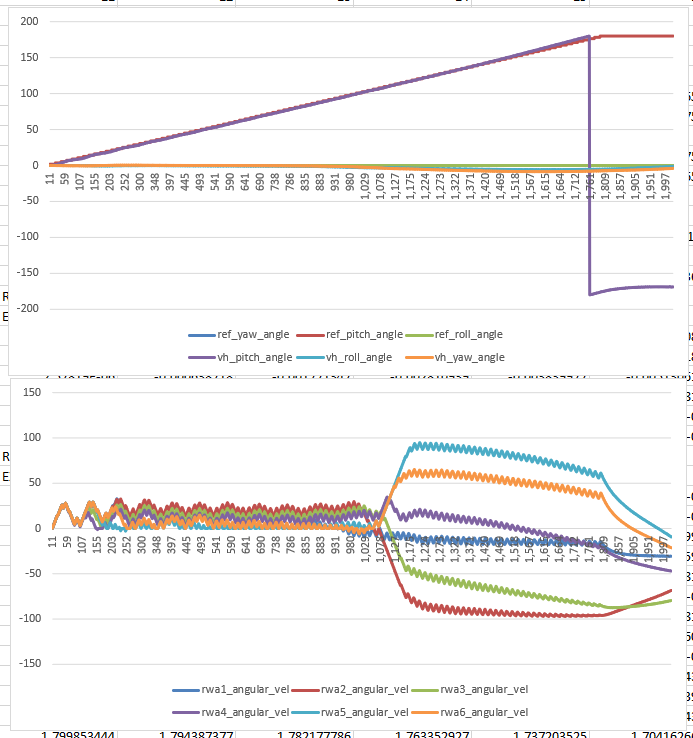
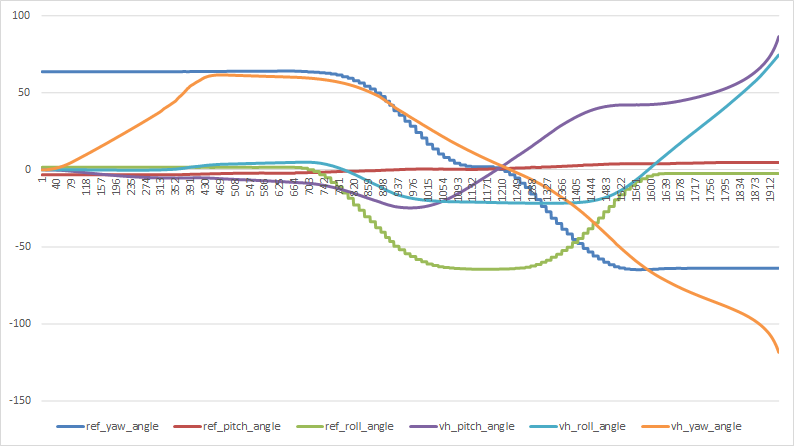
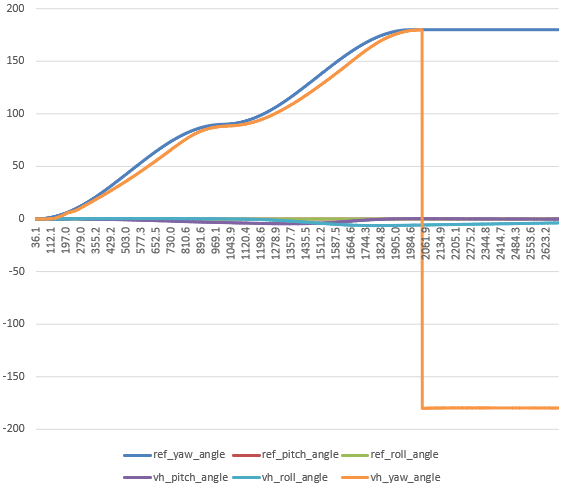
- Run pure pitch/roll/yaw maneuvers
- Yaw – really nice
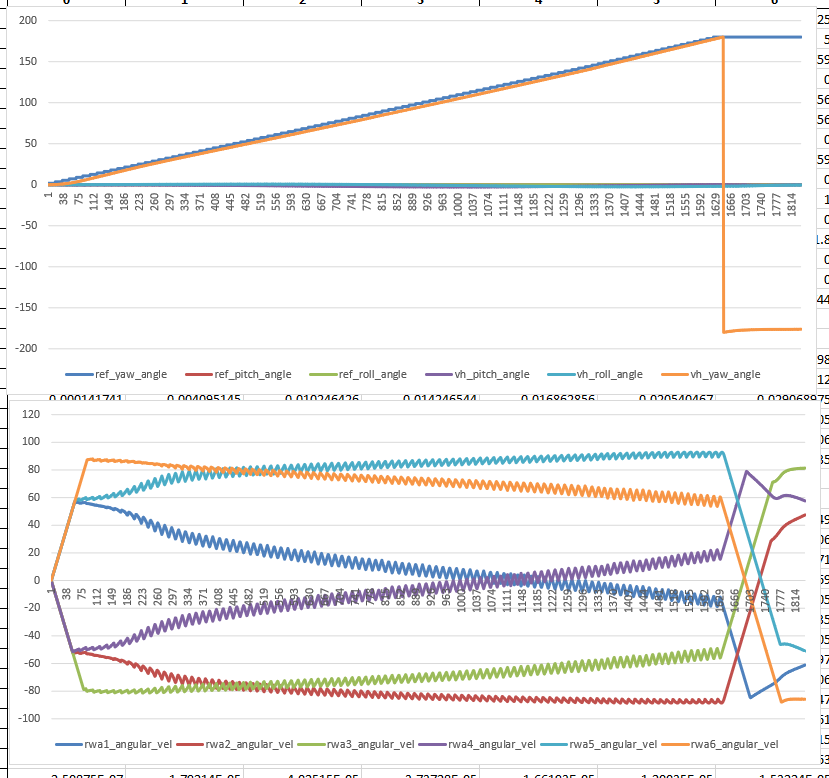
- Roll – WTaF?
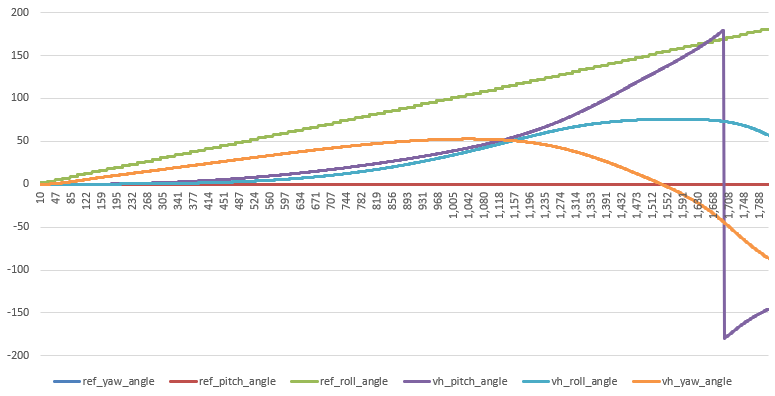
- Pitch – ok?
- 11:00 Meeting with Vadim
GPT Agents
- Install Ecco and try the intro (here in the video, also ranked choices, and token probability) locally, then message him to see if he’d like to discuss maps.
- Have the code running locally (the NVIDIA update worked too!):
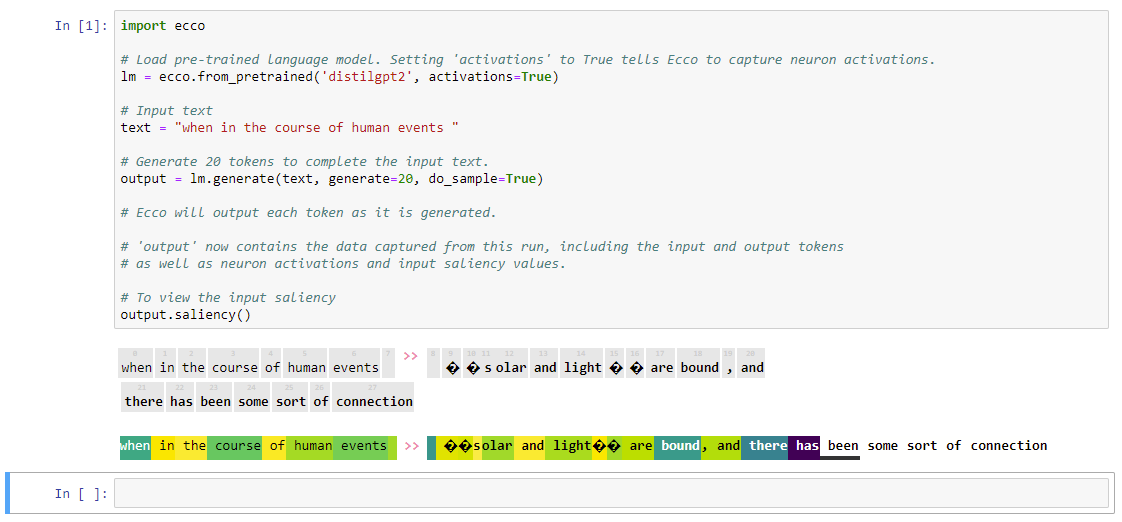
- Messaged Jay Alamar on twitter. Working on setting up a video chat
- Woohoo!
The IJCAI-21 summary reject phase has now ended and we are pleased to inform you that your submission #1558 "Navigating Human Language Models with Synthetic Agents" will enter the full-paper review phase.
- 3:30 Meeting

You must be logged in to post a comment.