
Chuck Yeager died today. He was born in 1923. Here’s what was flying the year he was born:

And here’s what is about to fly as early as tomorrow:

Social cybersecurity: an emerging science
- With the rise of online platforms where individuals could gather and spread information came the rise of online cybercrimes aimed at taking advantage of not just single individuals but collectives. In response, researchers and practitioners began trying to understand this digital playground and the way in which individuals who were socially and digitally embedded could be manipulated. What is emerging is a new scientific and engineering discipline—social cybersecurity. This paper defines this emerging area, provides case examples of the research issues and types of tools needed, and lays out a program of research in this area.
- In today’s high tech world, beliefs opinions and attitudes are shaped as people engage with others in social media, and through the internet. Stories from creditable news sources and finding from science are challenged by actors who are actively engaged in influence operations on the internet. Lone wolfs, and large propaganda machines both disrupt civil discourse, sew discord and spread disinformation. Bots, cyborgs, trolls, sock-puppets, deep fakes, and memes are just a few of the technologies used in social engineering aimed at undermining civil society and supporting adversarial or business agendas. How can social discourse without undue influence persist in such an environment? What are the types of tools and theories needed to support such open discourse?
- Today scientists from a large number of disciplines are working collaboratively to develop these new tools and theories. There work has led to the emergence of a new area of science—social cybersecurity. Herein, this emerging scientific area is described. Illustrative case studies are used to showcase the types of tools and theories needed. New theories and methods are also described.
MORS
- Email to Dr. Carley – done!
- Really nice talk by Dr. Michiel Deskevich at OptTek:
- Information Warfare panel. Started with Gerasimov, which is pretty cool


GPT-2
- 3:30 Meeting
- Need to set up a meeting with Sim to tag-team together a cosine similarity for the GPT embedding.
- I think it can be lazy, and calculate the CS as it goes.
- Save the current distance matrix out as a csv, and read it in the next time, so that it continues to grow
- Can use the training corpora to create a set of words as a baseline matrix
- For words that have more than 1 embedding, have subsequent distance be specified in the matrix as “foo”, “foo1”, … “fooN”. That lets distance calculations be performed between the variants, and also to point back at the correct usage easily
- Need to set up a meeting with Sim to tag-team together a cosine similarity for the GPT embedding.



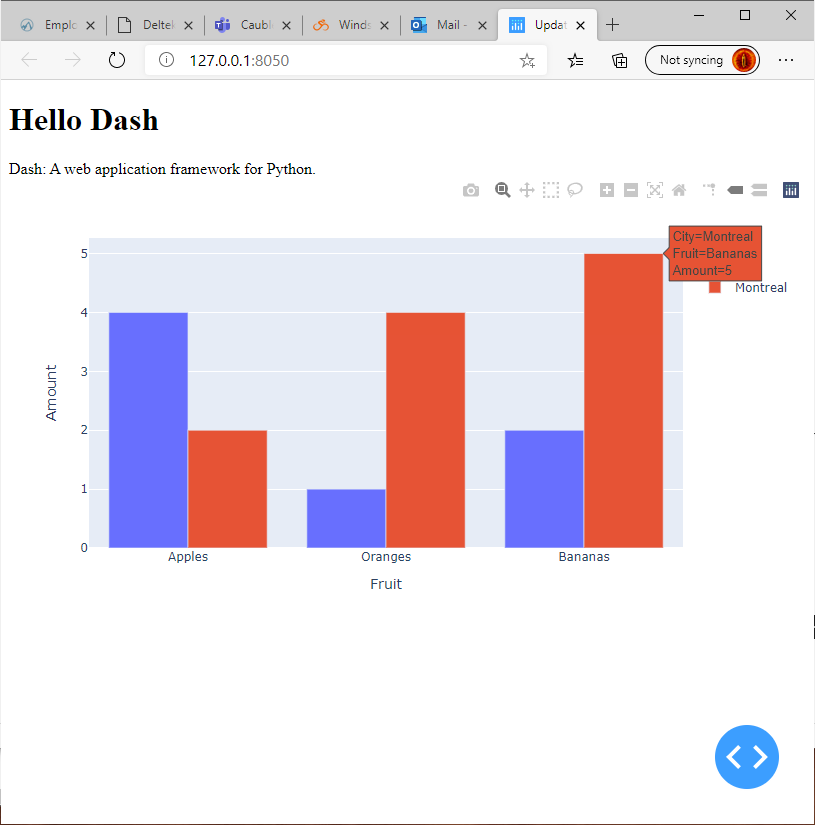
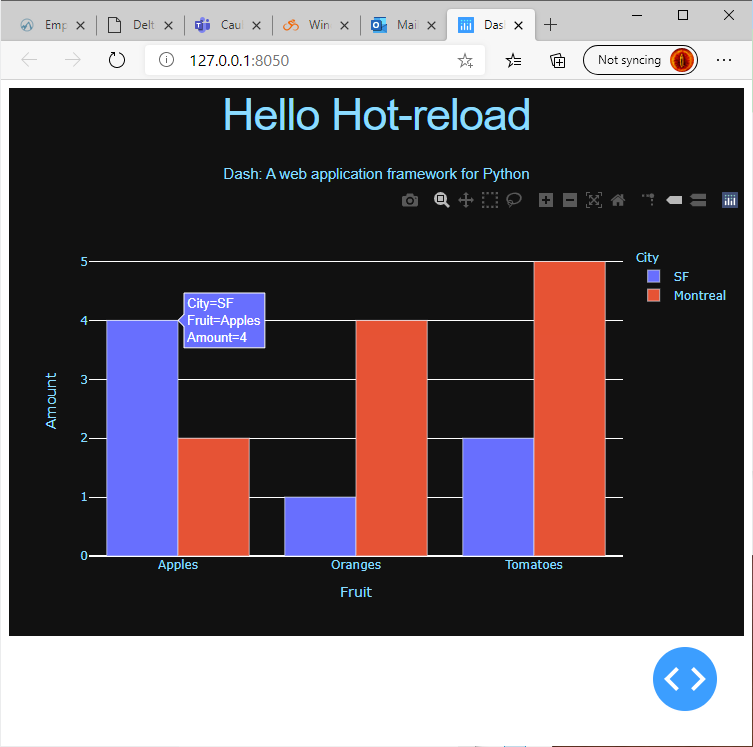




You must be logged in to post a comment.